该项目利用PaddleNLP的文本匹配和对话闲聊模型,结合Wechaty构建微信机器人,为12星座用户提供穿越科幻剧的专属超能力、今日运势查询及闲聊服务。通过阿里云服务器部署,实现微信扫码登录交互,支持星座超能力匹配、运势接口调用和GPT模型闲聊功能。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜



https://www.bilibili.com/video/BV1PL4y1v7nf
https://github.com/27182812/paddle-wechaty-Zodiac
参考https://aistudio.baidu.com/aistudio/projectdetail/1836012
我用的阿里云的云服务器,也可以考虑其他云服务或者是外网可访问的服务器资源。
进入服务器终端,在终端输入以下命令(注:确保输入的端口是对外开放的,WECHATY_TOKEN请填写自己的token)
$ apt update $ apt install docker.io $ docker pull wechaty/wechaty:latest $ export WECHATY_LOG="verbose"$ export WECHATY_PUPPET="wechaty-puppet-wechat"$ export WECHATY_PUPPET_SERVER_PORT="8080"$ export WECHATY_TOKEN="puppet_padlocal_xxxxxx" # 这里输入你自己的token$ docker run -ti --name wechaty_puppet_service_token_gateway --rm -e WECHATY_LOG -e WECHATY_PUPPET -e WECHATY_TOKEN -e WECHATY_PUPPET_SERVER_PORT -p "$WECHATY_PUPPET_SERVER_PORT:$WECHATY_PUPPET_SERVER_PORT" wechaty/wechaty:latest
输入网址: https://api.chatie.io/v0/hosties/xxxxxx (后面的xxxxxx是自己的token),如果返回了服务器的ip地址以及端口号,就说明运行成功了
 简小派
简小派
简小派是一款AI原生求职工具,通过简历优化、岗位匹配、项目生成、模拟面试与智能投递,全链路提升求职成功率,帮助普通人更快拿到更好的 offer。
 123
查看详情
123
查看详情

运行后会输出一大堆东西,找到一个Online QR Code: 的地址点击进去,会出现二维码,微信扫码登录,最终手机上显示桌面微信已登录,即可。
!pip install -U paddlepaddle -i https://mirror.baidu.com/pypi/simple !python -m pip install --upgrade paddlenlp -i https://pypi.org/simple !pip install --upgrade pip !pip install --upgrade sentencepiece !pip install wechaty
文本语义匹配是NLP最基础的任务之一,简单来说就是判断两段文本的语义相似度。应用场景广泛,比如搜索引擎、智能问答、知识检索、信息流推荐等。
为什么要用上这个功能呢,因为如果我们直接基于关键词匹配去判断用户需求的话,可能会出现理解错误的情况。比如如果用户输入“我可讨厌星座了”,但是聊天机器人可能还是会给用户展示星座超能力;如果直接限于关键词“星座”严格匹配的话,那用户如果不小心多输入一个字或者标点符号都不能实现想要的功能,太不友好了。因此本项目利用文本匹配技术来判断用户是否真实需要查看星座未来超能力的功能。
本次项目基于 PaddleNLP,使用百度开源的预训练模型 ERNIE1.0,构建语义匹配模型,来判断 2 个文本语义是否相同。
从头训练一个模型的关键步骤有数据加载、数据预处理、模型搭建、模型训练和评估,具体可参照https://aistudio.baidu.com/aistudio/projectdetail/1972174, 在这我们就直接调用已经训练好的语义匹配模型进行应用。
! wget https://paddlenlp.bj.bcebos.com/models/text_matching/pointwise_matching_model.tar ! tar -xvf pointwise_matching_model.tar
import numpy as npimport osimport timeimport paddleimport paddle.nn.functional as Ffrom paddlenlp.datasets import load_datasetimport paddlenlp# 为了后续方便使用,我们给 convert_example 赋予一些默认参数from functools import partialfrom paddlenlp.data import Stack, Pad, Tupleos.environ["CUDA_VISIBLE_DEVICES"] = "1"tokenizer = paddlenlp.transformers.ErnieTokenizer.from_pretrained('ernie-1.0')import paddle.nn as nn# 我们基于 ERNIE1.0 模型结构搭建 Point-wise 语义匹配网络# 所以此处先定义 ERNIE1.0 的 pretrained_modelpretrained_model = paddlenlp.transformers.ErnieModel.from_pretrained('ernie-1.0')class PointwiseMatching(nn.Layer):
# 此处的 pretained_model 在本例中会被 ERNIE1.0 预训练模型初始化
def __init__(self, pretrained_model, dropout=None):
super().__init__()
self.ptm = pretrained_model
self.dropout = nn.Dropout(dropout if dropout is not None else 0.1) # 语义匹配任务: 相似、不相似 2 分类任务
self.classifier = nn.Linear(self.ptm.config["hidden_size"], 2) def forward(self,
input_ids,
token_type_ids=None,
position_ids=None,
attention_mask=None):
# 此处的 Input_ids 由两条文本的 token ids 拼接而成
# token_type_ids 表示两段文本的类型编码
# 返回的 cls_embedding 就表示这两段文本经过模型的计算之后而得到的语义表示向量
_, cls_embedding = self.ptm(input_ids, token_type_ids, position_ids,
attention_mask)
cls_embedding = self.dropout(cls_embedding) # 基于文本对的语义表示向量进行 2 分类任务
logits = self.classifier(cls_embedding)
probs = F.softmax(logits) return probsdef convert_example(example, tokenizer, max_seq_length=512, is_test=False):
query, title = example["query"], example["title"]
encoded_inputs = tokenizer(
text=query, text_pair=title, max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"] if not is_test:
label = np.array([example["label"]], dtype="int64") return input_ids, token_type_ids, label # 在预测或者评估阶段,不返回 label 字段
else: return input_ids, token_type_idsdef read_text_pair(data_path):
"""Reads data."""
with open(data_path, 'r', encoding='utf-8') as f: for line in f:
data = line.rstrip().split(" ") # print(data)
# print(len(data))
if len(data) != 2: continue
yield {'query': data[0], 'title': data[1]}def predict(model, data_loader):
batch_probs = [] # 预测阶段打开 eval 模式,模型中的 dropout 等操作会关掉
model.eval() with paddle.no_grad(): for batch_data in data_loader:
input_ids, token_type_ids = batch_data
input_ids = paddle.to_tensor(input_ids)
token_type_ids = paddle.to_tensor(token_type_ids) # 获取每个样本的预测概率: [batch_size, 2] 的矩阵
batch_prob = model(
input_ids=input_ids, token_type_ids=token_type_ids).numpy() # print("111",batch_prob)
batch_probs.append(batch_prob)
batch_probs = np.concatenate(batch_probs, axis=0) return batch_probs# 预测数据的转换函数
# predict 数据没有 label, 因此 convert_exmaple 的 is_test 参数设为 Truetrans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=512,
is_test=True)# 预测数据的组 batch 操作# predict 数据只返回 input_ids 和 token_type_ids,因此只需要 2 个 Pad 对象作为 batchify_fnbatchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment_ids): [data for data in fn(samples)]
pretrained_model = paddlenlp.transformers.ErnieModel.from_pretrained("ernie-1.0")
model = PointwiseMatching(pretrained_model)# 刚才下载的模型解压之后存储路径为 ./pointwise_matching_model/ernie1.0_base_pointwise_matching.pdparamsstate_dict = paddle.load("pointwise_matching_model/ernie1.0_base_pointwise_matching.pdparams")
model.set_dict(state_dict)def start():
# 加载预测数据
predict_ds = load_dataset(
read_text_pair, data_path="./predict.txt", lazy=False) # for i in predict_ds:
# print(i)
batch_sampler = paddle.io.BatchSampler(predict_ds, batch_size=32, shuffle=False) # 生成预测数据 data_loader
predict_data_loader = paddle.io.DataLoader(
dataset=predict_ds.map(trans_func),
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True) # 执行预测函数
y_probs = predict(model, predict_data_loader) # 根据预测概率获取预测 label
y_preds = np.argmax(y_probs, axis=1) print(y_preds) return y_preds[-1] # predict_ds = load_dataset(
# read_text_pair, data_path="./predict.txt", lazy=False)
#
# for idx, y_pred in enumerate(y_preds):
# text_pair = predict_ds[idx]
# text_pair["pred_label"] = y_pred
# print(text_pair)if __name__ == '__main__':
start()
from paddlenlp.transformers import GPTChineseTokenizer# 设置想要使用模型的名称model_name = 'gpt-cpm-small-cn-distill'tokenizer = GPTChineseTokenizer.from_pretrained(model_name)import paddlefrom paddlenlp.transformers import GPTForPretraining# 一键加载中文GPT模型model = GPTForPretraining.from_pretrained(model_name)def chat(user_input):
#user_input = "花间一壶酒,独酌无相亲。举杯邀明月,"
# 将文本转为ids
input_ids = tokenizer(user_input)['input_ids'] #print(input_ids)
# 将转换好的id转为tensor
input_ids = paddle.to_tensor(input_ids, dtype='int64').unsqueeze(0) #print(input_ids)
# 调用生成API升成文本
ids, scores = model.generate(
input_ids=input_ids,
max_length=36,
min_length=1,
decode_strategy='sampling',
top_k=5,
num_return_sequences=3) # print(ids)
# print(scores)
generated_ids = ids[0].numpy().tolist() # 使用tokenizer将生成的id转为文本
generated_text = tokenizer.convert_ids_to_string(generated_ids) print(generated_text) return generated_text.rstrip(',')if __name__ == '__main__':
chat("你好啊,宝贝")
import osimport cv2import asyncioimport numpy as npimport paddlehub as hubimport jsonimport urllib.parseimport urllib.requestimport matchimport chatfrom wechaty import (
Contact,
FileBox,
Message,
Wechaty,
ScanStatus,
)
os.environ['WECHATY_PUPPET'] = "wechaty-puppet-service"os.environ['WECHATY_PUPPET_SERVICE_TOKEN'] = "puppet_padlocal_XXXXXXXX" ## 你自己的tokendef chinese_shuxiang(year):
shuxiang_map = { u'鼠': 1900, u'牛': 1901, u'虎': 1902, u'兔': 1903, u'龙': 1904, u'蛇': 1905, u'马': 1906, u'羊': 1907, u'猴': 1908, u'鸡': 1909, u'狗': 1910, u'猪': 1911} for k, v in shuxiang_map.items(): if (year % v % 12) == 0: return kdef xingzuo(month, day):
xingzuo_map = { u'白羊座': [(3, 21), (4, 20)], u'金牛座': [(4, 21), (5, 20)], u'双子座': [(5, 21), (6, 21)], u'巨蟹座': [(6, 22), (7, 22)], u'狮子座': [(7, 23), (8, 22)], u'处女座': [(8, 23), (9, 22)], u'天秤座': [(9, 23), (10, 22)], u'天蝎座': [(10, 23), (11, 21)], u'射手座': [(11, 23), (12, 22)], u'水瓶座': [(1, 20), (2, 18)], u'双鱼座': [(2, 19), (3, 20)]
} for k, v in xingzuo_map.items(): if v[0] <= (month, day) <= v[1]: return k if (month, day) >= (12, 22) or (month, day) <= (1, 19): return u'摩羯座'def super(xingzuo):
xingzuosuper_map = { u'白羊座': "*\n白羊座的人本身就是,比较容易冲动的,是个直肠子的孩子,所以若是穿越科幻剧了,就会拥有*一样的超能力,一发怒就变身的那种,而且能力随着怒气值的增加而更强大。", u'金牛座': "变大变小\n金牛座可爱能吃,胃口很好的他们,经常能把小肚子吃得鼓鼓的,所以若是穿越科幻剧了,就会拥有蚁人那样的,变大变小的能力,可不要小瞧这个超能力哦!", u'双子座': "星爵\n双子座的人,嘴巴很是能说会道的,聊天能把你逗笑,吵架能把你气哭的那种,所以若是穿越科幻剧了,就会拥有像星爵一样的超能力,以神明之躯比肩凡人,“嘴炮”无敌,不过很可爱!", u'巨蟹座': "百发百中\n巨蟹座的人,大多眼神都是很好使的,视力很高,而且对色彩捕捉能力也很强,所以若是穿越科幻剧了,就会拥有像鹰眼一样的超能力,可谓是百发百中的!", u'狮子座': "吹口哨\n狮子座最是刀子嘴豆腐心了,明明就是个特别善良的人,但为了要面子,硬是把自己武装成狠人,所以若是穿越科幻剧了,就会成为勇度那样的超能力,吹吹口哨,就能放倒敌人。", u'处女座': "近身战\n处女座的人是很追求完美的,对自己要求也特别严苛,做任何事情,都必须做到最完美为止,所以若是穿越科幻剧了,就会拥有黑豹那样的超能力,不仅聪明智慧,而且近身战很强,动作行云流水~", u'天秤座': "无限复活\n天秤座的人,若是穿越科幻剧了,就会拥有小贱贱,那样的超能力,哪怕还剩一丢丢细胞,都可以无限复活的那种,因为天秤是最能绝地逢生的人了,他们不会被压垮,是无论如何都相信希望的人。", u'天蝎座': "魔法\n天蝎座的人要是对一件事情很感兴趣的话,那真的会彻夜不睡,去研究那个事情的,所以若是穿越科幻剧了,就会拥有像奇异博士那样的超能力,沉醉于学习魔法,最终也会成为强大的魔法师。", u'射手座': "高超智慧\n射手座的人是非常聪明的哦,逻辑思维能力和发散性思维能力都是数一数二的那种,因此数学特别棒的他们,若是穿越科幻剧了,就会凭借自己的高超智慧,成为像钢铁侠那样的人。", u'摩羯座': "雷神\n摩羯座的人内心信念是非常强大的,认定一件事情了,就会改变的那种,所以若是穿越科幻剧了,就会拥有像雷神那样的超能力,能够召唤雷电,而且正义柔情,是位很好的超能力者。", u'水瓶座': "镭射眼\n水瓶座的人,一般都拥有着一双犀利的眼睛,所以若是穿越科幻剧了,就会拥有像镭射眼那样的超能力,眼睛看到哪,就可以破坏哪里。", u'双鱼座': "心灵感应\n双鱼座的人第六感是非常强烈的,而且与人交往很是细心,天生就会洞察别人的心思,所以若是穿越科幻剧了,就会拥有心灵感应的能力,强者还能掌控别人的思绪呢!"
} return xingzuosuper_map[xingzuo]def img(xingzuo):
xingzuofig_map = { u'白羊座': "1", u'金牛座': "2", u'双子座': "3", u'巨蟹座': "4", u'狮子座': "5", u'处女座': "6", u'天秤座': "7", u'天蝎座': "8", u'射手座': "9", u'摩羯座': "10", u'水瓶座': "11", u'双鱼座': "12"
} # 图片保存的路径
img_path = './imgs/' + xingzuofig_map[xingzuo] +'.png'
return img_pathdef xzyunshi(xingzuo):
xingzuoen_map = { u'白羊座': "aries", u'金牛座': "taurus", u'双子座': "gemini", u'巨蟹座': "cancer", u'狮子座': "leo", u'处女座': "virgo", u'天秤座': "libra", u'天蝎座': "scorpio", u'射手座': "sagittarius", u'摩羯座': "capricorn", u'水瓶座': "aquarius", u'双鱼座': "pisces"
}
url = "http://api.tianapi.com/txapi/star/index"
# 定义请求数据,并且对数据进行赋值
values = {}
values['key'] = 'XXXX' ## 你自己申请的APIKEY
values['astro'] = xingzuoen_map[xingzuo] # 对请求数据进行编码
data = urllib.parse.urlencode(values).encode('utf-8') print(type(data)) # 打印<class 'bytes'>
print(data) # 打印b'status=hq&token=C6AD7DAA24BAA29AE14465DDC0E48ED9'
# 若为post请求以下方式会报错TypeError: POST data should be bytes, an iterable of bytes, or a file object. It cannot be of type str.
# Post的数据必须是bytes或者iterable of bytes,不能是str,如果是str需要进行encode()编码
data = urllib.parse.urlencode(values) print(type(data)) # 打印<class 'str'>
print(data) # 打印status=hq&token=C6AD7DAA24BAA29AE14465DDC0E48ED9
# 将数据与url进行拼接
req = url + '?' + data # 打开请求,获取对象
response = urllib.request.urlopen(req) print(type(response)) # 打印<class 'http.client.HTTPResponse'>
# 打印Http状态码
print(response.status) if response.status == 200:
the_page = response.read()
rsts = eval(the_page.decode("utf-8")) #print(rsts["newslist"])
yunshi = []
yunshi.append('综合指数:' + rsts["newslist"][0]["content"])
yunshi.append('爱情指数:' + rsts["newslist"][1]["content"])
yunshi.append('工作指数:' + rsts["newslist"][2]["content"])
yunshi.append('财运指数:' + rsts["newslist"][3]["content"])
yunshi.append('健康指数:' + rsts["newslist"][4]["content"])
 yunshi.append('幸运颜色:' + rsts["newslist"][5]["content"])
yunshi.append('幸运数字:' + rsts["newslist"][6]["content"])
yunshi.append('贵人星座:' + rsts["newslist"][7]["content"])
yunshi.append('今日概述:' + rsts["newslist"][8]["content"])
finalstr = ""
for i in yunshi:
finalstr += i+'\n'
return finalstrdef match_input(input):
print(input) with open("./predict.txt", "w", encoding="utf-8") as f:
f.write(input + " 查星座\n")
rst = match.start() return int(rst)
userstate = '0'async def on_message(msg: Message):
global userstate print(msg.talker().name) if msg.talker().name == '271828': # print(msg.talker().name)
print("11",userstate) if userstate == '1-1': str = msg.text() print(str)
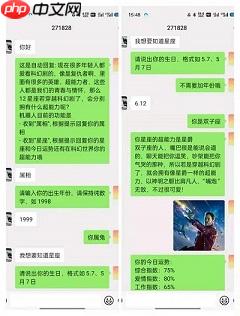
rst = xingzuo(int(str[0]), int(str[2])) await msg.talker().say('你是' + rst)
selfsuper = super(rst) await msg.talker().say('你星座的超能力是' + selfsuper)
imgpath = img(rst)
file_box_xz = FileBox.from_file(imgpath) await msg.talker().say(file_box_xz)
yunshi = xzyunshi(rst) print(yunshi)
userstate = '0'
await msg.say("你的今日运势:\n" + yunshi)
rst = match_input(msg.text()) if rst == 1:
userstate = '1-1'
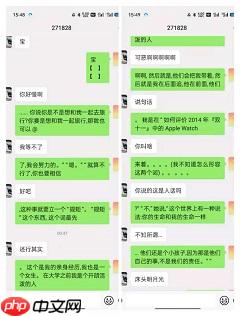
await msg.talker().say('请说出你的生日,格式如5.7、5月7日') await msg.say('不需要加年份哦') else: if msg.text() == 'ding': await msg.say('这是自动回复: dong dong dong') if msg.text() == 'hi' or msg.text() == '你好': await msg.say( '这是自动回复: 现在很多年轻人都爱看科幻剧的,像是复仇者啊,里面有很多的英雄、超能力者,这些人都是我们的青春与情怀,那么12星座若穿越科幻剧了,会分别拥有什么超能力呢?\n机器人目前的功能是\n- 收到"属相", 根据提示回复你的属相\n- 收到"星座", 根据提示回复你的星座和今日运势还有在科幻世界你的超能力哦') if msg.text() == '属相':
userstate = '2-1'
await msg.say('请输入你的出生年份,请保持纯数字,如1998') if userstate == '2-1':
year = msg.text() print(year)
rst = chinese_shuxiang(int(year)) await msg.say('你属' + rst)
userstate = '0'
else:
rst = chat.chat(msg.text()) await msg.say(rst)async def on_scan(
qrcode: str,
status: ScanStatus,
_data,):
print('Status: ' + str(status)) print('View QR Code Online: https://wechaty.js.org/qrcode/' + qrcode)async def on_login(user: Contact):
print(user)async def main():
# 确保我们在环境变量中设置了WECHATY_PUPPET_SERVICE_TOKEN
if 'WECHATY_PUPPET_SERVICE_TOKEN' not in os.environ: print('''
Error: WECHATY_PUPPET_SERVICE_TOKEN is not found in the environment variables
You need a TOKEN to run the Python Wechaty. Please goto our README for details
https://github.com/wechaty/python-wechaty-getting-started/#wechaty_puppet_service_token
''')
bot = Wechaty()
bot.on('scan', on_scan)
bot.on('login', on_login)
bot.on('message', on_message) await bot.start() print('[Python Wechaty] Ding Dong Bot started.')
asyncio.run(main())
yunshi.append('幸运颜色:' + rsts["newslist"][5]["content"])
yunshi.append('幸运数字:' + rsts["newslist"][6]["content"])
yunshi.append('贵人星座:' + rsts["newslist"][7]["content"])
yunshi.append('今日概述:' + rsts["newslist"][8]["content"])
finalstr = ""
for i in yunshi:
finalstr += i+'\n'
return finalstrdef match_input(input):
print(input) with open("./predict.txt", "w", encoding="utf-8") as f:
f.write(input + " 查星座\n")
rst = match.start() return int(rst)
userstate = '0'async def on_message(msg: Message):
global userstate print(msg.talker().name) if msg.talker().name == '271828': # print(msg.talker().name)
print("11",userstate) if userstate == '1-1': str = msg.text() print(str)
rst = xingzuo(int(str[0]), int(str[2])) await msg.talker().say('你是' + rst)
selfsuper = super(rst) await msg.talker().say('你星座的超能力是' + selfsuper)
imgpath = img(rst)
file_box_xz = FileBox.from_file(imgpath) await msg.talker().say(file_box_xz)
yunshi = xzyunshi(rst) print(yunshi)
userstate = '0'
await msg.say("你的今日运势:\n" + yunshi)
rst = match_input(msg.text()) if rst == 1:
userstate = '1-1'
await msg.talker().say('请说出你的生日,格式如5.7、5月7日') await msg.say('不需要加年份哦') else: if msg.text() == 'ding': await msg.say('这是自动回复: dong dong dong') if msg.text() == 'hi' or msg.text() == '你好': await msg.say( '这是自动回复: 现在很多年轻人都爱看科幻剧的,像是复仇者啊,里面有很多的英雄、超能力者,这些人都是我们的青春与情怀,那么12星座若穿越科幻剧了,会分别拥有什么超能力呢?\n机器人目前的功能是\n- 收到"属相", 根据提示回复你的属相\n- 收到"星座", 根据提示回复你的星座和今日运势还有在科幻世界你的超能力哦') if msg.text() == '属相':
userstate = '2-1'
await msg.say('请输入你的出生年份,请保持纯数字,如1998') if userstate == '2-1':
year = msg.text() print(year)
rst = chinese_shuxiang(int(year)) await msg.say('你属' + rst)
userstate = '0'
else:
rst = chat.chat(msg.text()) await msg.say(rst)async def on_scan(
qrcode: str,
status: ScanStatus,
_data,):
print('Status: ' + str(status)) print('View QR Code Online: https://wechaty.js.org/qrcode/' + qrcode)async def on_login(user: Contact):
print(user)async def main():
# 确保我们在环境变量中设置了WECHATY_PUPPET_SERVICE_TOKEN
if 'WECHATY_PUPPET_SERVICE_TOKEN' not in os.environ: print('''
Error: WECHATY_PUPPET_SERVICE_TOKEN is not found in the environment variables
You need a TOKEN to run the Python Wechaty. Please goto our README for details
https://github.com/wechaty/python-wechaty-getting-started/#wechaty_puppet_service_token
''')
bot = Wechaty()
bot.on('scan', on_scan)
bot.on('login', on_login)
bot.on('message', on_message) await bot.start() print('[Python Wechaty] Ding Dong Bot started.')
asyncio.run(main())
以上就是【AI创造营】科幻穿越星座能力者的详细内容,更多请关注其它相关文章!
# git
# python
# red
# b站视频
# 为什么
# gemini
# 百度
# ai
# b站
# 微信
# docker
# 门头沟优化网站建设
# seo主管主要做什么
# 批发行业网站建设营销
# 怎么给网站去做seo
# 贵州互联网推广营销平台
# 辽源关键词优化排名
# 惠州网站建设文案
# 汉阳seo优化
# 游戏网站建设推广文案
# 巴音SEO
# 中文网
# 狮子座
# 巨蟹座
# 白羊座
# 自己的
# 摩羯座
# 超能力
# 的人
# 就会
# 关键词
# tal
# taurus
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
美版贴吧8000小组自爆停摆!拒绝数据被谷歌OpenAI白嫖,CEO被网友骂翻:背刺第三方应用
元宇宙迈入2.0时代,它和生成式人工智能有何关联吗?
为了避免人工智能可能带来的灾难,我们要向核安全学习
走进首家“元宇宙”未来工厂,卡奥斯探知工业之旅出发!
报道称亚马逊正在测试AI生成产品评价摘要
MIT开发“PhotoGuard”技术保护图像免遭恶意AI编辑
字节、网易相继入局,AI之后大厂又找到下一个风口?
昆仑万维与全球领先的元宇宙公司Meta达成商务合作,共同认可昆仑万维在XR领域的技术实力
OpenAI高管:AI能创造新的就业机会 但也会淘汰一些
"探索Meta发布的Quest MR/VR视频录制与拍摄指南"
传Meta 2025年推出首款AR眼镜,采用军用级别材料,计划生产1000台
长宁这家企业在世界人工智能大会上荣获“蓝鼎奖”
让AI助手带您轻松愉快地享受写作之旅
上影节直击 | AI技术降低了短片拍摄门槛?金爵奖评委不赞同
亚马逊确认今年不会举办 re:MARS 机器人和人工智能大会
支持跨语言、人声狗吠互换,仅利用最近邻的简单语音转换模型有多神奇
阿里达摩院发布免费开放100项AI专利许可的动机是什么?
亚太地区 70% 的企业高管正探索生成式 AI 应用或已经进行投资
月薪6万,哪些AI岗位在抢人?
大模型的“黄金搭档”来了!腾讯云正式发布AI原生向量数据库,提供10亿级向量检索能力
金山办公:AI是重要的产品战略之一
京东 AI 大模型官宣 7 月 13 日发布,还有重磅合作
布局智能物联新时代,中国移动“5G+物联网”亮相2025 MWC
7条线路感受智慧美好生活,“2025 世界人工智能大会民营企业社会开放日”主题活动启动
图像生成过程中遭「截胡」:稳定扩散的失败案例受四大因素影响
Unity 内测 Safe Voice 服务,利用 AI 自动识别玩家不当聊天内容
即将到来:AI婚纱设计软件实际测试,人工智能即将开创婚纱设计新纪元
编程已死,AI 当立?教授公开“唱反调”:AI 还帮不了程序员
探索人工智能在居家养老方面的应用
郭帆:AI发展日新月异,或是弯道超车好莱坞的最好机会
出门问问亮相2025世界人工智能大会,展示AI CoPilot解决方案
人工智能自己玩自己
全新小艺搭载AI大模型,有效提升学生和职场人士的工作效率
腾讯企点客服接待与营销分析能力升级!企业操作更高效、人机交互更智能
DreamAvatar数字人在哪里下载
Meta 发布 Voicebox AI 模型:可生成音频信息,用于 NPC 对话等
羊驼家族大模型集体进化!32k上下文追平GPT-4,田渊栋团队出品
人工智能“Aria”现身 Opera浏览器100版本更新:新功能“标签岛”
微软推出 LLaVA-Med AI 模型,可对医学病理案例进行分析
对话式论文阅读工具PaperMate上线,综述细节AI告诉你
用人工智能技术,亚马逊为用户生成产品评论摘要,帮助他们轻松选购
好莱坞面临全面停摆 好莱坞大罢工抵制“AI入侵”
【机智云物联网低功耗转接板】远程环境数据采集探索
人形机器人概念集体爆发,能买吗?
两架海燕号无人机交付中国气象局 助力建设国家级机动气象观测业务
广州团建公司方案 | 绝密飞行 → X-PLANE无人机团建主题团建
谷歌内部正在测试代号为Genesis的AI新闻写作产品
如布AI口袋学习机S12 将亮相综艺节目《好样的!国货》
AI生成会议纪要 百度如流升级推出超级助手、智能编码等功能
盘古大模型3.0正式发布 AI开发正走向新“工业化开发模式”
2025-07-28

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。

 yunshi.append('幸运颜色:' + rsts["newslist"][5]["content"])
yunshi.append('幸运数字:' + rsts["newslist"][6]["content"])
yunshi.append('贵人星座:' + rsts["newslist"][7]["content"])
yunshi.append('今日概述:' + rsts["newslist"][8]["content"])
finalstr = ""
for i in yunshi:
finalstr += i+'\n'
return finalstrdef match_input(input):
print(input) with open("./predict.txt", "w", encoding="utf-8") as f:
f.write(input + " 查星座\n")
rst = match.start() return int(rst)
userstate = '0'async def on_message(msg: Message):
global userstate print(msg.talker().name) if msg.talker().name == '271828': # print(msg.talker().name)
print("11",userstate) if userstate == '1-1': str = msg.text() print(str)
rst = xingzuo(int(str[0]), int(str[2])) await msg.talker().say('你是' + rst)
selfsuper = super(rst) await msg.talker().say('你星座的超能力是' + selfsuper)
imgpath = img(rst)
file_box_xz = FileBox.from_file(imgpath) await msg.talker().say(file_box_xz)
yunshi = xzyunshi(rst) print(yunshi)
userstate = '0'
await msg.say("你的今日运势:\n" + yunshi)
rst = match_input(msg.text()) if rst == 1:
userstate = '1-1'
await msg.talker().say('请说出你的生日,格式如5.7、5月7日') await msg.say('不需要加年份哦') else: if msg.text() == 'ding': await msg.say('这是自动回复: dong dong dong') if msg.text() == 'hi' or msg.text() == '你好': await msg.say( '这是自动回复: 现在很多年轻人都爱看科幻剧的,像是复仇者啊,里面有很多的英雄、超能力者,这些人都是我们的青春与情怀,那么12星座若穿越科幻剧了,会分别拥有什么超能力呢?\n机器人目前的功能是\n- 收到"属相", 根据提示回复你的属相\n- 收到"星座", 根据提示回复你的星座和今日运势还有在科幻世界你的超能力哦') if msg.text() == '属相':
userstate = '2-1'
await msg.say('请输入你的出生年份,请保持纯数字,如1998') if userstate == '2-1':
year = msg.text() print(year)
rst = chinese_shuxiang(int(year)) await msg.say('你属' + rst)
userstate = '0'
else:
rst = chat.chat(msg.text()) await msg.say(rst)async def on_scan(
qrcode: str,
status: ScanStatus,
_data,):
print('Status: ' + str(status)) print('View QR Code Online: https://wechaty.js.org/qrcode/' + qrcode)async def on_login(user: Contact):
print(user)async def main():
# 确保我们在环境变量中设置了WECHATY_PUPPET_SERVICE_TOKEN
if 'WECHATY_PUPPET_SERVICE_TOKEN' not in os.environ: print('''
Error: WECHATY_PUPPET_SERVICE_TOKEN is not found in the environment variables
You need a TOKEN to run the Python Wechaty. Please goto our README for details
https://github.com/wechaty/python-wechaty-getting-started/#wechaty_puppet_service_token
''')
bot = Wechaty()
bot.on('scan', on_scan)
bot.on('login', on_login)
bot.on('message', on_message) await bot.start() print('[Python Wechaty] Ding Dong Bot started.')
asyncio.run(main())
yunshi.append('幸运颜色:' + rsts["newslist"][5]["content"])
yunshi.append('幸运数字:' + rsts["newslist"][6]["content"])
yunshi.append('贵人星座:' + rsts["newslist"][7]["content"])
yunshi.append('今日概述:' + rsts["newslist"][8]["content"])
finalstr = ""
for i in yunshi:
finalstr += i+'\n'
return finalstrdef match_input(input):
print(input) with open("./predict.txt", "w", encoding="utf-8") as f:
f.write(input + " 查星座\n")
rst = match.start() return int(rst)
userstate = '0'async def on_message(msg: Message):
global userstate print(msg.talker().name) if msg.talker().name == '271828': # print(msg.talker().name)
print("11",userstate) if userstate == '1-1': str = msg.text() print(str)
rst = xingzuo(int(str[0]), int(str[2])) await msg.talker().say('你是' + rst)
selfsuper = super(rst) await msg.talker().say('你星座的超能力是' + selfsuper)
imgpath = img(rst)
file_box_xz = FileBox.from_file(imgpath) await msg.talker().say(file_box_xz)
yunshi = xzyunshi(rst) print(yunshi)
userstate = '0'
await msg.say("你的今日运势:\n" + yunshi)
rst = match_input(msg.text()) if rst == 1:
userstate = '1-1'
await msg.talker().say('请说出你的生日,格式如5.7、5月7日') await msg.say('不需要加年份哦') else: if msg.text() == 'ding': await msg.say('这是自动回复: dong dong dong') if msg.text() == 'hi' or msg.text() == '你好': await msg.say( '这是自动回复: 现在很多年轻人都爱看科幻剧的,像是复仇者啊,里面有很多的英雄、超能力者,这些人都是我们的青春与情怀,那么12星座若穿越科幻剧了,会分别拥有什么超能力呢?\n机器人目前的功能是\n- 收到"属相", 根据提示回复你的属相\n- 收到"星座", 根据提示回复你的星座和今日运势还有在科幻世界你的超能力哦') if msg.text() == '属相':
userstate = '2-1'
await msg.say('请输入你的出生年份,请保持纯数字,如1998') if userstate == '2-1':
year = msg.text() print(year)
rst = chinese_shuxiang(int(year)) await msg.say('你属' + rst)
userstate = '0'
else:
rst = chat.chat(msg.text()) await msg.say(rst)async def on_scan(
qrcode: str,
status: ScanStatus,
_data,):
print('Status: ' + str(status)) print('View QR Code Online: https://wechaty.js.org/qrcode/' + qrcode)async def on_login(user: Contact):
print(user)async def main():
# 确保我们在环境变量中设置了WECHATY_PUPPET_SERVICE_TOKEN
if 'WECHATY_PUPPET_SERVICE_TOKEN' not in os.environ: print('''
Error: WECHATY_PUPPET_SERVICE_TOKEN is not found in the environment variables
You need a TOKEN to run the Python Wechaty. Please goto our README for details
https://github.com/wechaty/python-wechaty-getting-started/#wechaty_puppet_service_token
''')
bot = Wechaty()
bot.on('scan', on_scan)
bot.on('login', on_login)
bot.on('message', on_message) await bot.start() print('[Python Wechaty] Ding Dong Bot started.')
asyncio.run(main())