本文介绍经典论文《Holistically-Nested Edge Detection》中的HED模型,这是多尺度端到端边缘检测模型。给出其Paddle实现,包括HEDBlock构建、HED_Caffe模型(对齐Caffe预训练模型)及精简HED模型,还涉及预训练模型加载、预处理、后处理操作及推理过程。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

除了传统的边缘检测算法,当然也有基于深度学习的边缘检测模型
这次就介绍一篇比较经典的论文 Holistically-Nested Edge Detection
其中的 Holistically-Nested 表示此模型是一个多尺度的端到端边缘检测模型
论文:Holistically-Nested Edge Detection
官方代码(Caffe):s9xie/hed
非官方实现(Pytorch): xwjabc/hed
论文中的效果对比图:
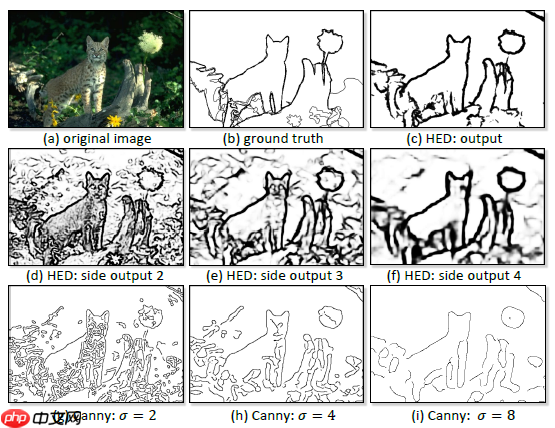
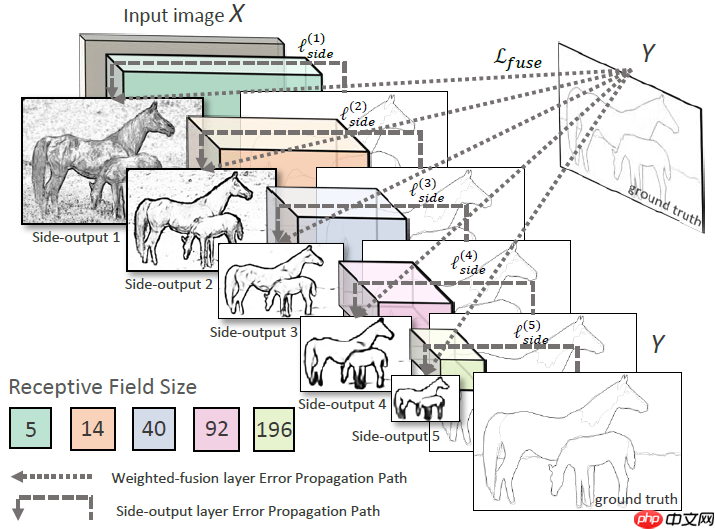
HED 模型包含五个层级的特征提取架构,每个层级中:
使用 VGG Block 提取层级特征图
使用层级特征图计算层级输出
层级输出上采样
最后融合五个层级输出作为模型的最终输出:
通道维度拼接五个层级的输出
1x1 卷积对层级输出进行融合
模型总体架构图如下:
import cv2import numpy as npfrom PIL import Imageimport paddleimport paddle.nn as nn
由一个 VGG Block 和一个 score Conv2D 层组成
使用 VGG Block 提取图像特征信息
使用一个额外的 Conv2D 计算边缘得分
class HEDBlock(nn.Layer):
def __init__(self, in_channels, out_channels, paddings, num_convs, with_pool=True):
super().__init__() # VGG Block
if with_pool:
pool = nn.MaxPool2D(kernel_size=2, stride=2)
self.add_sublayer('pool', pool)
conv1 = nn.Conv2D(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=paddings[0])
relu = nn.ReLU()
self.add_sublayer('conv1', conv1)
self.add_sublayer('relu1', relu) for _ in range(num_convs-1):
conv = nn.Conv2D(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=paddings[_+1])
self.add_sublayer(f'conv{_+2}', conv)
self.add_sublayer(f'relu{_+2}', relu)
self.layer_names = [name for name in self._sub_layers.keys()] # Socre Layer
self.score = nn.Conv2D(in_channels=out_channels, out_channels=1, kernel_size=1, stride=1, padding=0) def forward(self, input):
for name in self.layer_names: input = self._sub_layers[name](input) return input, self.score(input)
本模型基于官方开源的 Caffe 预训练模型实现,预测结果非常接近官方实现。
 简小派
简小派
简小派是一款AI原生求职工具,通过简历优化、岗位匹配、项目生成、模拟面试与智能投递,全链路提升求职成功率,帮助普通人更快拿到更好的 offer。
 123
查看详情
123
查看详情

此代码会稍显冗余,主要是为了对齐官方提供的预训练模型,具体的原因请参考如下说明:
由于 Paddle 的 Bilinea r Upsampling 与 Caffe 的 Bilinear DeConvolution 并不完全等价,所以这里使用 Transpose Convolution with Bilinear 进行替代以对齐模型输出。
r Upsampling 与 Caffe 的 Bilinear DeConvolution 并不完全等价,所以这里使用 Transpose Convolution with Bilinear 进行替代以对齐模型输出。
因为官方开源的 Caffe 预训练模型中第一个 Conv 层的 padding 参数为 35,所以需要在前向计算时进行中心裁剪特征图以恢复其原始形状。
裁切所需要的参数参考自 XWJABC 的复现代码,代码链接
class HED_Caffe(nn.Layer):
def __init__(self,
channels=[3, 64, 128, 256, 512, 512],
nums_convs=[2, 2, 3, 3, 3],
paddings=[[35, 1], [1, 1], [1, 1, 1], [1, 1, 1], [1, 1, 1]],
crops=[34, 35, 36, 38, 42],
with_pools=[False, True, True, True, True]):
super().__init__() '''
Caffe HED model re-implementation in Paddle.
This model is based on the official Caffe pre-training model.
The inference results of this model are very close to the official implementation in Caffe.
Pytorch and Paddle's Bilinear Upsampling are not completely equivalent to Caffe's DeConvolution with Bilinear, so Transpose Convolution with Bilinear is used instead.
In the official Caffe pre-training model, the padding parameter value of the first convolution layer is equal to 35, so the feature map needs to be cropped.
The crop parameters refer to the code implementation by XWJABC. The code link: https://github.com/xwjabc/hed/blob/master/networks.py#L55.
'''
assert (len(channels) - 1) == len(nums_convs), '(len(channels) -1) != len(nums_convs).'
self.crops = crops # HED Blocks
for index, num_convs in enumerate(nums_convs):
block = HEDBlock(in_channels=channels[index], out_channels=channels[index+1], paddings=paddings[index], num_convs=num_convs, with_pool=with_pools[index])
self.add_sublayer(f'block{index+1}', block)
self.layer_names = [name for name in self._sub_layers.keys()] # Upsamples
for index in range(2, len(nums_convs)+1):
upsample = nn.Conv2DTranspose(in_channels=1, out_channels=1, kernel_size=2**index, stride=2**(index-1), bias_attr=False)
upsample.weight.set_value(self.bilinear_kernel(1, 1, 2**index))
upsample.weight.stop_gradient = True
self.add_sublayer(f'upsample{index}', upsample) # Output Layers
self.out = nn.Conv2D(in_channels=len(nums_convs), out_channels=1, kernel_size=1, stride=1, padding=0)
self.sigmoid = nn.Sigmoid() def forward(self, input):
h, w = input.shape[2:]
scores = [] for index, name in enumerate(self.layer_names): input, score = self._sub_layers[name](input) if index > 0:
score = self._sub_layers[f'upsample{index+1}'](score)
score = score[:, :, self.crops[index]: self.crops[index] + h, self.crops[index]: self.crops[index] + w]
scores.append(score)
output = self.out(paddle.concat(scores, 1)) return self.sigmoid(output) @staticmethod
def bilinear_kernel(in_channels, out_channels, kernel_size):
'''
return a bilinear filter tensor
'''
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = np.ogrid[:kernel_size, :kernel_size]
filt = (1 - abs(og[0] - center) / factor) * (1 - abs(og[1] - center) / factor)
weight = np.zeros((in_channels, out_channels, kernel_size, kernel_size), dtype='float32')
weight[range(in_channels), range(out_channels), :, :] = filt return paddle.to_tensor(weight, dtype='float32')
下面就是一个比较精简的 HED 模型实现
与此同时也意味着下面这个模型会与官方实现的模型有所差异,具体差异如下:
3 x 3 卷积采用 padding == 1
采用 Bilinear Upsampling 进行上采样
同样可以加载预训练模型,不过精度可能会略有下降
# class HEDBlock(nn.Layer):# def __init__(self, in_channels, out_channels, num_convs, with_pool=True):# super().__init__()# # VGG Block# if with_pool:# pool = nn.MaxPool2D(kernel_size=2, stride=2)# self.add_sublayer('pool', pool)# conv1 = nn.Conv2D(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1)# relu = nn.ReLU()# self.add_sublayer('conv1', conv1)# self.add_sublayer('relu1', relu)# for _ in range(num_convs-1):# conv = nn.Conv2D(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1)# self.add_sublayer(f'conv{_+2}', conv)# self.add_sublayer(f'relu{_+2}', relu)# self.layer_names = [name for name in self._sub_layers.keys()]# # Socre Layer# self.score = nn.Conv2D(# in_channels=out_channels, out_channels=1, kernel_size=1, stride=1, padding=0)# def forward(self, input):# for name in self.layer_names:# input = self._sub_layers[name](input)# return input, self.score(input)# class HED(nn.Layer):# def __init__(self,# channels=[3, 64, 128, 256, 512, 512],# nums_convs=[2, 2, 3, 3, 3],# with_pools=[False, True, True, True, True]):# super().__init__()# '''# HED model implementation in Paddle.# Fix the padding parameter and use simple Bilinear Upsampling.# '''# assert (len(channels) - 1) == len(nums_convs), '(len(channels) -1) != len(nums_convs).'# # HED Blocks# for index, num_convs in enumerate(nums_convs):# block = HEDBlock(in_channels=channels[index], out_channels=channels[index+1], num_convs=num_convs, with_pool=with_pools[index])# self.add_sublayer(f'block{index+1}', block)# self.layer_names = [name for name in self._sub_layers.keys()]# # Output Layers# self.out = nn.Conv2D(in_channels=len(nums_convs), out_channels=1, kernel_size=1, stride=1, padding=0)# self.sigmoid = nn.Sigmoid()# def forward(self, input):# h, w = input.shape[2:]# scores = []# for index, name in enumerate(self.layer_names):# input, score = self._sub_layers[name](input)# if index > 0:# score = nn.functional.upsample(score, size=[h, w], mode='bilinear')# scores.append(score)# output = self.out(paddle.concat(scores, 1))# return self.sigmoid(output)
def hed_caffe(pretrained=True, **kwargs):
model = HED_Caffe(**kwargs) if pretrained:
pdparams = paddle.load('hed_pretrained_bsds.pdparams')
model.set_dict(pdparams) return model
类型转换
归一化
转置
增加维度
转换为 Paddle Tensor
def preprocess(img):
img = img.astype('float32')
img -= np.asarray([104.00698793, 116.66876762, 122.67891434], dtype='float32')
img = img.transpose(2, 0, 1)
img = img[None, ...] return paddle.to_tensor(img, dtype='float32')
上下阈值限制
删除通道维度
反归一化
类型转换
转换为 Numpy NdArary
def postprocess(outputs):
results = paddle.clip(outputs, 0, 1)
results = paddle.squeeze(results, 1)
results *= 255.0
results = results.cast('uint8') return results.numpy()
model = hed_caffe(pretrained=True)
img = cv2.imread('sample.png')
img_tensor = preprocess(img)
outputs = model(img_tensor)
results = postprocess(outputs)
show_img = np.concatenate([cv2.cvtColor(img, cv2.COLOR_BGR2RGB), cv2.cvtColor(results[0], cv2.COLOR_GRAY2RGB)], 1)
Image.fromarray(show_img)<PIL.Image.Image image mode=RGB size=960x320 at 0x7F3390C85090>代码解释
以上就是边缘检测系列3:【HED】 Holistically-Nested 边缘检测的详细内容,更多请关注其它相关文章!
# ai
# 是一个
# 安装包
# 端到
# 开源
# 一键
# 中文网
# 边缘
# type
# 征信
# git
# 转换为
# 网站seo搜索引擎优化
# 涪陵网站建设电话
# 洛阳营销推广技巧
# 兰州靠谱网站seo优化
# 去地产化营销推广图
# 杨浦营销推广外包公司
# 雅安关键词排名好
# 淮北网站建设价格
# 永春SEO
# 孝义seo优化页面
# 这是
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
研究表明 GPT-4 模型具备自我纠错能力,有望推动 AI 代码进一步商业化
特斯拉 Optimus 人形机器人入驻北美门店,帮助提升汽车销量
生活垃圾智能分类机器人社区展“才能”,征求居民意见
抖音在Android平台获得VR|直播|软件著作权
OpenAI 已全面开放 GPT-3.5 Turbo、DALL-E 及 Whisper API
水路两栖艇、消防灭火机器人……这个展览“黑科技”抢眼
奥比中光子公司和斯坦德机器人深度合作,共同推进新一代激光雷达的研发
小米发布CyberDog2 - 他们的第二代仿生四足机器人展示
AI行业盛会大咖云集!Sam Altam、“AI教父”......一文看懂最新观点
科普:什么是AI大模型
机器人加速!稀土永磁也被带火,持续性如何?
OpenAI CEO 山姆・阿尔特曼呼吁 AI 领域中美应当合作
特斯拉门店可能启动机器人卖车?也许不是你想的那样
金山办公:AI是重要的产品战略之一
为什么很多人对纽约《人工智能招聘法》感到生气?
宇宙探索下一阶段,机器代替人类,AI会在太空探索中取代人类吗?
AI智能室内效果图设计软件效果,确实惊到我了!
13万个注释神经元,5300万个突触,普林斯顿大学等发布首个完整「成年果蝇」大脑连接组
SnapFusion技术大幅提升AI图像生成速度
特斯拉首发人形机器人“擎天柱”亮相世界人工智能大会
人工智能“Aria”现身 Opera浏览器100版本更新:新功能“标签岛”
张朝阳陆川谈AI:大数据模型大幅提升工作效率,ChatGPT冲击最大的是内容创作领域
中国移动主导创立元宇宙产业联盟,包括科大讯飞、芒果TV等在内,共24家成员
人工智能驱动智能建筑会是未来趋势吗?
石头扫拖机器人 G20 618 福利来袭:4999 元,超值配件领到手软
Meta 为打造元宇宙不惜下血本:VR 开发者年薪高达百万美元
花16000元买四款扫拖机器人!科沃斯追觅石头小米谁能笑到最后?
移远通信率先完成多场5G NTN技术外场验证,为卫星物联网应用落地提速
阿里云推出通义万相AI绘画大模型
CREATOR制造、使用工具,实现LLM「自我进化」
DreamAvatar数字人在哪里下载
套娃不可取:研究人员证实用AI生成的结果训练AI将导致模型退化
业内领先 四川大学华西第四医院甲状腺乳腺外科成功进入手术机器人时代
鸿蒙智能座舱的AI大模型革新,引领智能座舱领域的变革吗?
调查显示:实际上没有那么多人在用 ChatGPT
Meta 发布 Voicebox AI 模型:可生成音频信息,用于 NPC 对话等
用人工智能技术,亚马逊为用户生成产品评论摘要,帮助他们轻松选购
人工智能改变网络安全和用户体验的三种方式
盘古大模型3.0正式发布 AI开发正走向新“工业化开发模式”
华为小艺AI助手将实现强大的大模型能力
NTU、上海AI Lab整理300+论文:基于Transformer的视觉分割最新综述出炉
华为云天筹AI求解器荣获世界人工智能大会最高奖
小岛秀夫不反对使用AI 但认为人类应该凌驾于AI
周鸿祎:用超级AI实现室温超导和核聚变,实现能源自由
猿力科技入选北京市通用人工智能产业创新伙伴计划
人手一部「*」!视频版Midjourney免费可用,一句话秒生酷炫大片惊呆网友
乐天派AI桌面机器人提供的正能量情绪价值直接拉满,妥妥的治愈系
讯飞星火大模型实现升级 助力通用人工智能人才培养
央视报道!星纪魅族集团车载人机交互技术成世界移动通信大会焦点
杀入生成式AI的亚马逊云科技,能否再次生成未来?
2025-07-18

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
