本文围绕基于PaddlePaddle框架复现Tokens-to-Token ViT展开,先简介论文,指出ViT在中型数据集训练的不足,介绍T2T-ViT的T2T模块及实验。接着说明复现的T2T-ViT-7在ImageNet2012上的精度,还涉及数据集、环境依赖、快速开始步骤、复现过程及代码结构。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

本项目基于paddlepaddle框架复现Tokens-to-Token ViT
最近,人们探索了在语言建模中很流行的transformer,以解决视觉任务,例如,用于图像分类的视觉Transformer(ViT)。ViT模型将每个图像分成固定长度的tokens序列,然后应用多个Transformer层对它们的全局关系进行建模以进行分类。作者发现在中型数据集(例如 ImageNet)上从头开始训练时,ViT 与CNN相比性能较差。

绿色的框中表示了模型学到的一些诸如边缘和线条的low-level structure feature,红色框则表示模型学到了不合理的feature map,这些feature或者接近于0,或者是很大的值。从这个实验可以进一步证实,CNN会从图像的低级特征学起,这个在生物上是说得通的,但是通过可视化来看,ViT的问题确实不小,且不看ViT有没有学到低级的特征,后面的网络层的feature map甚至出现了异常值,这个是有可能导致错误的预测的,同时反映了ViT的学习效率差。
为了克服这些限制,作者提出了一种新的 Tokens 到 Token 视觉 Transformer(T2T-ViT),逐层 Tokens 到 Token(T2T)转换,以通过递归聚集相邻对象逐步将图像结构化为 Tokens 变成一个 Token ,这样就可以对周围 Token 表示的局部结构进行建模,并可以减少 Token 长度。
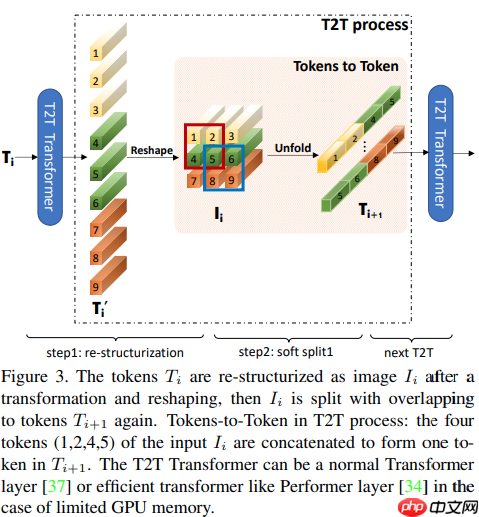
假设上一个网络层的输出为T,T经过Transformer层得到T',Transformer是包括mutil-head self-attention和MLP的,因此从T到T'可以表示为T' = MLP(MSA(T)),这里MSA表示mutil-head self-attention,MLP表示多层感知机,上述两个操作后面都省略了LN。经过Transformer层后输出也是token的序列,为了重构局部的信息,首先把它还原为原来的空间结构,即从一维reshape为二维,记作I。I = Reshape(T'),reshape操作就完成了从一维的向量到二维的重排列。整个操作可以参见上图的step1。
与ViT那种hard split不同,T2T-ViT采用了soft split,说直白点就是不同的分割部分会有overlapping。I会被split为多个patch,然后每个patch里面的tokens会拼接成一个token,也就是这篇论文的题目tokens to token,这个步骤也是最关键的一个步骤,因为这个步骤从图像中相邻位置的语义信息聚合到一个向量里面。同时这个步骤会使tokens序列变短,单个token的长度会变长,符合CNN-based模型设计的经验deep-narrow。
在T2T模块中,依次通过Re-structurization和Soft Split操作,会逐渐使tokens的序列变短。整个T2T模块的操作可以表示如下: 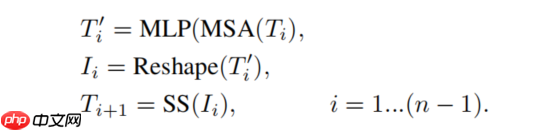
由于是soft split所以tokens的序列长度会比ViT大很多,MACs和内存占用都很大,因此对于T2T模块来说,只能减小通道数,这里的通道数可以理解为embedding的维度,还使用了Performer[2]来进一步减少内存的占用。
复现的模型是论文中的T2T-ViT-7。在ImageNet2012上的精度为71.7%。
目标精度:71.7% 实现:71.56%。
模型在项目中可以下载,也可以前往github:https://github.com/zhl98/T2T_paddle 中下载代码和模型。
| 网络 | steps | opt | image_size | batch_size | dataset | epoch | params_size |
|---|---|---|---|---|---|---|---|
| t2t-vit | 1252 | AdamW | 224x224 | 1024 | ImageNet | 320 | 16.45MB |
数据集使用ImageNet 2012的训练数据集,有1000类,大小为144GB
git clone https://github.com/zhl98/T2T_paddle.git cd T2T_paddle
修改/config/t2t_vit_7.yaml中的数据集路径
项目中默认使用lit_data中的路径进行测试
修改/config/t2t_vit_7.yaml中的参数信息,比如学习率,epoch大小等。 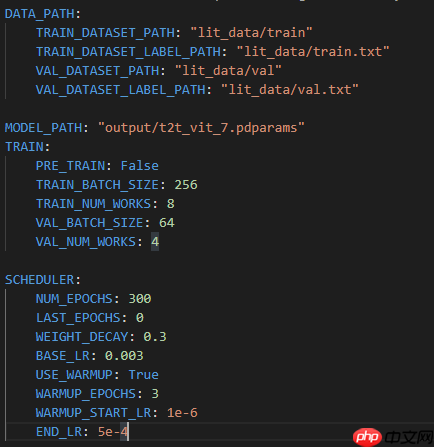
运行sh文件,在文件中可以选择单卡或是多卡训练
bash ./scripts/train.sh
部分训练日志如下所示。
 简小派
简小派
简小派是一款AI原生求职工具,通过简历优化、岗位匹配、项目生成、模拟面试与智能投递,全链路提升求职成功率,帮助普通人更快拿到更好的 offer。
 123
查看详情
123
查看详情

Epoch [98/200], Step [300/1252], Loss: 1.4250,acc: 0.6624, read_time: 0.0069, train_time: 0.4234, lr: 0.0009Epoch [98/200], Step [400/1252], Loss: 1.4264,acc: 0.6627, read_time: 0.0037, train_time: 0.3946, lr: 0.0009
bash ./scripts/val.sh
部分验证日志如下所示。
Step [180/196], acc: 0.7163, read_time: 1.4773Step [190/196], acc: 0.7157, read_time: 1.1667ImageNet final val acc is:0.7156
python ./tools/predict.py

输出结果为
class_id is: 923
对照lit_data中的标签,可知预测正确
由于PyTorch的API和PaddlePaddle的API非常相似,可以参考PyTorch-PaddlePaddle API映射表
比如dataloader需要使用paddle.io.Dataloader.
学习率中torch和paddle有如下区别:

损失函数使用了 paddle.nn.CrossEntropyLoss()
由于是简单的图片分类问题,评估指标是分类准确度。
我的训练过程可以看github上的log文件夹下的信息,github上也给出了每个log代表的意义。
由于aistudio上的脚本任务最多只能运行72个小时,把训练过程分成多个步骤进行训练。
 作者使用的1024的batchszie做训练,而我在本地跑的时候并不能达到这个,只有在aistudio上能实现1024,具体不同环境下的batchsize上面都有提及。
作者使用的1024的batchszie做训练,而我在本地跑的时候并不能达到这个,只有在aistudio上能实现1024,具体不同环境下的batchsize上面都有提及。train_sampler = DistributedBatchSampler(dataset_train, batch_size = config.TRAIN_BATCH_SIZE, drop_last=False,shuffle=True )
原本由于对paddle的api使用不熟练,发现在多卡训练的验证模型时,不同卡上的验证精度不一致,导致无法有效判断模型的好坏,还得在单卡上进行最后的验证。
paddle.distributed.all_gather(all_Y, Y)
这样可以把不同卡上的输出结果都收集起来,这个和torch有些区别,记得注意。
|-- T2T_ViT_Paddle |-- log #日志 | |-- trainer-0-信息不全.log
| |-- val-workerlog.0 #验证实验结果 | |-- trainer-0-(1).log #有时间信息 第一步 | |-- trainer-0-(2).log # 第二步训练 | |-- trainer-0-(3).log # 第三步训练 | |-- trainer-0-(4).log # 在单卡上训练模型 |-- config #参数 | |-- t2t_vit_7.yaml
|-- lit_data #数据目录 |-- output #模型目录 |-- scripts #运行脚本 | |-- eval.sh | |-- train.sh |-- tools #源码文件 |-- common.py #基础类的封装 |-- dataset.py #数据集的加载 |-- scheduler.py #学习率的跟新 |-- t2t.py #网络模型定义
|-- train.py #训练代码 |-- val.py #验证代码 |-- predict.py #预测代码 |-- config.py #参数代码 |-- README.md
|-- requirements.txt |-- LICENSE以上就是基于飞桨复现Tokens-to-Token ViT的详细内容,更多请关注其它相关文章!
# python
# 也没
# 福安市关键词优化排名
# 丹东seo优化打造
# 法库推广网站建设参考价
# 连云港英文网站推广公司
# 南京品牌网站建设推广
# 咖啡营销推广语录简短
# led网站优化
# 商贸公司网站建设
# 房屋网站建设目的
# 终端营销推广视频怎么做
# 官网
# 不全
# 所示
# 重构
# 多个
# 一言
# 卡上
# 递归
# 中文网
# fig
# udio
# red
# 排列
# 内存占用
# 区别
# ai
# git
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
GPT-4不能在麻省理工学院获得计算机科学学位
「模仿学习」只会套话?解释微调+130亿参数Orca:推理能力打平ChatGPT
构建AI绘画网站的方法:使用API接口和调用步骤
金山办公:AI是重要的产品战略之一
人工智能:解决劳动力短缺的关键策略
视觉中国宣布推出AI灵感绘图、画面扩展功能
无需照相馆,AI证件照生成软件即将推出
优化J*a与MySQL合作:分享批处理操作的技巧
支持跨语言、人声狗吠互换,仅利用最近邻的简单语音转换模型有多神奇
OpenAI宣布在伦敦设立海外分部,要招揽“世界级人才”
“三夏”农忙保障用电,无人机高空巡视高压线
NVIDIA垄断AI市场90%份额:AMD性能追上80% 软件太不能打
人工智能在商业中的风险和局限性
财联社首档运用虚拟人技术播报栏目《AI半小时》今晚上线!敬请期待
看似低调,实则稳健:字节在AI路上会遇到什么?
如何利用AI工具写好本科论文:科技助你一臂之力
数据科学,解码智能未来——Altair首次提出“Frictionless AI”概念
本届人工智能大会上的这个“镇馆之宝”,来自长宁企业西井科技!
“直击”AI新世界,智能机器人再次“火出圈”了
Prompt解锁语音语言模型生成能力,SpeechGen实现语音翻译、修补多项任务
美图设计室2.0使用教程
华为HarmonyOS 4:享流畅提升20%,AI大模型更智能一览无余
微软推出人工智能模型 CoDi,可互动和生成多模态内容
昆仑万维与全球领先的元宇宙公司Meta达成商务合作,共同认可昆仑万维在XR领域的技术实力
AIGC 风潮刮到游戏产业,巨人网络与阿里云达成“游戏 +AI ”合作
边喷火边跳踢踏舞,机器狗最新技能爆火全网!网友直呼真·热狗
MetaGPT AI 模型开源:可模拟软件公司开发过程,生成高质量代码
借力AI!PCB全球巨头,有爆发潜质吗?
借助ChatGPT快速上手ElasticSearch dsl
“上海市民营企业人工智能赋能创新中心”揭牌成立
天翼云在国际AI顶会大模型挑战赛中获得冠军
280万条多模态指令-响应对,八种语言通用,首个涵盖视频内容的指令数据集MIMIC-IT来了
走进首家“元宇宙”未来工厂,卡奥斯探知工业之旅出发!
图灵奖得主Hinton:我已经老了,如何控制比人类更聪明的AI交给你们了
聚焦人工智能大模型、AIGC 徐汇十余场重磅论坛等你来
从数据中心到发电站:人工智能对能源使用的影响
创作音乐/音频的Meta开源AI工具AudioCraft,让用户通过文本提示实现
“五年内人类程序员将消失”预言引争议,AI真的那么强大了吗?
城市在采用人工智能方面进展如何?
眼球反射解锁3D世界,黑镜成真!马里兰华人新作炸翻科幻迷
烟台大学学生首次在全国大学生无人机航拍竞赛中获奖
构建人机交互创新模式,微美全息研究AIGC智能交互界面生成技术
陈根:ChatGPT和人类合作开发机器人
明略科技发布免费开源TensorBoard.cpp,促进大型模型的预训练工作
“苏南 vs 苏北” AI 分胜负,娱乐性比较工具 EitherChoice 上线
马斯克称未来机器人数量将多于人类,特斯拉愿共享自动驾驶技术
泗洪:畅通城市“血管” ,管下机器人来帮忙
美的推出 AI 双视精准避障的自动集尘扫拖机器人 V12,售价仅为2999元
鸿蒙OS 4将实现AI大模型集成,余承东表示坚持AI辅助而非AI取代
人工智能颠覆软件测试四大方式
2025-07-17

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
