打造能自己写代码的机器,这是计算机科学和人工智能先锋者一直在追寻的目标。而随着 GPT 类大模型的快速发展,这样的目标正在从遥不可及开始变得近在咫尺。
大语言模型 (Large Language Models) 的出现,让模型的编程能力越来越受到研究者的关注。在此态势下,上海交通大学 APEX 实验室推出了 CodeApex-- 一个专注于评估 LLMs 的编程理解和代码生成能力的双语基准数据集。
在评估大语言模型的编程理解能力上,CodeApex 设计了三种类型的选择题:概念理解、常识推理和多跳推理。此外,CodeApex 也利用算法问题和相应的测试用例来评估 LLMs 的代码生成能力。CodeApex 总共评估了 14 个大语言模型在代码任务上的能力。其中 GPT3.5-turbo 表现出最好的编程能力,在这两个任务上分别实现了大约 50% 和 56% 的精度。可以看到,大语言模型在编程任务上仍有很大的改进空间,打造能自己写代码的机器,这样的未来十分可期。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

编程理解和代码生成是软件工程中的关键任务,在提高开发人员生产力、增强代码质量和自动化软件开发过程中起着关键作用。然而,由于代码的复杂性和语义多样性,这些任务对于大模型来说仍然具有挑战性。与普通的自然语言处理相比,使用 LLMs 生成代码需要更加强调语法、结构、细节处理和上下文理解,对生成内容的准确度有着极高要求。传统的方法包括基于语法规则的模型、基于模板的模型和基于规则的模型,它们通常依赖于人工设计的规则和启发式算法,这些规则和算法在覆盖范围和准确性方面受到限制。
近年来,随着 CodeBERT 和 GPT3.5 等大规模预训练模型的出现,研究人员开始探索这些模型在编程理解和代码生成任务中的应用。这些模型在训练期间集成了代码生成任务,使它们能够理解并生成代码。然而,由于缺乏标准的、公开可用的、高质量的、多样化的基准数据集,对 LLMs 在代码理解和生成方面的进步进行公平的评估是很困难的。因此,建立一个广泛覆盖代码语义和结构的基准数据集对于促进编程理解和代码生成的研究至关重要。
现有的代码基准数据集在应用于 LLMs 时,存在着适用性和多样性的问题。例如,部分数据集更适用于评估 Bert 类型的、双向语言建模的 LLMs。而现存的多语言代码基准数据集(例如 Human-Eval)包含的问题比较简单、缺乏多样性、只能实现一些基本的功能代码。
为了弥补以上空白,上海交通大学 APEX 数据与知识管理实验室构建了一个新的大模型代码理解与生成的评测基准 --CodeApex。作为一个开创性的双语(英语,汉语)基准数据集,CodeApex 专注于评估 LLMs 的编程理解和代码生成能力。
 网易人工智能
网易人工智能
网易数帆多媒体智能生产力平台
 233
查看详情
233
查看详情

CodeApex 的整体实验场景如上图所示。
第一个任务编程理解包括 250 道单项选择题,分为概念理解、常识推理和多跳推理。用于测试的题目选自高校的不同课程 (编程、数据结构、算法) 的期末考试题目,大大降低了数据已经在 LLMs 训练语料库中的风险。CodeApex 在 0-shot、2-shot、5-shot 三种场景下测试了 LLMs 的代码理解能力,并同时测试了 Answer-Only 和 Chain-of-Thought 两种模式对于 LLMs 能力的影响。
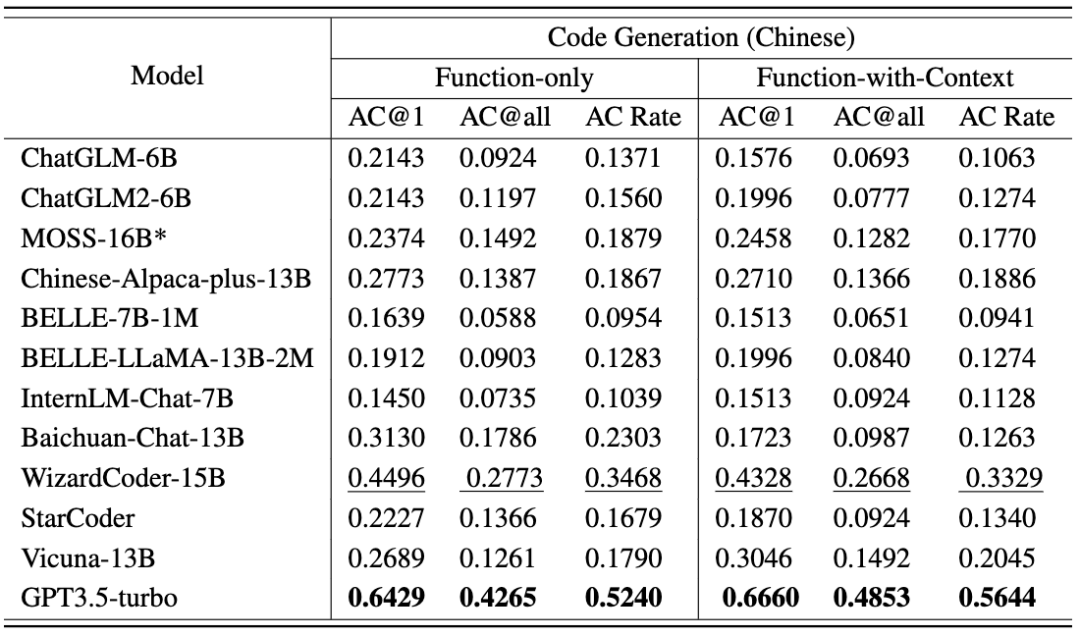
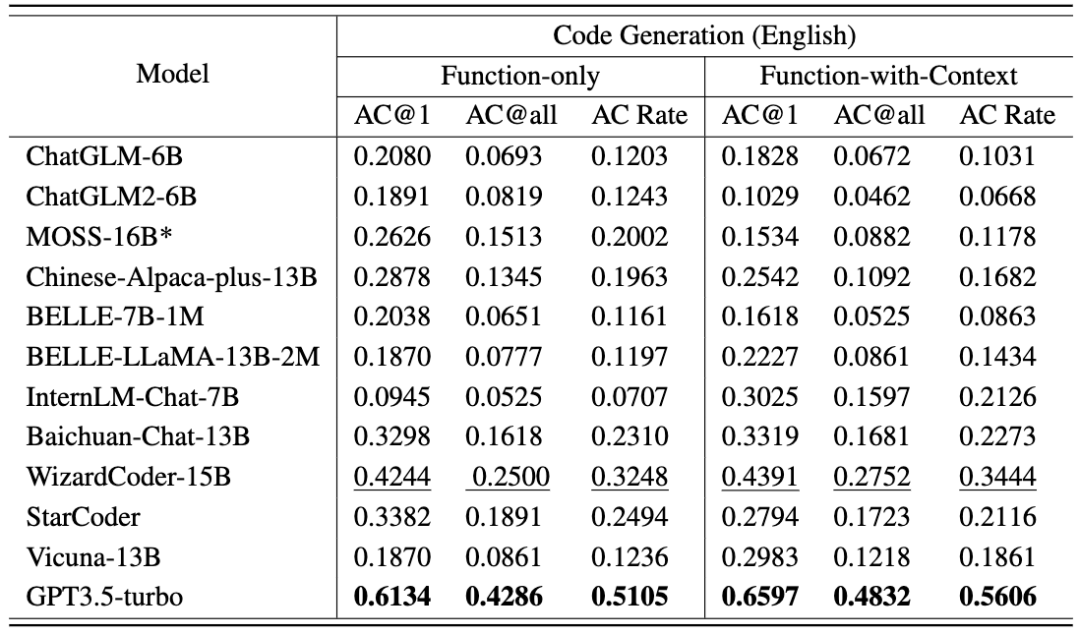
第二个任务代码生成包括 476 个基于 C++ 的算法问题,涵盖了常见的算法知识点,如二分搜索、深度优先搜索等。CodeApex 给出了问题的描述和实现问题的函数原型,并要求 LLMs 完成函数的主要部分。CodeApex 还提供了 function-only 和 function-with-context 两种场景,它们的区别是:前者只有目标函数的描述,而后者除了目标函数的描述之外,还被提供了目标函数的调用代码、时间空间限制、输入输出描述。
实验结果表明,不同模型在代码相关任务中的表现不同,GPT3.5-turbo 表现出卓越的竞争力和明显的优势。此外,CodeApex 比较了 LLMs 在双语场景下的表现,揭示了不同的结果。总体而言,在 CodeApex 排行榜中,LLMs 的准确性仍有很大的提高空间,这表明 LLMs 在代码相关任务中的潜力尚未被完全开发。
要将大语言模型完全集成到实际代码生产场景中,编程理解是必不可少的。编程理解需要从各个方面理解代码的能力,例如对语法的掌握、对代码执行流程的理解以及对执行算法的理解。
CodeApex 从高校期末考试题目中抽取了 250 道选择题作为测试数据,这些测试数据被分成了三类:概念理解、常识推理、多跳推理。

测试模式包括两类:Answer-Only 和 Chain-of-Thought。

CodeApex 在代码理解任务上的中英评测结果如以下两表所示。(表现最好的模型加粗显示;表现次好的模型用下划线标注。)
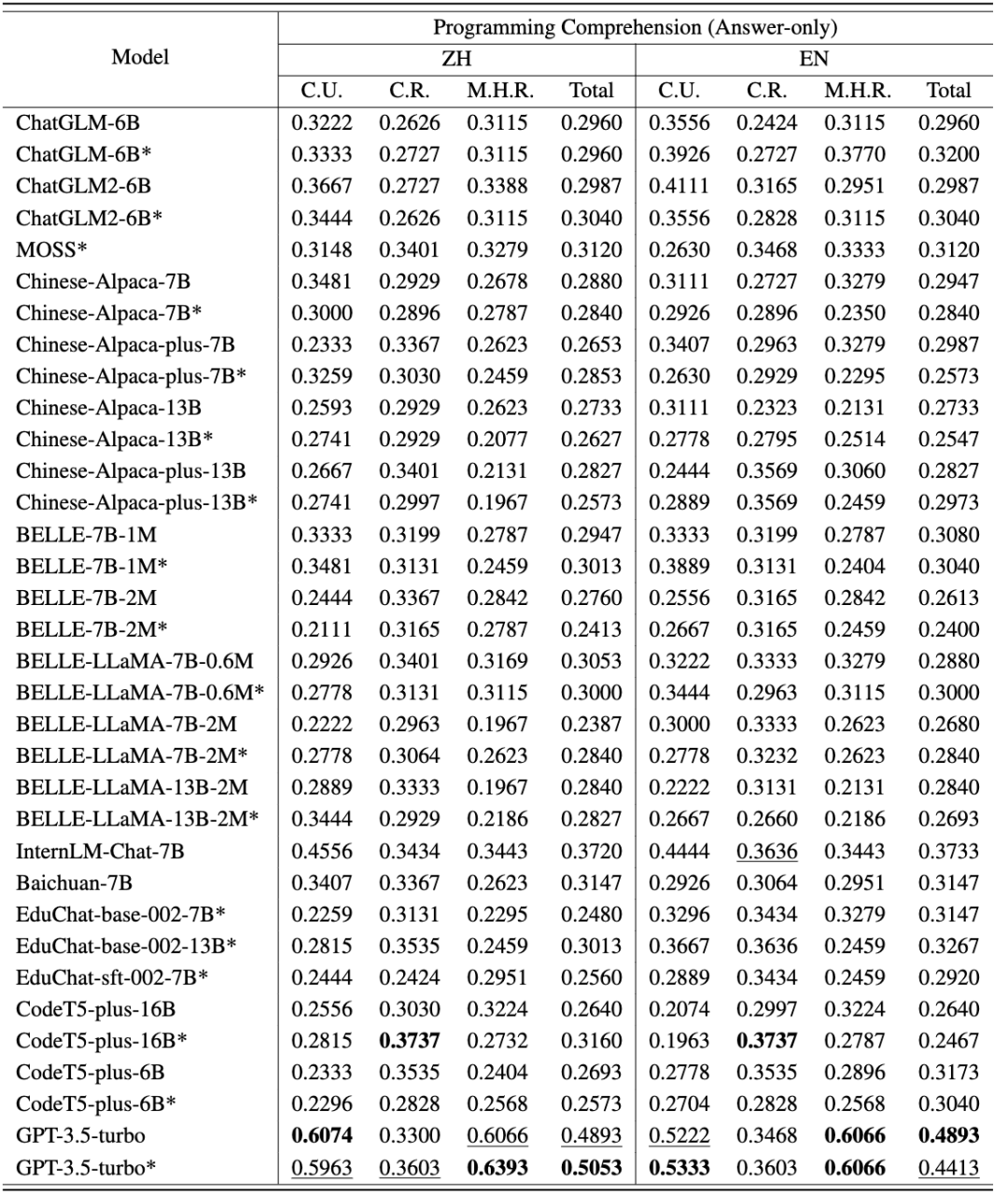
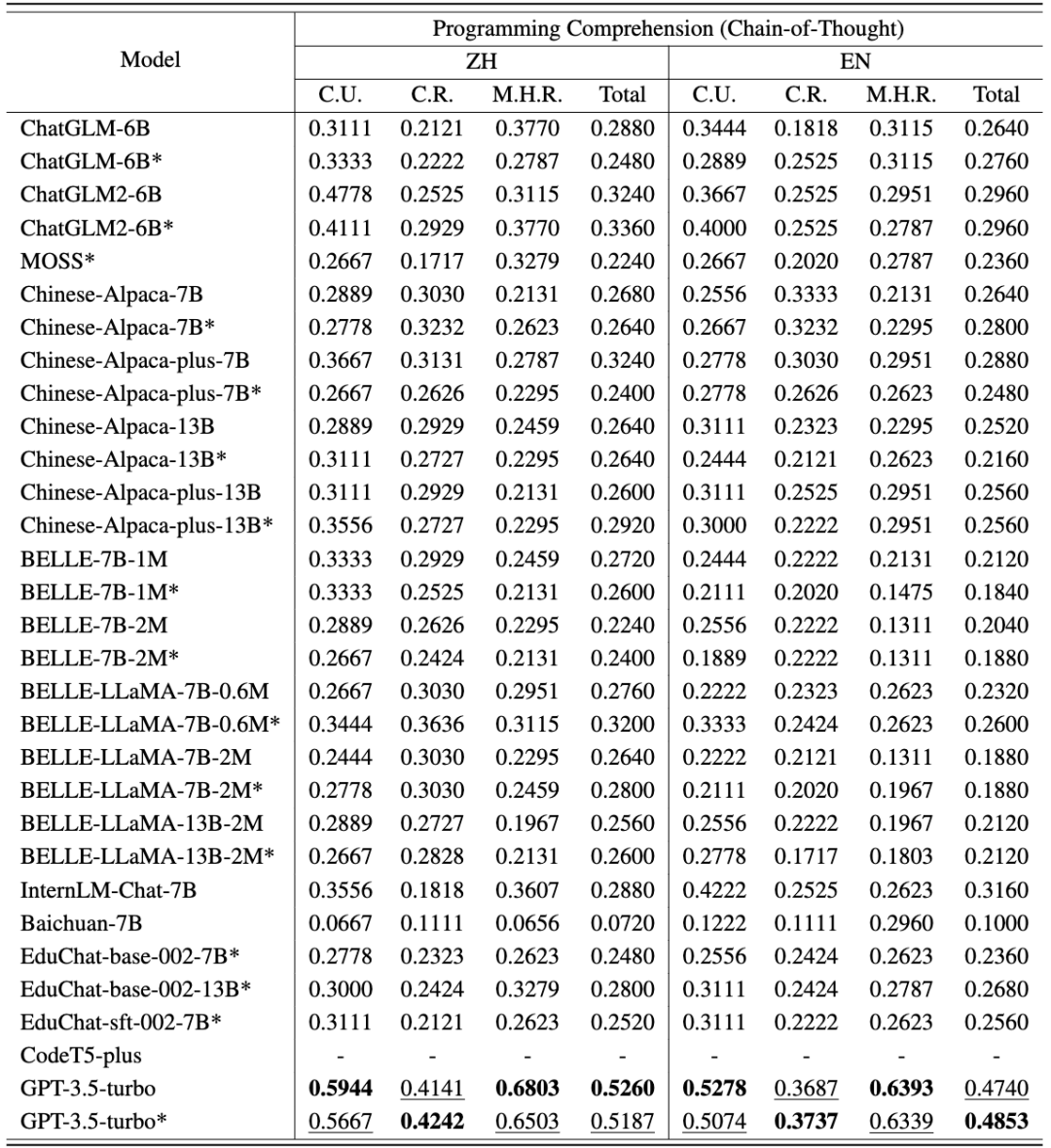
从中可以得到以下结论:
训练大语言模型生成准确且可执行的代码是一项具有挑战性的任务。CodeApex 主要评估 LLMs 基于给定描述生成算法的能力,并通过单元测试自动评估生成代码的正确性。
CodeApex 的代码生成任务包括 476 个基于 C++ 的算法问题,涵盖了常见的算法知识点,如二分搜索和图算法等。CodeApex 给出了问题的描述和实现问题的函数原型,并要求 LLMs 完成函数的主要部分。

CodeApex 提供了 Function-only 和 Function-with-context 两种场景。Function-only 场景只提供了目标函数的描述,而 Function-with-context 场景不仅提供了目标函数描述,还提供了目标函数的调用代码、 时间空间限制、输入输出描述。

每种语言版本都采用了两种 Prompt 策略 (Function-Only 和 Function-with-Context)。为了和人类代码测试场景对齐,评估指标包括了 AC@1, AC@all 和 AC 率。
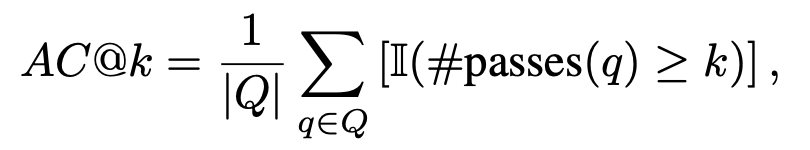
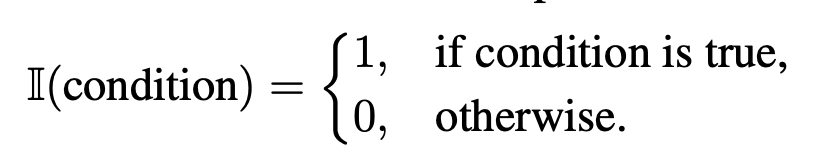
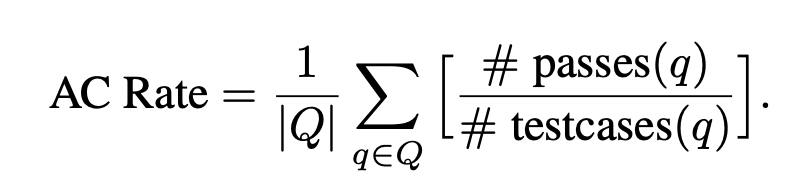
各模型的代码生成任务结果如以下两张表格所示。(表现最好:加粗;表现次好:下划线。)
可以得到以下结论:
此外,CodeApex 还提供了每种场景中可编译代码的比例。在将生成函数和主函数连接起来之后,可编译的代码再去通过测试用例进行检查。
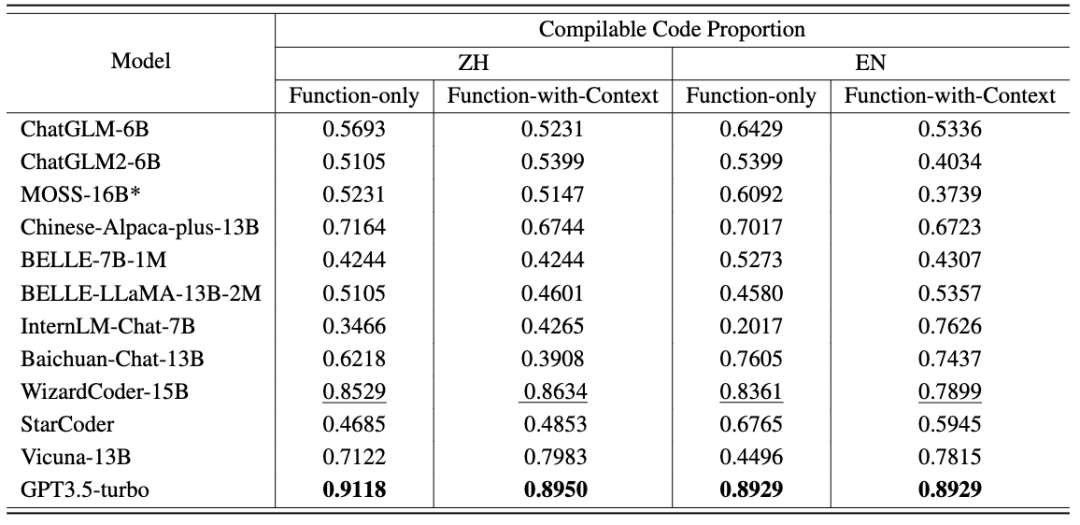
可以看到:
CodeApex 作为一个关注 LLMs 编程能力的双语基准,评估了大语言模型的编程理解和代码生成能力。在编程理解上,CodeApex 在三类选择题中评估了不同模型的能 力。在代码生成上,CodeApex 利用测试代码用例的通过率来评估模型的能力。对于这两个任务,CodeApex 精心设计了 Prompt 策略,并在不同的场景下进行了比较。CodeApex 在 14 个 LLMs 上进行了实验评估,包括通用 LLMs 和基于代码微调的专用 LLMs 模型。
力。在代码生成上,CodeApex 利用测试代码用例的通过率来评估模型的能力。对于这两个任务,CodeApex 精心设计了 Prompt 策略,并在不同的场景下进行了比较。CodeApex 在 14 个 LLMs 上进行了实验评估,包括通用 LLMs 和基于代码微调的专用 LLMs 模型。
目前,GPT3.5 在编程能力方面达到了比较良好的水平,在编程理解和代码生成任务上分别实现了大约 50% 和 56% 的精度。CodeApex 显示,大语言模型在编程任务上的潜力尚未被完全开发。我们期待在不久的将来,利用大型语言模型生成代码将彻底改变软件开发领域。随着自然语言处理和机器学习的进步,这些模型在理解和生成代码片段方面将变得更加强大和熟练。开发人员将发现他们在编码工作中拥有了一个前所未有的盟友,因为他们可以依靠这些模型来自动化繁琐的任务,提高他们的生产力,并提高软件质量。
在未来,CodeApex 将发布更多用于测试大语言模型代码能力的测试(例如代码校正),CodeApex 的测试数据也会持续更新,加入更多元的代码问题。同时,CodeApex 榜单也会加入人类实验,将大语言模型的代码能力和人类水平做对比。CodeApex 为大语言模型编程能力的研究提供了基准与参考,将促进大语言模型在代码领域的发展与繁荣。
上海交大 APEX 数据与知识管理实验室成立于 1996 年,其创办人为 ACM 班总教头俞勇教授。实验室致力于探索将数据有效挖掘和管理并总结出知识的人工智能技术,发表 500 篇以上国际学术论文,并追求在实际场景中的落地应用。27 年来,APEX 实验室在多次世界技术浪潮中成为全球范围内的先锋者,实验室于 2000 年开始研究语义网(现称知识图谱)核心技术,于 2003 年开始研究个性化搜索引擎和推荐系统技术,于 2006 年开始研究迁移学习理论与算法,于 2009 年开始探索深度学习技术并基于 GPU 开发神经网络训练库。产出丰硕的科研和落地成果的同时,APEX 实验室也锻炼出了一支功底扎实的数据科学与机器学习研究团队,走出了包括薛贵荣、张雷、林晨曦、刘光灿、王昊奋、李磊、戴文渊、黎珍辉、陈天奇、张伟楠、杨笛一等人工智能领域杰出校友。
以上就是上海交大发布大模型双语编程评估基准CodeApex,机器真的开始挑战人类写代码了吗?的详细内容,更多请关注其它相关文章!
# 数据
# 上海交大
# 网易
# 出了
# 模型
# 临汾正规seo推广
# 网站设计优化推荐怎么写
# 网络整合营销推广策划书
# 产品看图网站推广方法
# 建设什么网站好看
# 江门网站关键词推广
# 延边外贸网站推广
# seo考试报名要求
# 淄博机械行业关键词排名
# seo除了tdk
# 景中
# 丰田
# 所示
# 中国科学院
# 软件工程
# 数据结构
# 两种
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
华为发布两款AI存储新品
SnapFusion技术大幅提升AI图像生成速度
华为HarmonyOS 4:享流畅提升20%,AI大模型更智能一览无余
谷歌借AI打破十年排序算法封印,每天被执行数万亿次,网友却说是最不切实际的研究?
云鲸发布全新的扫拖机器人J4系列
【搞事】时隔4年 谷歌更新安卓logo 机器人头更饱满了
智能公司为何纷纷投身机器人领域?
曝索尼在开发新头显设备:游戏中使用AR技术
“三夏”农忙保障用电,无人机高空巡视高压线
2025年的网络分区:人工智能和自动化如何改变事物
值得买科技入选“北京市通用人工智能产业创新伙伴计划”应用伙伴
Moka AI产品后观察:HR SaaS迈进AGI时代
在这里见未来!杭州未来科技城全球AI盛会邀您共探最前沿
苹果机器学习关键人物 Ali Farhadi 离职,回归 AI2 担任 CEO
2025智源大会AI安全话题备受关注,《人机对齐》新书首发
马斯克回应人工智能拯救世界:人类已处于“半机器人”状态
新华社联合北大发布AI大模型评测:安全可靠成重点,360智脑表现优异
腾讯汤道生:大模型只是起点,产业落地是AI更大的应用场景
如何获得元宇宙的第一个属于自己的空间
MiracleVision视觉大模型上线时间
创作音乐/音频的Meta开源AI工具AudioCraft,让用户通过文本提示实现
元宇宙技术带你穿梭“大运河”,江苏书展上的数字阅读馆吸睛小读者
拓普龙7188ML:轻便壁挂式工控机箱,为人工智能应用场景提供有力保障
放弃自动驾驶,也是一种和解
2025VR&AR显示技术峰会视频解析: 歌尔光学展示最新一代VR/AR光学模组
【趋势周报】全球元宇宙产业发展趋势:ChatGPT的出现,将元宇宙实现至少提前了10年
中国移动副总经理高同庆:打造人工智能时代的智能服务运营新范式
从数据中心到发电站:人工智能对能源使用的影响
苹果AIGC专利:可通过语音指令生成AR/VR虚拟场景
AI赋能艺术 超现实达利奇幻之旅在沪开启
特斯拉门店可能启动机器人卖车?也许不是你想的那样
WHEE功能介绍
通用医疗人工智能如何革新医疗行业?
学界业界大咖探讨:AI对数字艺术创新的推动力
本届人工智能大会上的这个“镇馆之宝”,来自长宁企业西井科技!
马斯克的幽默“现实”:AR眼镜与20美元“增强现实”哪个真实?
生活垃圾智能分类机器人社区展“才能”,征求居民意见
AI取代人工先拿教育行业开刀?美版“作业帮”启动裁员
谷歌在人工智能领域没有“护城河”?
跟着AI大热的“光模块”到底是什么?
配 3D 机器人头像,谷歌展示全新安卓 LOGO
从谷歌到亚马逊,科技巨头们的AI痴迷
视觉中国推出AI灵感绘图功能,付费后可在“合法合规前提下使用”
中兴通讯无人机高空基站助力北京门头沟受灾乡镇保障应急通信
尼康尼克尔Z 180-600mm f/5.6-6.3 VR镜头发布:12499元 拍鸟神器
微软新出热乎论文:Transformer扩展到10亿token
这效果能打几分?AI真人化《名侦探柯南》
谷歌推出新 AI 工具 Imagen Editor,一句话对图片二次创作
人工智能赋能无人驾驶:商业化进程再提速
RoboNeo安装教程
2023-09-05

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
