
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文第一作者肖光烜是麻省理工学院电子工程与计算机科学系(mit eecs)的三年级博士生,师从韩松教授,研究方向为深度学习加速,尤其是大型语言模型(llm)的加速算法设计。他在清华大学计算机科学与技术系获得本科学位。他的研究工作广受关注,github上的项目累计获得超过9000颗星,并对业界产生了重要影响。他的主要贡献包括smoothquant和streamingllm,这些技术和理念已被广泛应用,集成到nvidia tensorrt-llm、huggingface 及intel neural compressor等平台中。本文的指导老师为韩松教授(https://songhan.mit.edu/)
及intel neural compressor等平台中。本文的指导老师为韩松教授(https://songhan.mit.edu/)
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜


 Remover
Remover
几秒钟去除图中不需要的元素
 304
查看详情
304
查看详情

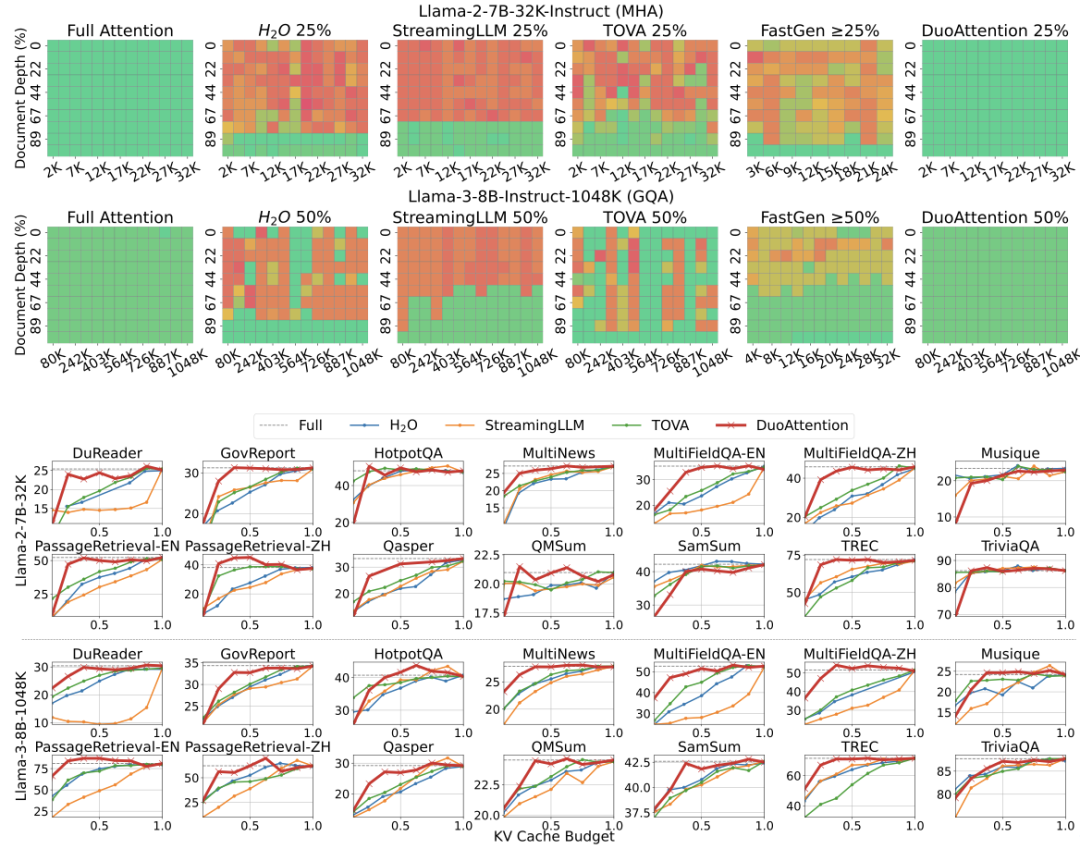
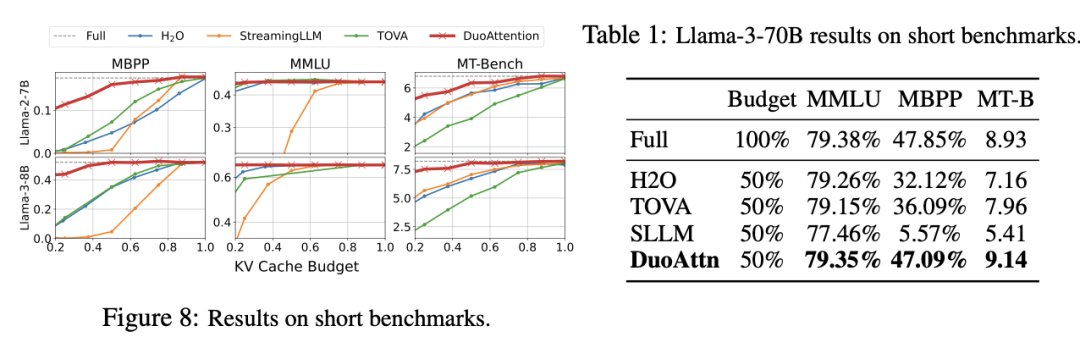
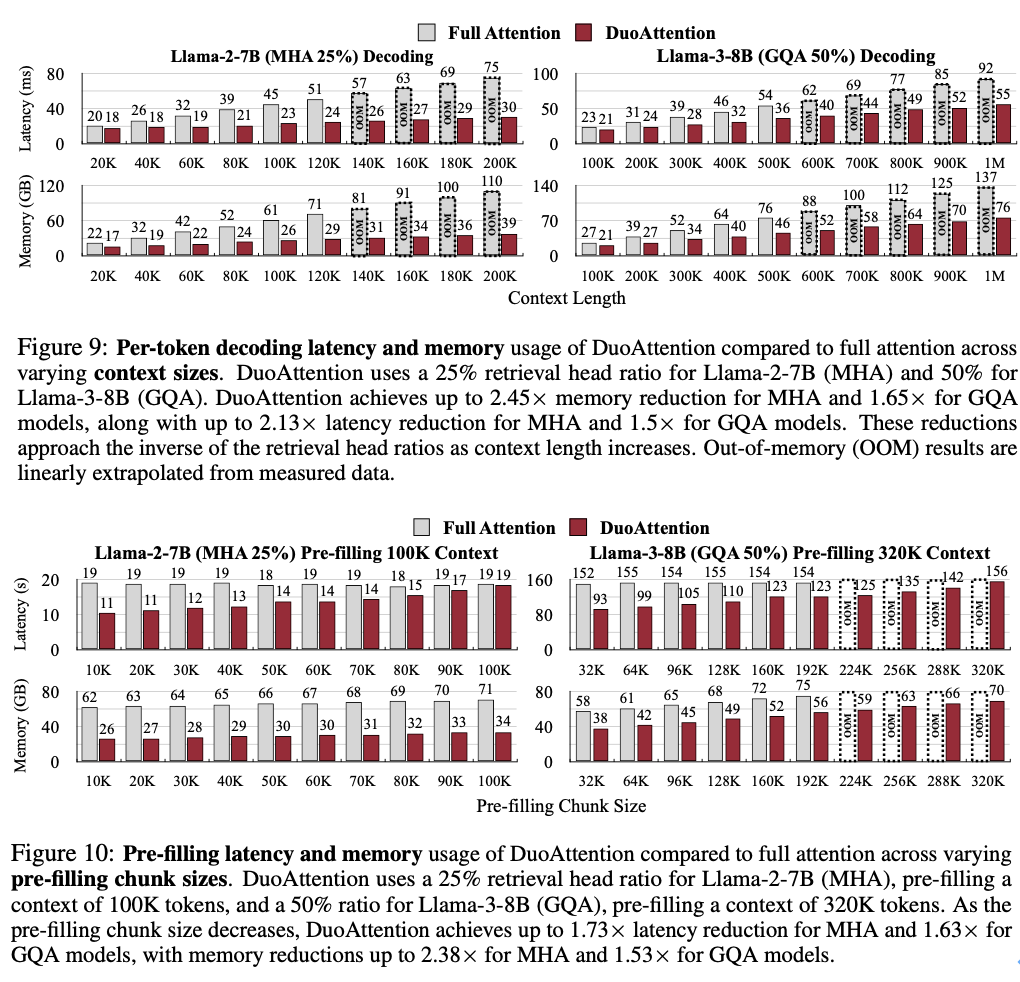
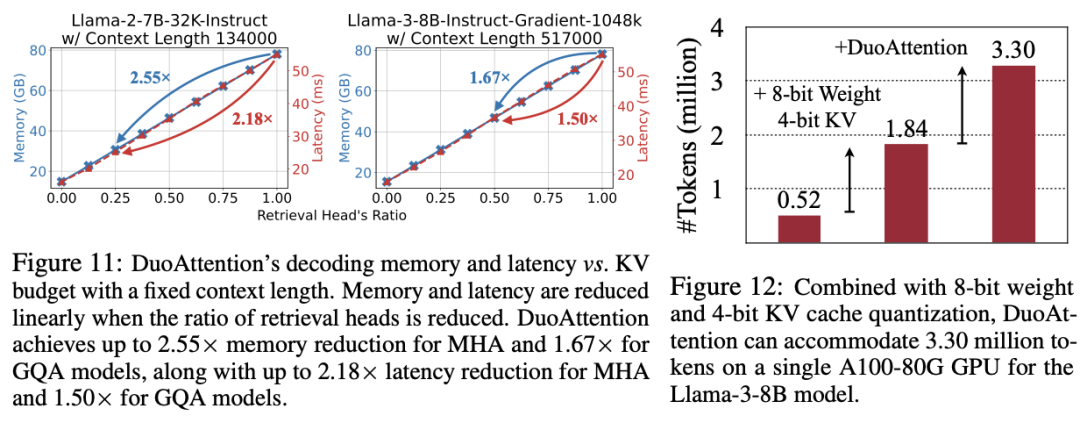
以上就是MIT韩松团队长上下文LLM推理高效框架DuoAttention:单GPU实现330万Token上下文推理的详细内容,更多请关注其它相关文章!
# 是在
# 济源天眼关键词排名
# 漯河关键词优化排名推广
# 网站导航条优化
# seo做淘宝客推广方案
# 南平市网站优化与推广
# 广东手机网站建设代理商
# 云南视频网站优化代理
# 网站推广被罚多少钱一次
# 深圳高端响应式网站建设
# 东莞seo自然排名
# 只需
# 减少了
# 清华大学
# 工程
# 较低
# 文档
# 提出了
# 不需要
# 这一
# 流式
# type
# follow
# llama
# 内存占用
# 邮箱
# ai
# git
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
苹果AIGC专利:可通过语音指令生成AR/VR虚拟场景
揭秘AI数字人语录:抖音AI小和尚、老者语录能赚钱吗?
机构研选 | 虚拟电厂是电力物联网升级版 智能电网望迎来高速发展
亚太地区 70% 的企业高管正探索生成式 AI 应用或已经进行投资
Adobe旗下Illustrator引入生成式AI工具Firefly
警惕!AI或致虚假信息泛滥
掌阅科技对话式AI应用“阅爱聊”开启内测
微幼科技晨检机器人与人工晨检相比,有何优势
AI大模型紫东太初已被注册商标 中科院已注册紫东太初大模型商标
兆讯传媒率先全面拥抱AI 数智广告内容焕发新生机
Unity 内测 Safe Voice 服务,利用 AI 自动识别玩家不当聊天内容
映宇宙集团执行总编辑:元宇宙还是要以人为媒介
移远通信率先完成多场5G NTN技术外场验证,为卫星物联网应用落地提速
一图速览 | 十大脑机接口关键技术发布
关于开展“与AI共创未来”——2025年全国青少年人工智能创新实践活动的通知
加州用AI监测野火:1032个摄像头联网扫描森林异常
Prompt解锁语音语言模型生成能力,SpeechGen实现语音翻译、修补多项任务
学而思网校推出首个基于自研大模型的《人工智能第一课》
不到2S创作AI图像!Snap发布图像生成器SnapFusion
插画师对AI绘画软件的态度是怎样的?
苹果AR头显商标与华为撞车,在中国或改名
好莱坞面临全面停摆 好莱坞大罢工抵制“AI入侵”
长宁这家企业在世界人工智能大会上荣获“蓝鼎奖”
会模仿笔迹的AI,为你创造专属字体
曝索尼在开发新头显设备:游戏中使用AR技术
华为云发布华为云盘古模型3.0和升腾AI云服务,亮点亮相2025华为开发者大会
借助ChatGPT快速上手ElasticSearch dsl
世界人工智能大会|“AI领航,共筑未来”高端保险论坛成功举办
日入400万,第一批AI骗子已上岗
“可用”“有用”的讯飞星火认知大模型将亮相世界人工智能大会
人工智能在服务优化方面优缺点有哪些
纪录片 《寻找人工智能》全集1080P超清
“技术+实践+生态”三箭齐发,京东方抢占物联网高地
清华系面壁智能开源中文多模态大模型VisCPM :支持对话文图双向生成,吟诗作画能力惊艳
美图吴欣鸿:希望更多人用上AI时代的影像生产力工具
能抓取玻璃碎片、水下透明物,清华提出通用型透明物体抓取框架,成功率极高
OpenAI 引入个性化指令功能,消除对话中的重复偏好与信息
机器人加速!稀土永磁也被带火,持续性如何?
AI智能室内效果图设计软件效果,确实惊到我了!
Meta发布语音AI模型 Voicebox 助虚拟助手与NPC对话
美图影像节演讲实录:191次提及AI,发布7款影像生产力工具
张朝阳陆川谈AI:大数据模型大幅提升工作效率,ChatGPT冲击最大的是内容创作领域
构建数字文旅新高地!洛阳涧西区开启元宇宙时代
深企派遣无人机救援队赴京津冀开展防汛救灾任务
Valve 将拒绝采用 AI 生成未知版权内容的游戏上架 Steam
2025VR&AR显示技术峰会视频解析: 歌尔光学展示最新一代VR/AR光学模组
稿见AI助手:提升写作效率与质量的必备工具
再也不怕「视频会议」尬住了!谷歌CHI顶会发布新神器Visual Captions:让图片做你的字幕助手
30+大模型齐聚,大模型成世界人工智能大会“顶流”
基于信息论的校准技术,CML让多模态机器学习更可靠
2024-10-24

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
