Molmo,开源多模态模型正在发力!

它也可以从虚拟世界帮你解决现实世界的问题,说一句:「molmo,帮我买杯星巴克的南瓜拿铁。」剩下的就不用动手了,打开外卖网页、点餐、付款,molmo 一气呵成。你所要做的,就是坐在家中,静候咖啡送到你的手中。
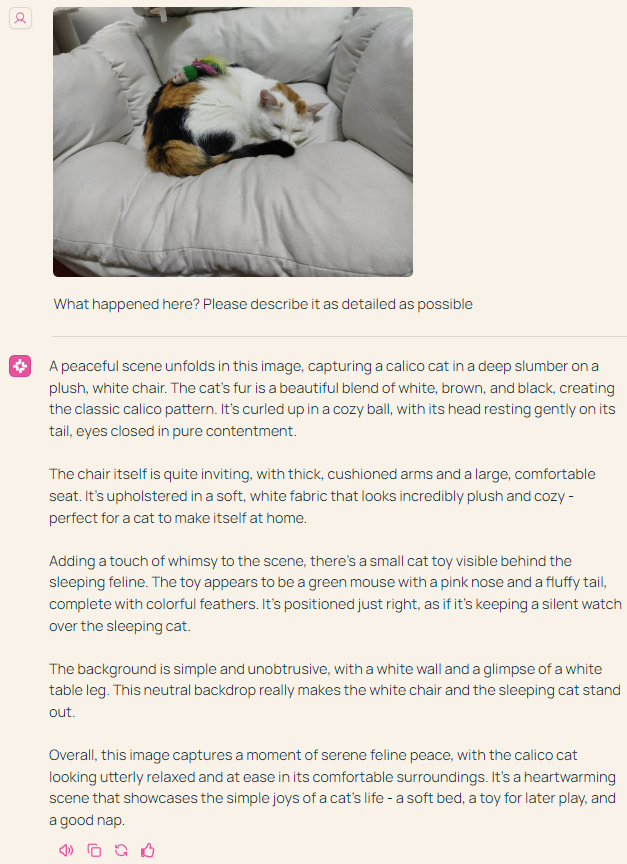
本站也尝试了一下他们在线发布的 Demo 模型。相较于宣传视频,其功能还很有限,所以我们让其执行了图像描述任务,可以看到 Molmo 在细节描述和准确度上的表现确实很不错,它甚至能注意到猫背上的小玩具:「玩具看起来像一只绿色的老鼠,鼻子是粉红色的,尾巴是蓬松的,羽毛色彩缤纷。」
但遗憾的是,Molmo 的汉语输出能力非常有限,即使我们明确要求其输出汉语,它也未能办到:

除了 Demo,从数据来看,Molmo 的表现也足够惊艳。在人类测评和一系列测试集中,Molmo 的得分击败了 Claude 3.5 Sonnet、GPT4V 等一众顶尖模型,甚至可以媲美 GPT4o。
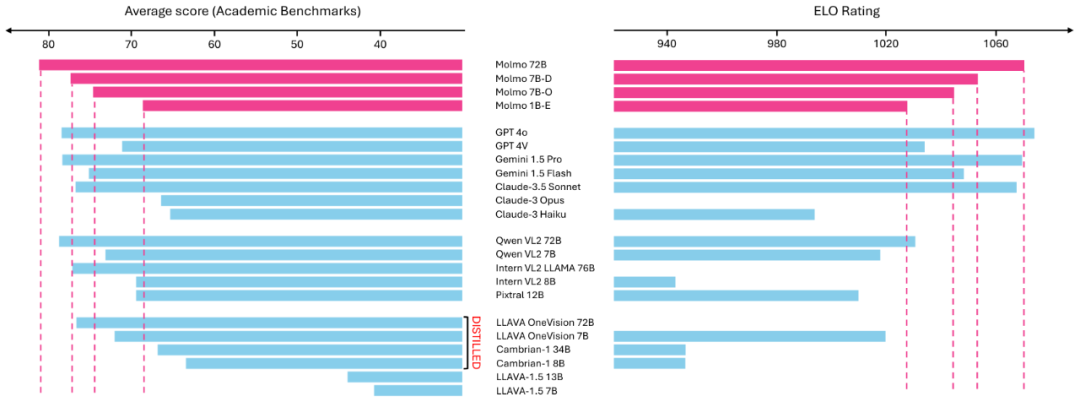
不过,Molmo 的体量更小,却能「以小搏大」,性能超越了比它的参数量大十倍的其他模型。据 Ai2 首席执行官 Ali Farhadi 称,Molmo 的体积小到可以在本地运行,它无需 API、无需订阅、更无需成本高昂的液冷 GPU 集群。
更重要的是 Molmo 完全免费且开源,所有的权重、代码、数据和评估流程都即将公布。
部分模型权重、推理代码和一个基于 Molmo-7B-D 模型的公开演示已经可以使用。
Ai2 又是如何做到「四两拨千金」的呢?答案在 Ai2 公布的技术报告和论文中,这个秘诀就是:数据。

目前,最先进的多模态模型大多是闭源的,即使有一些开源的模型表现不错,但它们通常依赖于专有模型生成的合成数据。因此,如何从零开始构建高性能 VLM,对于开源社区来说,种种基础知识都很难获得。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
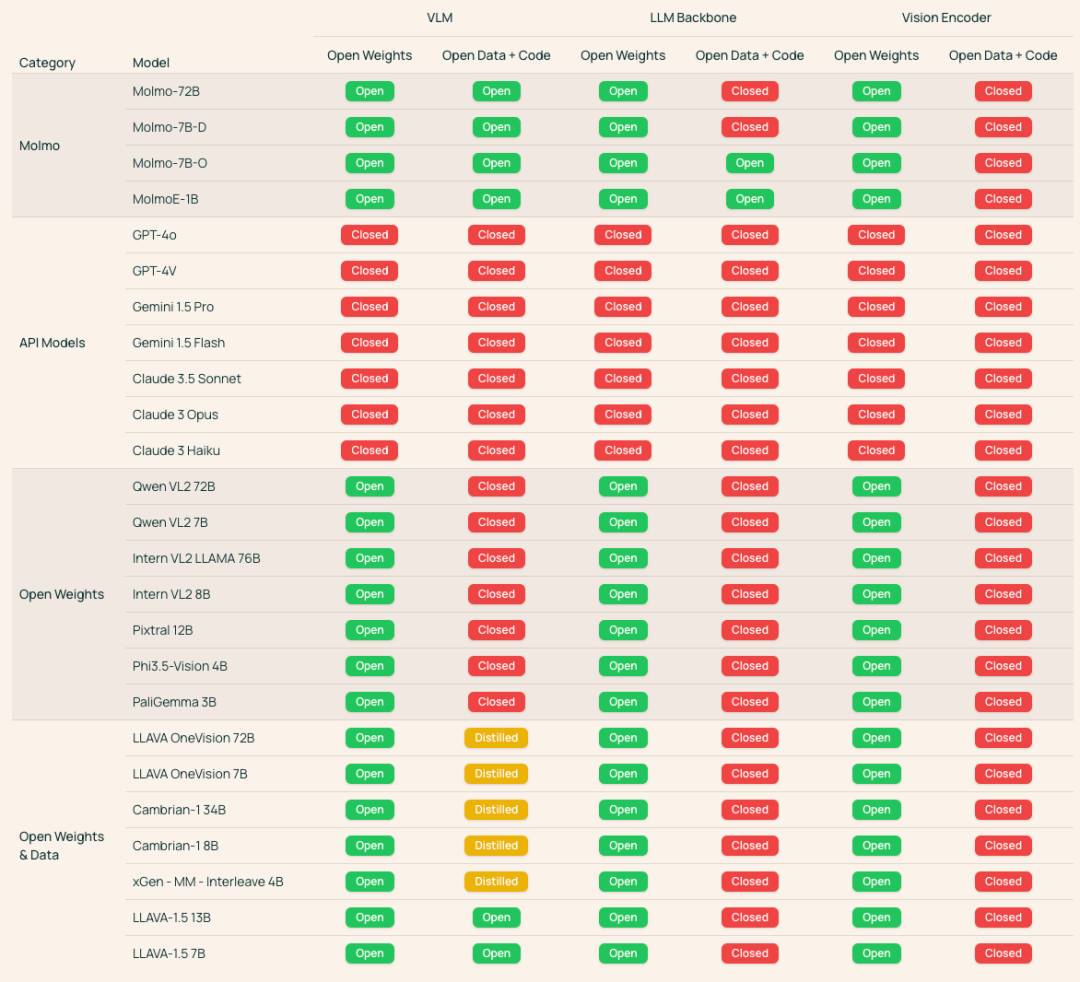
如上图所示,Ai2 的研究团队统计了目前 VLM 的开源程度,除了直接看模型的权重、数据和代码是否公开,他们还考虑了模型是否依赖于其他闭源模型。如果一个模型在训练中用了其他专有模型生成的数据,那它就被标记为「蒸馏」,这意味着它无法完全独立再现。
针对「闭源」的瓶颈,Ai2 使用语音描述收集了一个高细节度的图像描述数据集,这个数据集完全由人工标注,并可以公开访问。
该团队认为提升模型性能的诀窍是使用更少但质量更好的数据。面对数十亿张图像,不可能仅靠人力完成筛选、精细标注和去重的工作,因此,他们没有选择 scaling law,而是精心挑选并注释了 60 万张图像。
为了让 Molmo 能处理更多任务,Ai2 还引入了一个多样化的数据混合对模型进一步微调,其中就包括一种独特的二维「指向」数据。
因为现在市面上的多模态模型的工作原理是把图片、声音、文字等多种模态转换成自然语言的表示,而基于「指向」数据的 Molmo 更进一步,它可以用非语言的方式(如指向物体)进行解答。
比如,向 Molmo 提问:「你可以指出这块白板上的哪个模型的训练时间最短吗?」它不仅能用语音准确回答,还能直接用箭头「指向」它是从哪些数据中得到答案的。

要求 Molmo 数图中有多少只狗,它的计数方法是在每只狗的脸上画一个点。如果要求它数狗狗舌头的数量,它会在每只舌头上画一个点。
「指向」让 Molmo 能够在零样本的情况下执行更广泛的任务,同时,无需查看网站的代码,它可以懂得如何浏览页面、提交表单。
这种能力也让 Molmo 更自然地连接现实世界和数字世界,为下一代应用程序提供全新的互动方式。
通常而言,要训练一个大型 VLM,需要数以十亿计的图像 - 文本对数据。而这些数据往往取自网络,因此噪声很高。模型就需要在训练过程中分离信号与噪声。有噪声文本还会导致模型输出出现幻觉。
基于这样的考虑,该团队采用了不同的方法来获取数据。他们将数据质量放在了更重要的位置,结果发现,使用少于 1M 的图像 - 文本对就足以训练出强大的模型 —— 这比许多其它同类方法少了 3 个数量级。
Molmo 系列模型之所以能取得成功,最关键的要素莫过于 PixMo——Molmo 的训练数据。
Pixmo 包含两大类数据:(1) 用于多模式预训练的密集描述数据和 (2) 用于实现各种用户交互的监督式微调数据,包括问答、文档阅读和指向等行为。
该团队表示,在收集这些数据时,主要限制是避免使用已有的 VLM,因为「我们希望从头构建一个高性能 VLM」,而不是蒸馏某个已有的系统(但注意,他们也确实会使用仅语言的 LLM,但并不会把图像输入这些模型)。
在实践中,要让人类来标注大量数据是非常困难的。而且人类编写的图像描述往往仅会提及一些突出的视觉元素,而缺乏细节。如果强制要求最低字数,标注者要么需要花费太长时间,使收集过程成本高昂,要么就会从专有 VLM 复制粘贴响应,这又会违背避免蒸馏模型的目标。
因此,开放研究社区一直在努力,在不依赖专有 VLM 的合成数据的前提下,创建这样的数据集。
该团队提出了一种简单但有效的数据收集方法,可以避免这些问题:让标注者用语音描述图像 60 到 90 秒,而不是要求他们打字。他们让标注者详细描述他们看到的一切,包括空间定位和关系的描述。
从结果上看,该团队发现,通过这种模态切换「技巧」,标注者可以在更短的时间内提供更详细的描述,并且对于每个描述都有对应的录音,可证明未使用 VLM。
总的来说,他们收集了 71.2 万幅图像的详细音频描述,涵盖 50 个高层级主题。
他们的混合微调数据包含了标准的学术数据集以及一些新收集的数据集,这些新数据集也将会公开发布。学术数据集主要用于使模型在基准测试数据上表现良好,而新收集的数据集则能赋予模型大量重要功能,包括在与用户聊天时能够回答关于图像的一般性问题(超出学术基准数据范围)、提升 OCR 相关任务(如读取文档和图表)、精准识别模拟时钟的时间,以及在图像中指向一个或多个视觉元素。
指向功能可为图像中的像素提供自然的解释,从而带来 Molmo 全新且更强大的能力。该团队认为,指向将成为 VLM 和智能体之间重要的交流方式。例如,一个机器人可以查询具有指向功能的 VLM 以获得路径点或要拾取物体的位置,而一个网页智能体可以查询 VLM 以定位需要点击的用户界面元素。这组系列数据集也分为以下六个:
PixMo-Cap:用于预训练 VLM 的数据集,可让其理解图像细节,其中包含 71.2 万张不同图像和大约 130 万个密集图像描述。
PixMo-AskModelAnything:其设计目标是让 AI 模型可回答有关图像的不同问题。其中包含 16.2 个问答对,涉及 7.3 万图像。其中问题由人类标注者编写,答案则来自一个语言模型。
PixMo-Points:其中的图像描述数据是关于图像中物体的位置。该数据集包含 230 万个问题 - 位置点对,涉及 42.8 万张图像。
PixMo-CapQA:包含 21.4 万个问答对,涉及 16.5 万个使用语言模型生成的图像描述。
 Remover
Remover
几秒钟去除图中不需要的元素
 304
查看详情
304
查看详情

PixMo-Docs:包含 25.5 万张带有大量文本和图表(表格、文档、图表)的图像,还有语言模型生成的相应代码。另有 230 万对基于生成的代码生成的问答。
PixMo-Clocks:这是一个合成数据集,其中包含 82.6 万张不同款式的模拟时钟图像,以及有关相应时间的问答。
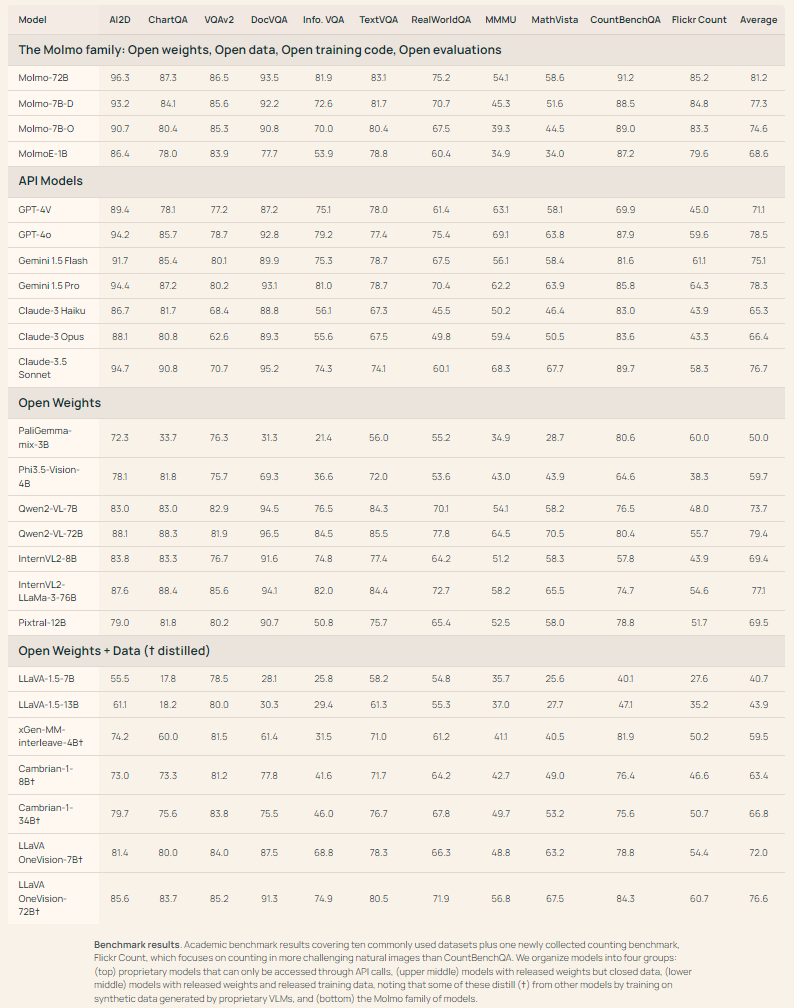
为了进行全面的评估,该团队既使用了学术基准评测,也执行了人类评估以根据用户偏好对模型进行排名。
从结果上看,学术基准评测结果与人类评估结果高度一致。唯一的例外是 Qwen VL2,其在学术基准上表现很好,但在人类评估中表现相对较差。
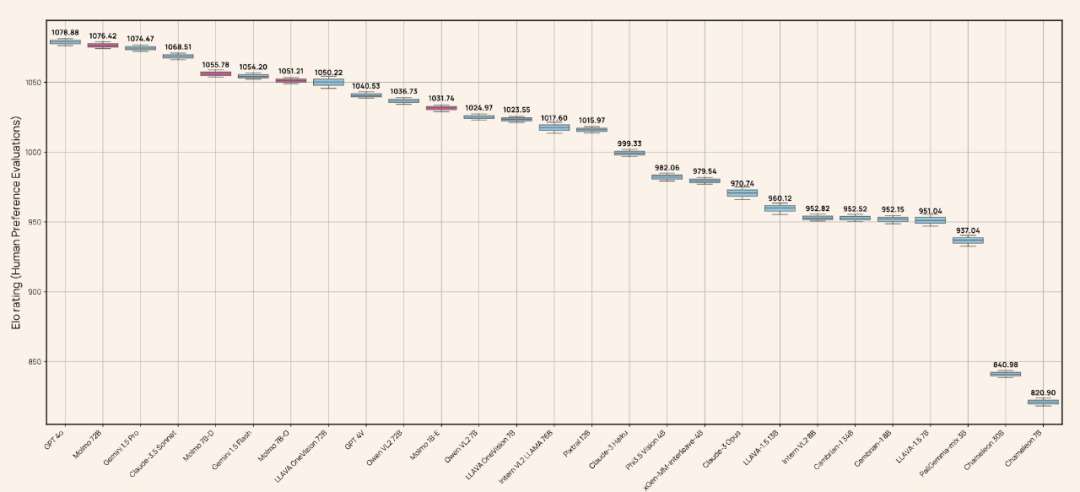
该团队总结得到了一些关键结果,并表示「Small is the new big, less is the new more」,详情如下:
Molmo 系列模型中最高效的是 MolmoE-1B,其基于完全开放的 OLMoE-1B-7B 混合专家 LLM,在学术基准和人类评估上的表现接近 GPT-4V。
在学术基准和人类评估基准上,两个 Molmo-7B 模型的表现大概在 GPT-4V 和 GPT-4o 之间,并且在这两个基准上均显著优于近期发布的 Pixtral 12B 模型。
表现最好的 Molmo-72B 在学术基准上取得了最高分,但人类评估基准上则仅次于 GPT-4o,居于第二。
表现最好的 Molmo-72B 也胜过当前最佳的一些专有系统,包括 Gemini 1.5 Pro 和 Flash 以及 Claude 3.5 Sonnet。
在接受 TechCrunch 的采访时, Ai2 首席执行官 Ali Farhadi 表示,人工智能界有条定律 ——「越大越好」,训练数据越多,模型中的参数就越多,需要的算力也就越多。但发展到一定阶段时,「scaling law」就会遇到瓶颈,根本无法继续扩大模型规模了:没有足够的数据、或者计算成本和时间变得太高,以至于弄巧成拙。你只能利用现有的资源,或者更好的办法是,用更少的资源做更多的事情。

 Ai2 首席执行官 Ali Farhadi
Ai2 首席执行官 Ali FarhadiMolmo 的模型架构采用了简单的标准设计,也就是将一个语言模型和一个图像编码器组合起来。其包含 4 个组件:
预处理器,其作用是将输入图像转换为一组多尺寸和经过不同裁剪的图像;
ViT 图像编码器,其作用是将每一张图像都独立映射成一组视觉 token;
连接器,其作用是使用 MLP 将视觉 token 投影成语言模型的输入维度,然后汇集视觉 token 以减少其数量;
仅解码器 Transformer LLM。
该团队基于这一模板构建了一个模型系列。通过选择不同的视觉编码器和 LLM 可以为其赋予不同的参数。在这些选择基础上,所有模型的后续训练数据和方案都一样。
对于视觉编码器,他们发布的所有模型均使用 OpenAI 的 ViT-L/14 336px CLIP 模型,该模型的效果好且质量稳定。
对于 LLM,他们采用不同的规模,基于不同的开放程度训练了模型:OLMo-7B-1024 的权重和数据完全开放的(使用了 2025 年 10 月的预发布权重,其将于晚些时候公布)、高效的 OLMoE-1B-7B-0924 也是完全开放权重和数据,Qwen2 7B、Qwen2 72B、Mistral 7B、Gemma2 9B 则是仅开放权重。新发布的是该系列的 4 个样本。
他们的训练过程也很简单,首先从已经独立完成预训练的视觉编码器和 LLM 开始,接下来分为两个阶段:
多模态预训练,以使用他们新收集的描述数据生成描述;
使用上述混合数据集进行监督式微调。
这两个阶段都会对所有参数进行更新,并且过程中不使用 RLHF。
该团队首次发布就分量十足,包含一个演示模型、推理代码、一份简要的技术报告和以下模型权重:
MolmoE-1B,由 1B(活跃参数量)的专家模型构成的混合专家模型,共 7B
Molmo-7B-O,最开放的 7B 模型
Molmo-7B-D,演示版本的模型
Molmo-72B,表现最佳的模型
未来两个月,该团队还将陆续发布以下研究成果:
一份详细的技术报告
PixMo 系列数据集
更多模型权重和检查点
训练和评估代码
更多研究细节,可访问原博客。
以上就是号称击败Claude 3.5 Sonnet,媲美GPT-4o,开源多模态模型Molmo挑战Scaling law的详细内容,更多请关注其它相关文章!
# 越多
# 曲阜公司网站建设招标
# 厦门在哪建设网站
# 南京矩阵seo需要做吗
# 中小企业网站优化建议
# 宜地网站优化案例分析
# 营销小程序推广怎么样做
# 宣传片推广的网站叫什么
# 十堰seo网络推广软件
# 宁夏网站建设中
# 船营网站推广
# 最好的
# 首席执行官
# 就会
# 他们的
# 产业
# 万个
# 万张
# 的是
# 多模
# 开源
# type
# follow
# qwen
# claude
# gemini
# 处理器
# molmo
# ai2
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
昆仑万维与全球领先的元宇宙公司Meta达成商务合作,共同认可昆仑万维在XR领域的技术实力
AI新风口?首个高质量「文生视频」模型Zeroscope引发开源大战:最低8G显存可跑
视觉中国宣布推出AI灵感绘图、画面扩展功能
可按用户语气自动回复消息,Zoom 推出基于生成式 AI 的新功能
有 ARM 和 X86 两个版本,香橙派游戏掌机细节曝光
再度重仓 AI 赛道,SaaS 巨头 Salesforce 扩大 AIGC 风投基金规模
衡水市冀州中学机器人社团在世界机器人大赛中斩获佳绩
优化系统韧性:故障恢复与监控在RabbitMQ中的应用
中国气象局预测:到 2030 年,中国人工智能气象应用将达到国际领先水平
借助ChatGPT快速上手ElasticSearch dsl
消息称苹果 iPhone 15 系列健康应用将深度融合 AI 技术
精准度可提高 20%:英国九家银行签约使用基于 AI 的“消费者欺诈风险系统”应对*
马斯克预测:特斯拉全自动驾驶将在今年实现 对AI深度变化感到担忧
讯飞星火大模型实现升级 助力通用人工智能人才培养
SnapFusion技术大幅提升AI图像生成速度
Hugging Face发布了基于NASA卫星数据构建的AI地理空间基础模型
大模型的“黄金搭档”来了!腾讯云正式发布AI原生向量数据库,提供10亿级向量检索能力
朱民:普通人炒股炒不过机器人是很正常的 AI已经能理解市场情绪
微软在 Build 大会上宣布的新 Microsoft Store AI Hub 现已开始推出
全新“AI助手”!讯飞星火助手中心人机协作共创新生态
猿辅导发布最新SaaS业务进展公告:Motiff UI设计工具推出三项新的AI功能
清华朱军团队新作:使用4位整数训练Transformer,比FP16快2.2倍,提速35.1%,加速AGI到来!
AI大模型,将为智慧城市带来哪些新变化?
人工智能自己玩自己
卫星通信牵引物联网竞争升维,模组厂商如何决胜百亿市场?
2025世界人工智能大会(上海)开幕式纪要
微软更新服务协议,以防止通过AI服务进行逆向工程和数据抓取
支持跨语言、人声狗吠互换,仅利用最近邻的简单语音转换模型有多神奇
灯塔AI大模型票房预测上线:开源算法不断提升精准度
人工智能“Aria”现身 Opera浏览器100版本更新:新功能“标签岛”
自然语言生成在智能家居设备中的应用
企业软件行业更将被AI全面重构!Moka李国兴:未来优秀组织和个人将一定是善于使用AI生产力的
警惕!AI或致虚假信息泛滥
中国AI公有云市场2025年逆势蓬勃增长,增速高达80.6%
OpenAI 为开发者推出 GPT 聊天机器人 API 大更新,同时降低价格
Yann LeCun团队新研究成果:对自监督学习逆向工程,原来聚类是这样实现的
从医疗康复外骨骼到通用人形机器人,傅利叶智能推动核心技术升级
AI工具助力公司实施每周4.5天工作制,带来巨大效益
通用医疗人工智能如何革新医疗行业?
图像生成过程中遭「截胡」:稳定扩散的失败案例受四大因素影响
烟台大学学生首次在全国大学生无人机航拍竞赛中获奖
GPT-4不能在麻省理工学院获得计算机科学学位
人工智能快速发展 打开就业新空间
阿里达摩院向公众免费开放100项AI专利许可
一文读懂自动驾驶的激光雷达与视觉融合感知
AI行业盛会大咖云集!Sam Altam、“AI教父”......一文看懂最新观点
华为联合合作伙伴 共同发布昇腾AI大模型训推一体化解决方案
印象笔记开放旗下“印象 AI”,可一键生成思维导图、写文章等
优傲机器人的人机协作技术 助力中小企发展
英伟达的AI领域垄断地位:一直无法撼动吗?
2024-10-07

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
