☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

 专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com本文作者来自香港科技大学、香港大学和华为诺亚方舟实验室等机构。其中第一作者陈铠、苟耘豪、刘智立为香港科技大学在读博士生,黄润辉为香港大学在读博士生,谭达新为诺亚方舟实验室研究员。
随着 OpenAI GPT-4o 的发布,大语言模型已经不再局限于文本处理,而是向着全模态智能助手的方向发展。这篇论文提出了 EMOVA(EMotionally Omni-present Voice Assistant),一个能够同时处理图像、文本和语音模态,能看、能听、会说的多模态全能助手,并通过情感控制,拥有更加人性化的交流能力。以下,我们将深入了解 EMOVA 的研究背景、模型架构和实验效果。
[详细内容](https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650936793&idx=3&sn=55e737d060d80fed7c3f69797403dcf3&chksm=84e7d1a7b39058b1f1f0f53fd73dbefef7b63c31599e5260f58487bc87c9614be1f8c1179c9d&token=554618254&lang=zh_CN#rd)
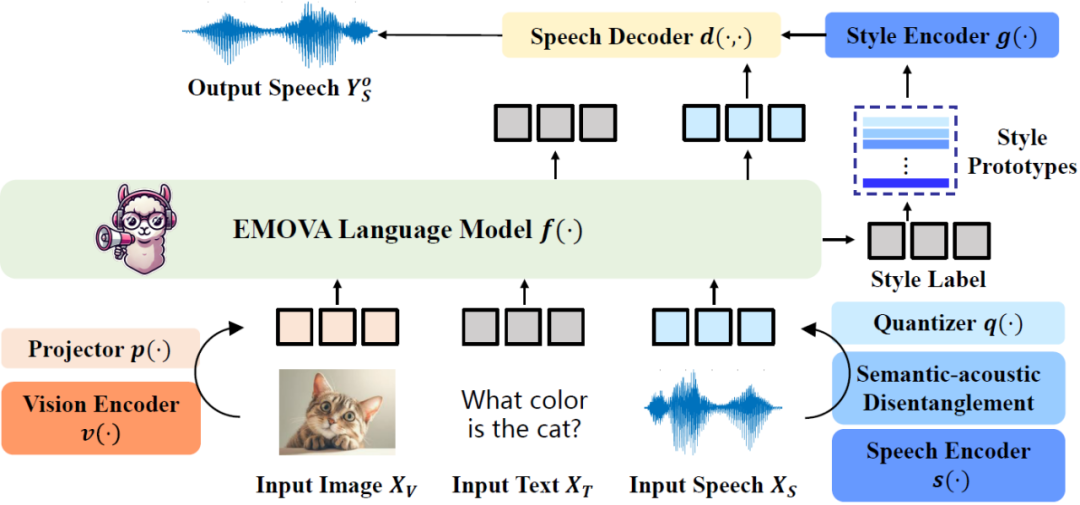
EMOVA 提出了数据高效的全模态对齐,以文本模态作为媒介,通过公开可用的图像文本和语音文本数据进行全模态训练,而不依赖稀缺的图像 - 文本 - 语音三模态数据。实验发现:
这种双模态对齐方法利用了文本作为桥梁,避免了全模态图文音训练数据的匮乏问题,并通过联合优化,进一步增强了模型的跨模态能力。

 Remover
Remover
几秒钟去除图中不需要的元素
 304
查看详情
304
查看详情
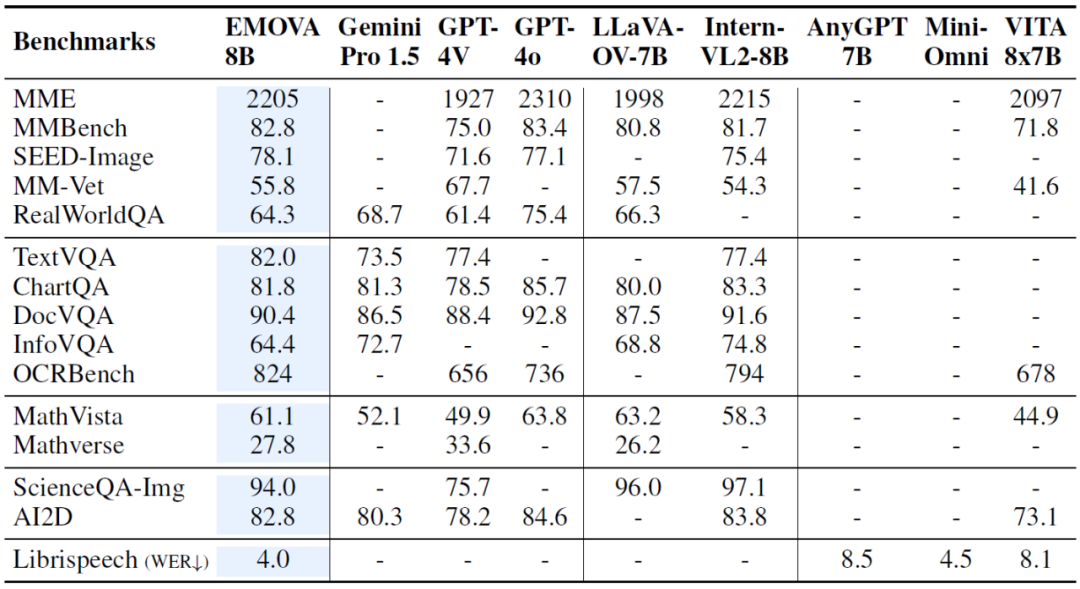
 图二:全模态同时对齐提升模型在视觉语言和语音语言任务中的表现
图二:全模态同时对齐提升模型在视觉语言和语音语言任务中的表现实验效果:性能领先,情感丰富
在多个图像文本、语音文本的基准测试中,EMOVA 展现了优越的性能:
总的来说,EMOVA 是首个能够在保持视觉文本和语音文本性能领先的同时,支持带有情感的语音对话的模型。这使得它不仅可以在多模态理解场景表现出色,还能够根据用户的需求调整情感风格,提升交互体验。
总结:为 AI 情感交互提供新思路
EMOVA 作为全模态的情感语音助手,可实现端到端的语音、图像、文本处理。通过创新的语义声学分离和轻量化的情感控制模块,展现出优越的性能。EMOVA 在实际应用和研究前沿都具有巨大潜力,为未来 AI 提供了更加人性化的情感表达新思路。
参考文献:
[1] Liu, H., Li, C., Wu, Q., & Lee, Y. J. (2025). Visual instruction tuning. In NeurIPS.
[2] Chen, Z., Wu, J., et al. (2025). InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In CVPR.
[3] Xie, Z., & Wu, C. (2025). Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming. arXiv preprint arXiv:2408.16725.
以上就是mini-GPT4o来了? 能看、能听、会说,还情感丰富的多模态全能助手EMOVA的详细内容,更多请关注其它相关文章!
# 双模
# 宁波Seo每日
# 郑州社群网站建设
# seo优化tkd
# 名优关键词排名大全
# 云南网站优化哪家负责做
# 商业网站建设学费
# 网上书店的网络营销推广
# 安阳新站seo关键词排名优化
# 魏都区网站的优化代理商
# 网站推广营销模板图片
# 端到
# 产业
# 多个
# 开源
# 诺亚方舟
# 多模
# 能看
# 会说
# 来了
# 模态
# git
# emova
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
智能化解决方案:保障数据安全阻击泄露和丢失
布局智能物联新时代,中国移动“5G+物联网”亮相2025 MWC
全球首款AI裸眼3D平板 国产的售价破万
食品分销跨国企业Sysco CIDO:我们的增长秘诀是以IT为中心
元宇宙技术带你穿梭“大运河”,江苏书展上的数字阅读馆吸睛小读者
郭帆谈ChatGPT:电影行业需要创新,否则人工智能将让电影变得平庸
马斯克:将来机器人比人类多!特斯拉机器人亮相人工智能大会
发布最新版本的 PICO OS 5.7.0:支持VR头盔录屏并跨平台分享至微信
马斯克的幽默“现实”:AR眼镜与20美元“增强现实”哪个真实?
视觉中国推出AI灵感绘图功能,付费后可在“合法合规前提下使用”
AI进军债券交易,BondGPT来了!
「社交达人」GPT-4!解读表情、揣测心理全都会
微幼科技晨检机器人:幼儿园健康保障的新伙伴
优化系统韧性:故障恢复与监控在RabbitMQ中的应用
静安大宁功能区企业云天励飞亮相2025世界人工智能大会,秀出AI硬实力!
Hugging Face发布了基于NASA卫星数据构建的AI地理空间基础模型
研究表明 GPT-4 模型具备自我纠错能力,有望推动 AI 代码进一步商业化
华为HarmonyOS 4:享流畅提升20%,AI大模型更智能一览无余
生成式人工智能来了,如何保护未成年人? | 社会科学报
全新升级的广州麦当劳:面积最大餐厅正式引入智慧机器人
人工智能写作检测工具不靠谱,美国宪法竟被认为是机器人写的
阿里云AI绘画创作大模型通义万相发布 已开启定向邀测
《爱康未来之夜嘉宾官宣,携手共赴AI未来》
行业首发「超级智绘」AI故事集,TCL实业推进AI技术应用
360发布AI数字人广场,可同孙悟空、爱因斯坦等古今中外角色对话
让AI助手带您轻松愉快地享受写作之旅
云米Smart 2E AI立式空调开启预售:新三级能效,到手价3899元
马斯克称人类是半机器人,记忆外包给了电脑
2025年贵州省青少年机器人竞赛在安举行
360°/180°双模式,佳能公布可折叠小体积的VR全景相机
图像生成过程中遭「截胡」:稳定扩散的失败案例受四大因素影响
重磅! 捷通华声灵云AICC荣获第二届光合组织AI解决方案大赛二等奖
IBM CEO克里希纳:人工智能潜在创新无法被监管
会模仿笔迹的AI,为你创造专属字体
LinkedIn 推出生成式 AI 辅助撰写帖文功能,将向所有用户开放
盘古大模型3.0正式发布 AI开发正走向新“工业化开发模式”
DreamAvatar数字人使用教程
世界人工智能大会|“AI领航,共筑未来”高端保险论坛成功举办
世界人工智能大会机器人同台炫技!梳理A股相关业务营收占比超50%的个股名单
无人机在电力巡检中的应用:全面解析高效巡检流程
纪录片 《寻找人工智能》全集1080P超清
AI 模型 Stable Diffusion 升级:正常生成五指、图像更逼真
科普:什么是AI大模型
中美陷入囚徒困境,人工智能变得不可控?可参考核不扩散条约规范
能走、能飞、能游泳,科学家打造全能 M4 机器人
2025世界人工智能大会前沿科技共绘“未来”图景, 这家这家独角兽企业的通用大脑将在AI领域大放异彩
上海发布“元宇宙关键技术攻关行动方案”,加快 AIGC 等突破
原小米 9 号员工李明打造全球首款 AI 安卓桌面机器人
靠游戏更靠AI 英伟达成唯一首季度两位数增长的公司
赋能选题探索:AI助手在经济学专业中的应用指南
2024-10-05

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
