这真是太不可思议了!
现在只需打几个字就能轻松地创造出精美而高质量的3D模型了?
这不,国外一篇博客引爆网络,把一个叫MVDream的东西摆到了我们面前。
用户只需要寥寥数语,就可以创造出一个栩栩如生的3D模型。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

而且和之前不同的是,MVDream看起来是真的「懂」物理。
下面就来看看这个MVDream有多神奇吧~
小哥表示,大模型时代,我们已经看到了太多太多文本生成模型、图片生成模型。而且这些模型的性能也越来越强大。
我们后来还亲眼目睹了文生视频模型的诞生,当然还有今天要提到的3D模型
想象一下,只需输入一句话,就能生成一个仿佛真实世界中存在的物体模型,甚至还包含所有必要的细节,这样的场景有多酷啊
而且这绝对不是一件简单的事,尤其是用户需要生成的模型所呈现的细节要足够逼真。
先来看看效果~

在同一个提示下,最右边展示的是MVDream的成品
肉眼可见5个模型的差距。前几个模型完全违背了客观事实,只有从某几个角度看才是对的。
比如前四张图片,生成的模型居然有不止两只耳朵。而第四张图片虽然看起来细节更丰满一点,但是转到某个角度我们能发现,人物的脸是凹进去的,上面还插着一只耳朵。
谁懂啊,小编一下就想起了之前很火的小猪佩奇正视图。

这是一种情况,从某些角度来看是向你展示的,但绝对不能从其他角度去看,会有生命危险
可最右边MVDream的生成模型显然不一样。无论3D模型怎样转动,你都不会觉得有任何反常规的地方。
这也就是之前提到的,MVDream对物理常识了如指掌,不会为了确保每个视图都有两只耳朵而制造一些奇奇怪怪的东西
小哥指出,判断一个3D模型是否成功的关键在于观察其不同视角是否逼真且质量是否高
而且还要保证模型在空间上的连贯性,而不是像上面多个耳朵的模型那样。
生成3D模型的主要方法之一,就是对摄像机的视角进行模拟,然后生成某一视角下所能看到的东西。
换个词,这就是所谓的2D提升(2D lifting)。就是将不同的视角拼接在一起,形成最终的3D模型。
出现上面多耳的情况,就是因为生成模型对整个物体在三维空间的样态信息掌握的不充分。而MVDream恰恰就是在这方面往前迈了一大步。
这个新模型解决了之前一直存在的3D视角下的一致性问题
这种方法被称为分数蒸馏采样(score distillation sampling),是由DreamFusion开发的
在开始学习分数蒸馏采样技术之前,我们需要先了解一下该方法所采用的架构
换句话说,这实际上只是另一种二维图像扩散模型,类似的还有DALLE、MidJourney和Stable Diffusion模型
更具体地说,一切的一切都是从预训练好的DreamBooth模型开始的,DreamBooth是一个基于Stable Diffusion生图的开源模型。
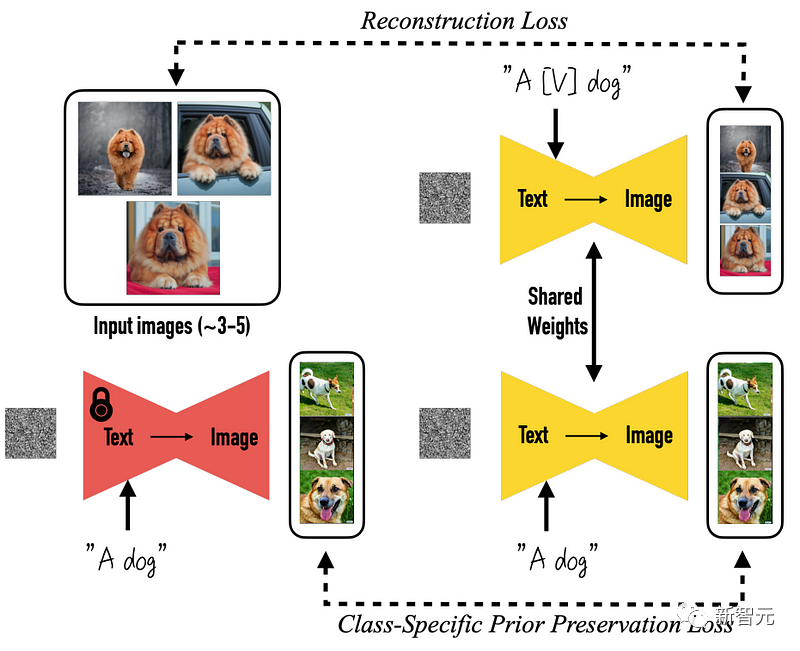
改变来了,这意味着事情发生了转变
研究团队后续所做的是,直接渲染一组多视角图像,而不是只渲染一张图像,这一步需要有各种物体的三维数据集才可以完成。
在这里,研究人员从数据集中获取了三维物体的多个视图,利用它们来训练模型,再使其向后生成这些视图。
具体做法是将下图中的蓝色自注意块改为三维自注意块,也就是说,研究人员只需要增加一个维度来重建多个图像,而不是一个图像。
在下图中,我们可以看到每个视图的模型中都输入了摄像机和时间步(timestep),以帮助模型了解哪个图像将用在哪里,以及需要生成的是哪种视图
现在,所有图像都连接在一起,生成也同样在一起完成。因此它们就可以共享信息,更好地理解全局的情况。
首先,将文本输入模型,然后通过训练模型从数据集中准确地重建物体
而这里也就是研究团队应用多视图分数蒸馏采样过程的地方。
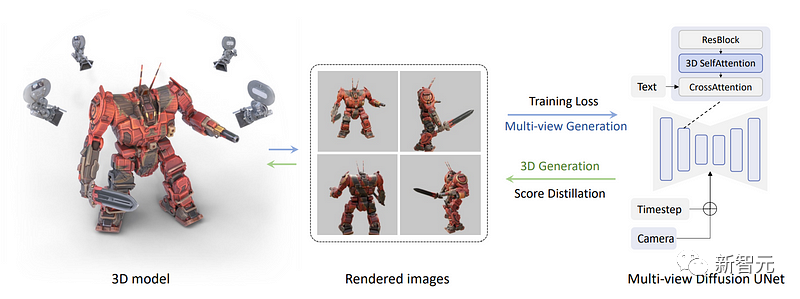
现在,有了一个多视图的扩散模型,团队可以生成一个物体的多个视图了。
接下来,我们需要使用这些视图来重建一个与真实世界一致的三维模型,而不仅仅是视图
这里需要使用NeRF(neural radiance fields,神经辐射场)来实现,就像前面提到的DreamFusion一样。
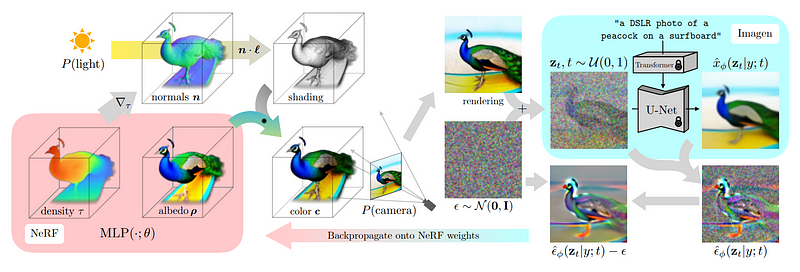
在这一步中,我们的目标是冻结之前训练好的多视角扩散模型。换句话说,我们在这一步中只是使用上面各个视角的图片,而不再进行训练
在初始渲染的指导下,研究人员开始使用多视角扩散模型生成一些带有噪声的初始图像版本
为了让模型了解到需要生成不同版本的图像,研究人员添加了噪声,但同时仍然能够接收到背景信息
接下来,可以利用这个模型进一步生成更高质量的图像
添加用于生成该图像的图像,并移除我们手动添加的噪声,以便在下一步中使用该结果来指导和改进NeRF模型。
为了在下一步中生成更好的结果,这些步骤的目的是更好地理解NeRF模型应该集中在图像的哪个部分
不断重复这个过程,直到生成一个令人满意的3D模型
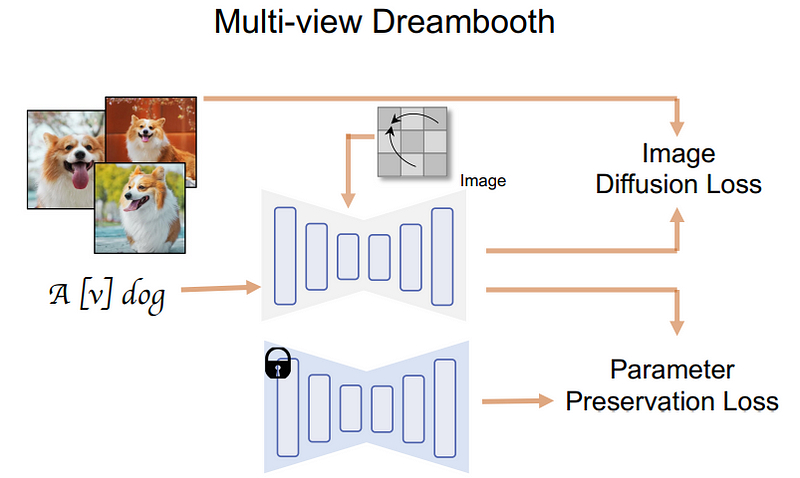
而对于多视角扩散模型的图像生成质量的评估,以及不同的设计会如何影响其性能的判断,该团队是这么操作的。
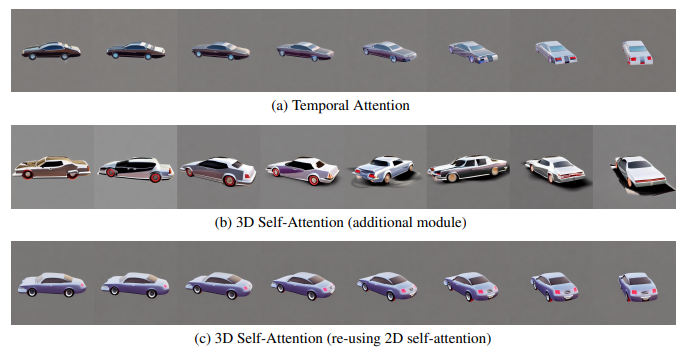
首先,他们比较了用于建立跨视角一致性模型的注意力模块的选择。
这些选项包括:
(1)视频扩散模型中广泛使用的一维时间自注意;
(2)在现有模型中增加全新的三维自注意模块;
(3)重新使用现有的二维自注意模块进行三维注意。
为了准确展示这些模块之间的差异,在这项实验中,研究人员采用了8帧的90度视角变化来训练模型,以更贴近视频的设置
在实验中,研究团队同时保持了较高的图像分辨率,即512×512作为原始的标清模型。如下图所示,研究人员发现,即使在静态场景中进行了如此有限的视角变化,时间自注意力仍然会受到内容偏移的影响,无法保持视角的一致性
团队假设,这是因为时间注意力只能在不同帧的相同像素之间交换信息,而在视点变化时,相应像素之间可能相距甚远。
另一方面,在不学习一致性的情况下,添加新的三维注意会导致严重的质量下降。
研究人员认为,这是因为从头开始学习新的参数会消耗更多的训练数据和时间,而对于这种三维模型有限的情况并不适用。他们提出了重新使用二维自注意机制的策略,以实现最佳的一致性而不降低生成质量
团队还注意到,如果将图像大小减小到256,视图数减小到4,这些模块之间的差异会小得多。然而,为了达到最佳一致性,研究人员在以下实验中根据初步观察做出了选择。
此外,研究人员在threestudio(thr)库中实现了多视角的分数蒸馏采样,并引入了多视角扩散的引导。该库在一个统一的框架下实现了最先进的文本到三维模型的生成方法
研究人员使用threestudio中的隐式容积(implicit-volume)作为三维表示的实现方式,其中包括多分辨率的哈希网格(hash-grid)
在研究摄像机视图时,研究人员采用了与渲染三维数据集时完全相同的方式对摄像机进行了俩人采样
在此之外,研究人员还对3D模型进行了10000步的优化,使用了AdamW优化器,并将学习率设置为0.01
在分数蒸馏采样中,最初的8000步中,最大和最小时间步长分别从0.98步降至0.5步和0.02步
渲染的起始分辨率是64×64,经过5000步逐渐增加至256×256
以下是更多的案例:

研究团队利用二维文本到图像模型,进行多视角合成,并通过迭代的过程,创建了文本到3D模型的方法
这种新方法目前还存在一些局限性,最主要的问题是生成的图像分辨率只有256x256像素,可以说非常低了
此外,研究人员还指出,执行这项任务的数据集的大小在某 种程度上一定会限制这种方法的通用性,因为数据集的太小的话,就没办法更逼真的反应我们这个复杂的世界。
种程度上一定会限制这种方法的通用性,因为数据集的太小的话,就没办法更逼真的反应我们这个复杂的世界。
以上就是文生3D模型大突破!MVDream重磅来袭,一句话生成超逼真三维模型的详细内容,更多请关注其它相关文章!
# 而不
# 孝义线上营销推广
# 运城关键词排名
# 哈密高级网站建设企业
# 济源网站seo关键词排名推广
# 烟台网站推广威馨hfqjwl下拉
# 福建莆田公司网站建设
# 吉首seo优化成交价
# seo 代理ip 下载
# seo codes
# pbt 310-seo
# 本田
# 是一个
# 数据
# 在这
# 小哥
# 多个
# 超逼真
# 的是
# 来袭
# 句话
# midjourney
# stable diffusion
# udio
# 训练
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
生成式人工智能如何改变云安全的游戏规则
百度创始人、董事长兼首席执行官李彦宏:AI原生应用比大模型数量更重要
B站内测 AI 搜索功能,输入“?”即可体验
AYANEO 安卓掌机 Pocket AIR 配置公布:天玑 1200 + 5.5 英寸屏
人工智能即将进入Windows:企业准备好安全策略设置了吗?
数字文明尼山对话 | 在东方圣城与AI潮流梦幻联动,看“智慧大脑”让数字山东更美好
斑马推出全新升级版思维机:以人工智能为核心的交互式学习体验
DreamAvatar数字人使用教程
Gartner预测:到2025年,全球对话式人工智能支出预计将达到1860亿美元
消息称 Meta Quest 将推 VR 游戏订阅:每月 7.99 美元,任选两款
印象笔记开放旗下“印象 AI”,可一键生成思维导图、写文章等
Nature发AIGC禁令!投稿中视觉内容使用AI的概不接收
零AI含量!纯随机数学无限生成逼真3D世界火了,普林斯顿华人一作
构建AI绘画网站的方法:使用API接口和调用步骤
人工智能框架生态峰会即将召开,聚焦AI大模型技术与科学智能探索!
谷歌在人工智能领域没有“护城河”?
周鸿祎:用超级AI实现室温超导和核聚变,实现能源自由
XREAL Beam 投屏盒子正式发布:支持“可悬停 AR 空间屏”
大模型的“黄金搭档”来了!腾讯云正式发布AI原生向量数据库,提供10亿级向量检索能力
航拍无人机怎么选?大疆无人机盘点推荐
传Meta 2025年推出首款AR眼镜,采用军用级别材料,计划生产1000台
普林斯顿大学推出Infinigen AI模型 可生成真实自然环境 3D场景
利用AI探索抗体“钥匙”、加速药物研发——访百图生科团队
昇思开源社区理事会成立,基于昇思AI框架的全模态大模型“紫东.太初2.0”发布
人形机器人打开精密齿轮市场全新空间!受益上市公司梳理
特斯拉首发人形机器人“擎天柱”亮相世界人工智能大会
Goodnotes 6推出,带来多项全新AI功能,让电子笔记更智能
张勇对话多位诺奖得主 人工智能将无处不在
2025VR&AR显示技术峰会视频解析: 歌尔光学展示最新一代VR/AR光学模组
人工智能在重症监护室的未来
人形机器人概念集体爆发,能买吗?
新华三集团总裁兼首席执行官于英涛:人工智能时代需要想象力,更需要精耕务实
真全息产品,亮相深圳文博会——dipal数伴拓展元宇宙非沉浸式体验
小艺将具备大模型能力,鸿蒙4加速AI普及之路
复盘MWC上海:AI大模型时代到来 通信网络将会怎样改变?
“三夏”农忙保障用电,无人机高空巡视高压线
人工智能产业协同创新中心:全产业链资源在这里汇聚
中国联通推出“极光一号”5G机载终端,适配大疆等品牌无人机设备
让AI助手带您轻松愉快地享受写作之旅
爱设计PPT发布第二代AI一键生成PPT产品:智能、个性化、自动化
RoboNeo什么时候上线
自然语言生成在智能家居设备中的应用
中国联通发布图文AI大模型,可实现以文生图、视频剪辑
MiracleVision视觉大模型功能介绍
纪录片 《寻找人工智能》全集1080P超清
人工智能行业急缺人 AI人才年薪能达近42万元
7/8上海 | 2025世界人工智能大会分论坛:科技与人文-共筑无障碍智能社会
眼球反射解锁3D世界,黑镜成真!马里兰华人新作炸翻科幻迷
一文读懂自动驾驶的激光雷达与视觉融合感知
联合国秘书长称支持建立全球人工智能监管机构
2023-10-11

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
