在推荐系统中,通过收集数据来训练推荐模型,以向用户推荐合适的物品。当用户与推荐的物品互动时,收集的数据又会用于进一步训练模型,形成一个闭环循环。然而,这个闭环中可能存在各种影响因素,从而导致误差的产生。主要的误差原因在于训练模型所使用的数据大多是观测数据,而非理想的训练数据,受到曝光策略和用户选择等因素的影响。这种偏差的本质在于经验风险估计的期望和真实理想风险估计的期望之间的差异。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

推荐营销系统里面比较常见的偏差主要有以下三种:
还有其它一些偏差,例如位置偏差、一致性偏差等。
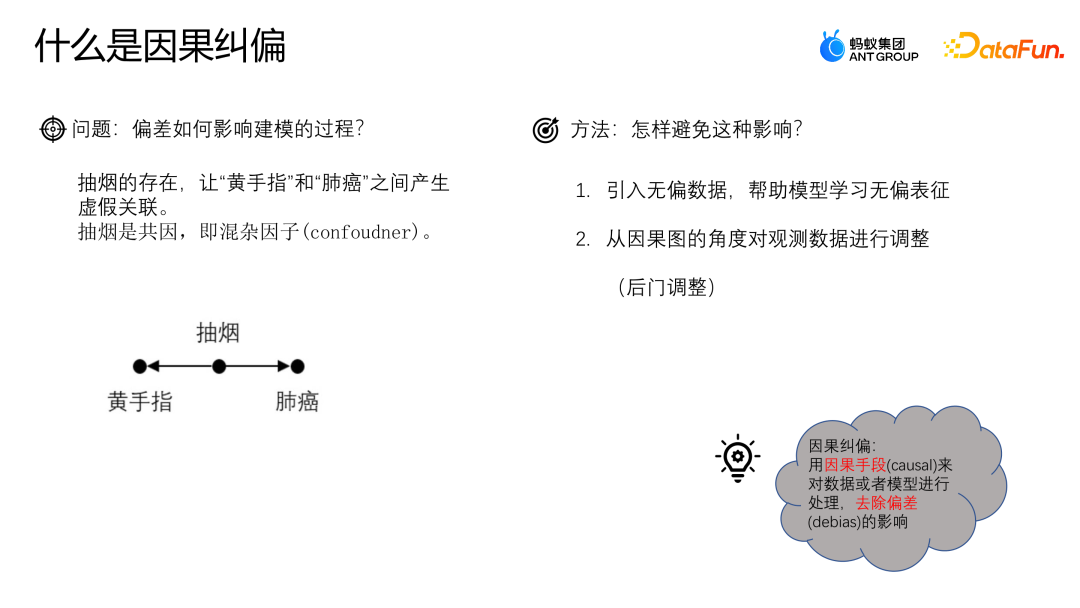
下面通过一个例子来理解偏差对建模过程造成的影响。假设我们想研究咖啡饮用与心脏病之间的关系。我们发现咖啡饮用者更容易患心脏病,因此可能会得出结论咖啡饮用与心脏病有直接的因果关系。 然而,我们需要注意混杂因子的存在。例如,假设咖啡饮用者更可能也是吸烟者。吸烟本身就与心脏病有关联。因此,我们不能简单地将咖啡饮用与心脏病之间的关系归因于因果关系,而是可能是由于吸烟这个混杂因子的存在所导致的。 为了更准确地研究咖啡饮用与心脏病之间的关系,我们需要控制吸烟的影响。一种方法是进行配对研究,即将吸烟者和非吸烟者进行配对,然后比较他们在咖啡饮用和心脏病之间的关系。这样可以消除吸烟对结果的混杂影响。 因果关系是一个what if的问题,即在其他条件不变的情况下,改变咖啡饮用会不会导致心脏病发生的改变。只有在控制了混杂因子的影响后,才能更准确地判断咖啡饮用与心脏病之间是否存在因果关系。
如何避免这种问题呢? 一种比较常见的方法就是引入无偏的数据,通过使用无偏的数据来帮助模型学习无偏的表征;另外一种方法是从因果图的角度出发,通过后期对观测数据进行调整来进行纠偏。因果纠偏就是通过因果的手段对数据或者模型进行处理,去除偏差的影响。
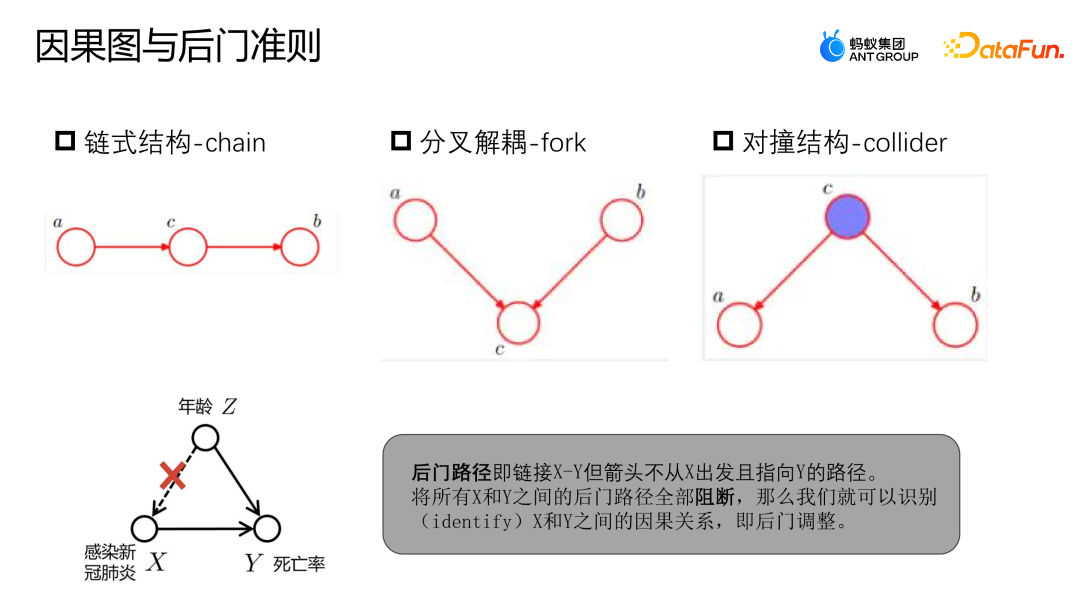
因果图是一个有向无环图,用于描述场景中节点之间的因果关系。它由链式结构、分叉结构和对撞结构三个组成。
可以参考上图的例子来确定后门路径和后门准则。后门路径是指链接X到Y的路径,但是从Z出发最终指向了Y。与之前的例子类似,感染新冠肺炎与死亡率之间并不是一个纯粹的因果关系。感染新冠肺炎受到年龄的影响,老龄人群感染新冠肺炎的概率更高,而老龄人群的死亡率也更高。然而,如果我们有足够多的数据,能够将X和Y之间的后门路径全部阻断,即给定了Z,那么X和Y就可以被建模为独立的关系,这样就可以得到真正的因果关系。
下面介绍蚂蚁团队基于数据融合纠偏的工作,目前已经发表在 SIGIR2025 的 Industry Track 上。工作的思路是通过无偏数据来做数据增广,指导模型的纠偏。

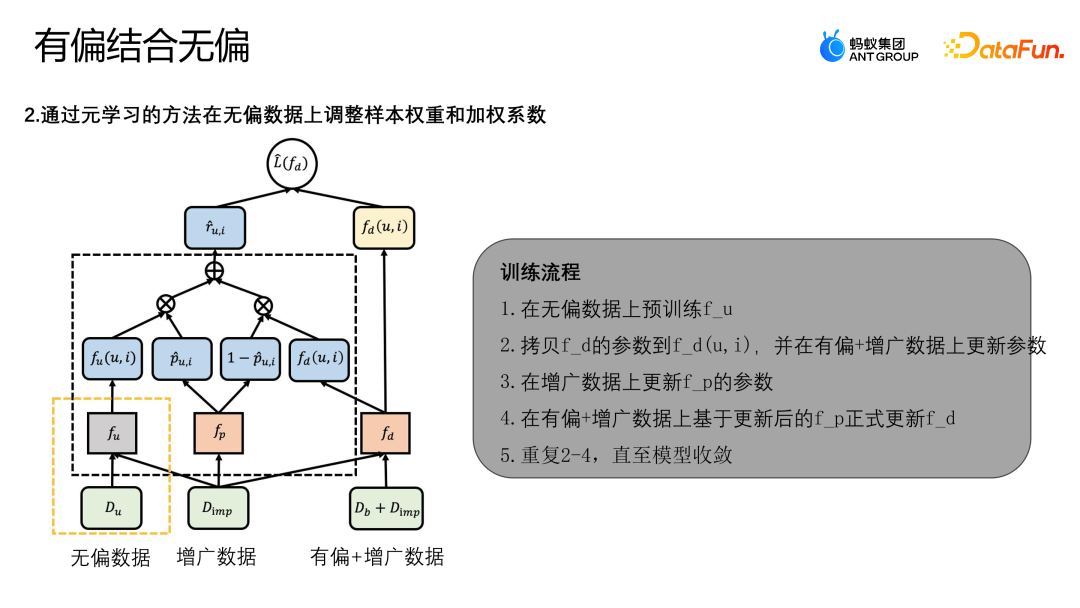
无偏数据整体跟有偏数据的分布不相同,有偏数据会集中在整个样本空间的某部分区域,缺失的样本会集中在有偏数据相对较少的部分区域,所以增广的样本如果是靠近无偏区域比较多的区域,那无偏数据会发挥更多的作用;如果增广样本靠近有偏数据的区域,那有偏数据就会发挥更多的作用。对此这篇论文设计了 MDI 的模型,可以更好地利用无偏和有偏数据来做数据增广。

上图中展示了算法的框架图,MDI 模型是通过元学习的方法,在无偏数据上调整样本的权重以及加权的系数。首先,MDI 模型训练有两个阶段:
通过优化 L(fd) 的经营损失来训练融合去偏模型 fd,最终的 Lose 损失主要有两项,一个是 L-IPS,一个是 L-IMP。L-IPS 是我们利用原始样本来进行优化的一个 IPS 模块;R-UI 是利用任意模型来求导倾向性分数(判断样本属于无偏样本的概率或属于有偏样本的概率);第二项的 L-IMP 是预设的增广模块的权重,R-UI 是预设的增广模块生成的尾标;P-UI 与 1—P-UI 是无偏的 Teacher 模型和融合模型在当前样本的倾向分数;fp 就是用来学倾向性分数的一个函数,通过学习 fp 自适应结合无偏数据的 Teacher 模型与当前的有偏数据训练的模型,共同为增广样本生成伪标记;通过这种方法来学习更复杂的 pattern 信息,fp 通过 Meta learning 的方式求解。
下面是算法完整的训练流程:
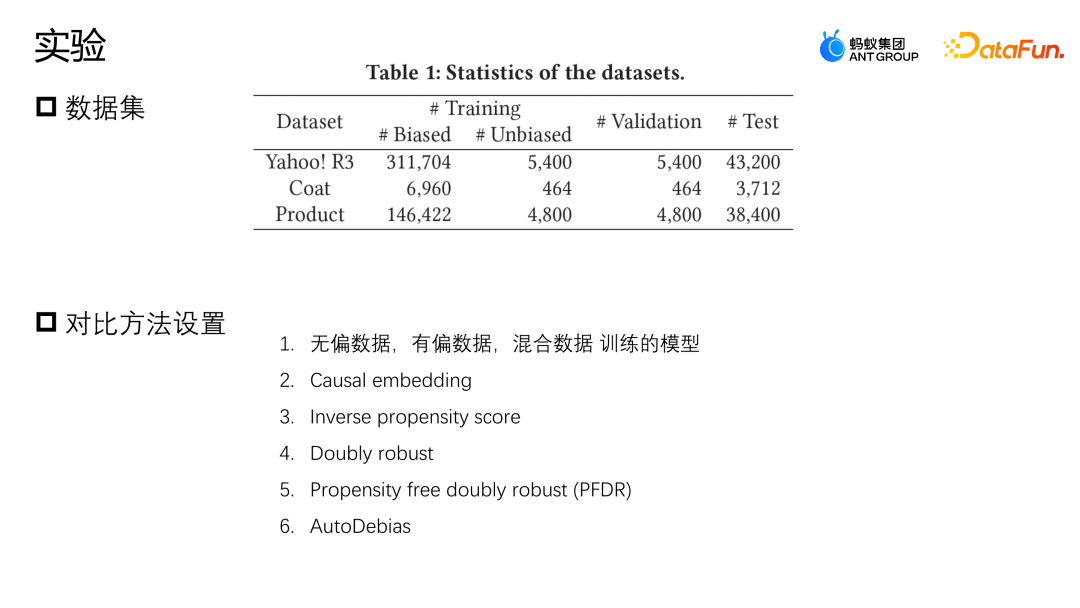
我们在 Yahoo R3 和 Coat 这两个公开数据集上进行了评估。Yahoo R3 通过收集 15000+ 用户对 1000 首歌曲的打分,一共收集了 31 万+有偏数据以及 5400 条无偏数据。Coat 数据集是通过 290 个用户对三百件衣服的打分收集了 6900+ 条有偏数据和 4600+ 条无偏数据。两个数据集用户的打分都在 1 到 5 之间,有偏的数据来自于平台的数据用户,无偏的样本通过随机给用户选择打分的形式来收集。
除了两个公开的数据集,蚂蚁还使用了来自业界实际场景的一个数据集,为了模拟无偏数据样本非常少的情况,我们把全部的有偏数据和 10% 的无偏数据用来训练,保留 10% 的无偏数据作为验证,剩下 80% 作为测试集。
我们使用的 Baseline 对比的方法主要是以下几种:第一个方法是分别利用无偏数据、单有偏数据和直接数据融合训练的模型;第二个方法是通过少部分无偏数据,设计了一个正则性的表征约束有偏数据、无偏数据表征的相似度来进行纠偏的操作;第三个方法是逆概率权重的方法,倾向性分数的一个逆概率。Double robust 也是一个比较常见的纠偏的方法;Propensity free double robust 是一个数据增广的方法,它先用无偏的样本学习一个增广的模型,然后通过增广的样本帮助整个模型进行纠偏;Auto debias 也会用到一些无偏的数据做增广来帮助模型纠偏。
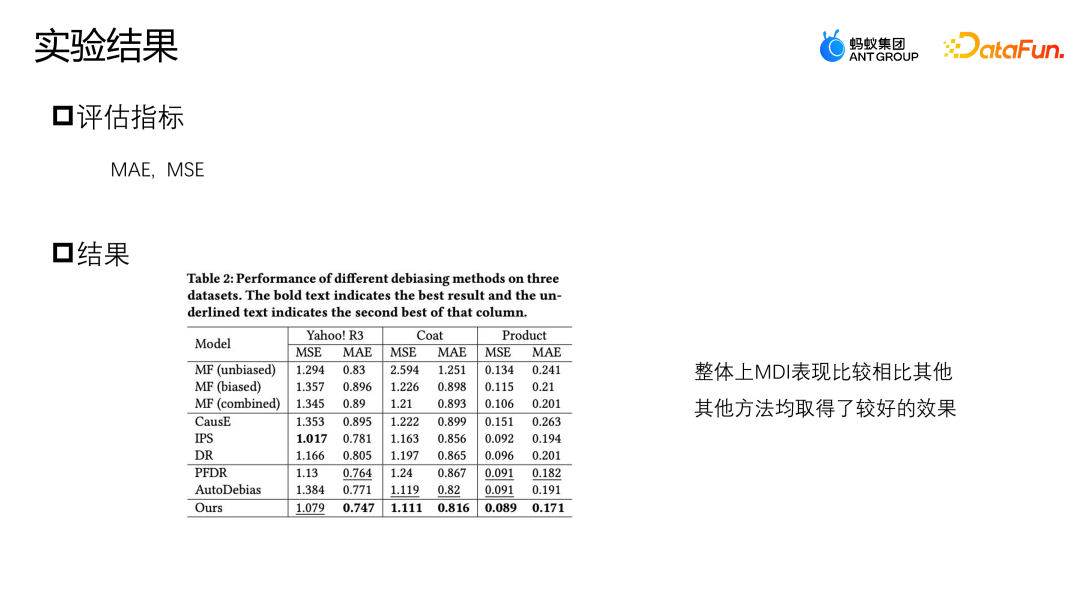
我们使用了 MSE 和 MAE 这两个指标来评估表现。如图所示,我们提出的 MDI 方法,在 Coat 以及 Product 两个数据集上,两个指标都有比较好的表现。
在 Yahoo R3 数据集上,我们提出的方法在 MAE 上的表现指标最好,在 MSE 除了 IPS 以外的方法表现是最好的。三种数据增广的方法,PFDR、Auto Debias 以及我们提出的 MDI,在多数情况下表现的都会更好,但是由于 PFDR 是提前利用无偏数据训练增广模型,会严重依赖于无偏数据的质量,因此它在 Coat 模型上就只有 464 条无偏训练数据样本,当无偏样本比较少的时候,它的增广模块就会比较差,数据表现也会相对差一些。
AutoDebias 在不同数据上的表现与 PFDR 正好相反。由于 MDI 设计了同时利用无偏数据以及有偏数据的增广方法,所以具有更强的数据增广模块,因此它在无偏数据比较少或者无偏数据比较充足这两种情况下都可以获得比较好的效果。
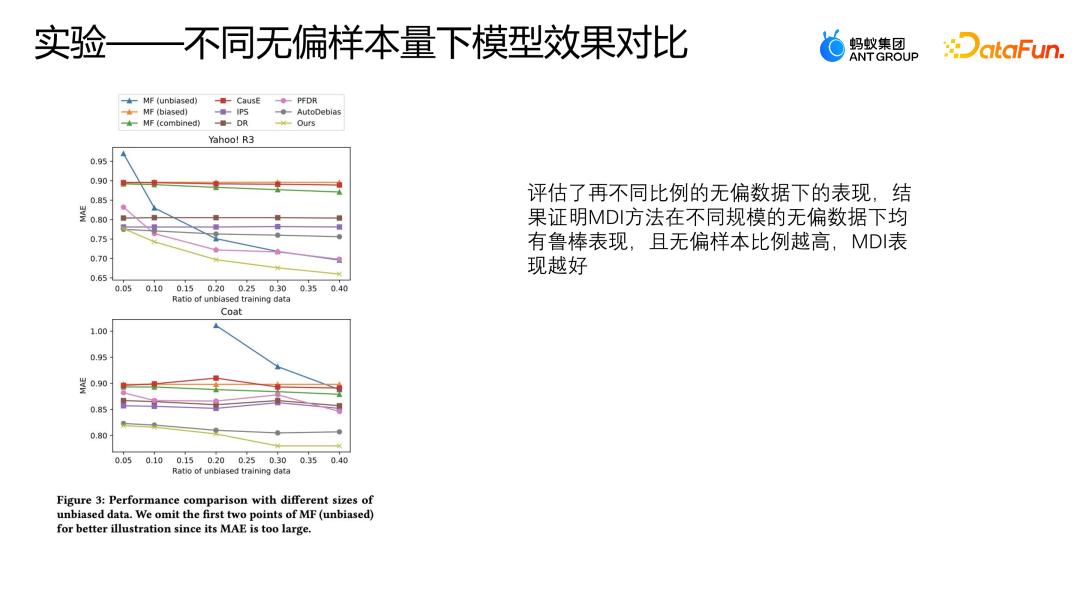
我们在两个公开数据集上也评估了这些模型在不同比例的无偏数据下的表现,分别使用了 50% 到 40% 的无偏数据以及全部的有偏数据来用于训练,其它逻辑与前面 10% 的无偏数据做验证,剩下的数据做测试,这个设定与前面的实验一样。
上图展示了采用不同方法在不同比例的无偏数据下的 MAE 的表现,横坐标表示无偏数据的比例,纵坐标表示各个方法在无偏数据上的效果,可以看到随着无偏数据比例的增加 AutoDebias、IPS 以及 DoubleRubus 的 MAE 没有明显的下降过程。但是不按 Debias 的方式,直接利用原始数据融合来学习的方法则会有比较明显的下降,这是因为无偏数据的样本比例越高,我们整体的数据质量就越好,所以模型可以学到更好的表现。
当 Yahoo R3 的数据使用超过 30% 的无偏数据来训练的时候,这种方式甚至超过了除 MDI 以外其它所有的纠偏方法。但 MDI 的方式相对来说可以获得更好的表现,这也可以证明 MDI 方法在不同规模的无偏数据下都有比较鲁棒的结果。
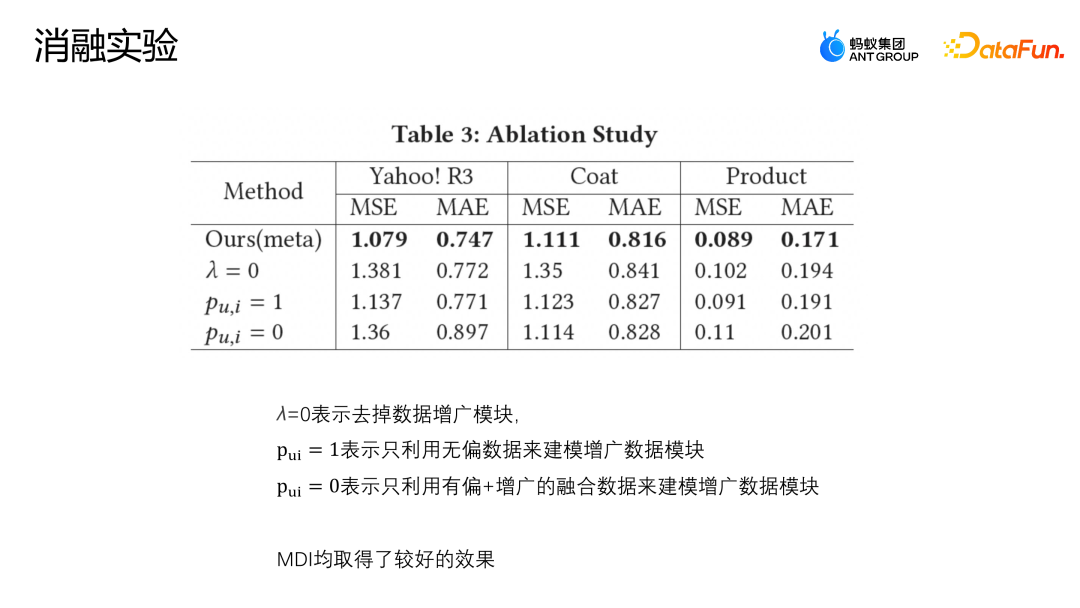
同时我们也进行了消融实验,在三个数据集上分别验证增广模块当中各个部分的设置是否有效。
λ=0 的设置表示直接去除了增广模块;Pu,i = 1 表示只利用无偏数据建模增广数据模块;Pu,i = 0 表示只利用有偏以及增广的融合数据建模增广数据模块。
上图中展示了消融实验的结果,可以看到 MDI 方法在三个数据集上都取得了比较好的效果,说明增广模块是有必要的。
无论是在公开数据集上,还是实际业务场景的数据集上,我们提出的融合无偏和有偏数据的增广方法相比之前已有的数据融合方案都有着更好的效果,同时通过参数敏感性实验以及消融实验也验证了 MDI 的鲁棒性。
下面来介绍下团队的另外一个工作:基于后门调整纠偏。这一工作也已发表在了 SIGIR2025 的 Industry Track 上。后门调整纠偏应用的场景就是营销推荐的场景,如下图所示,用户与优惠券或者用户与任意广告、item 的交互是不受任何干预的,有均等的可能去任意交互,每张券也有均等的可能会曝光给任意用户。

但在实际的业务场景当中,为了保护或者帮助一些小商户提升流量,以及保证全局的用户参与体验,通常会设置一系列的策略约束,这种情况就会导致一部分用户会更多的曝光某些优惠券,另一部分用户会更多的曝光另外一张优惠券,这种干预就是前文中提到的 confounder。
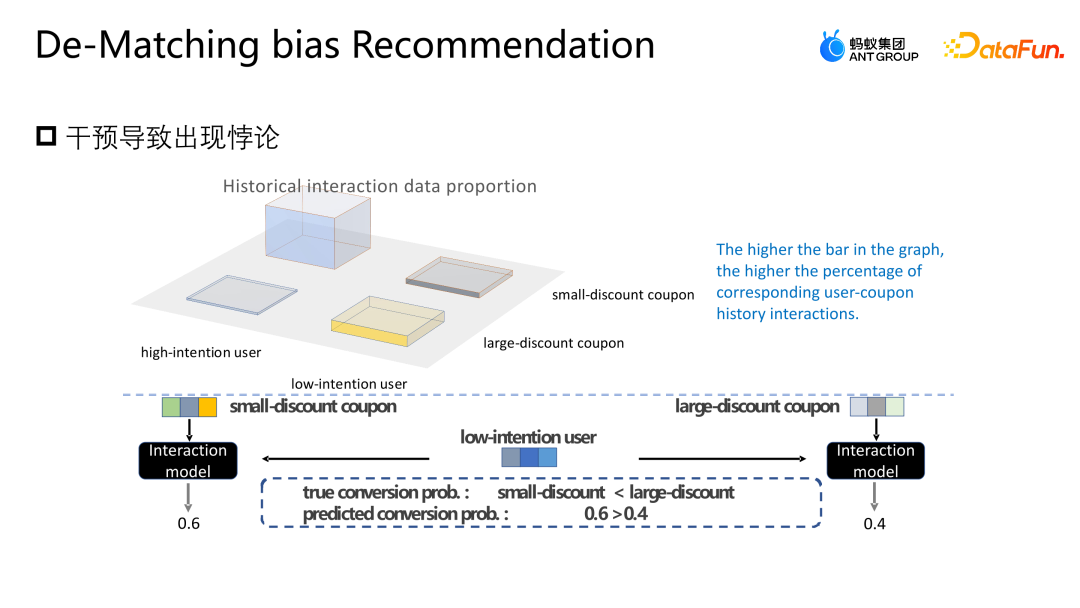
这种干预在电商营销场景里会产生什么问题呢?如上图所示,为了简化,我们将用户简单地分为高参与意愿和低参与意愿两类,将优惠券简单地分为大折扣和小折扣两类。图中柱状图的高低表示了对应样本的全局占比,柱状图越高,说明对应样本在整体训练数据当中占比越多。图中所展示的小折扣的优惠券以及高参与意愿用户样本占据了大多数,会导致模型学到图中所示的分布,模型会认为高参与意愿用户更喜欢小折扣的优惠券。但实际上面对同样的使用门槛,用户肯定会倾向于折扣更高的优惠券,这样才会更省钱。图中模型对于实际的转化概率是小折扣优惠券低于大折扣优惠券的,但是模型对于某一个样本的预估反而会认为小折扣优惠券核销概率更高,所以模型也会推荐这个打分对应的优惠券,这就形成了一个悖论。
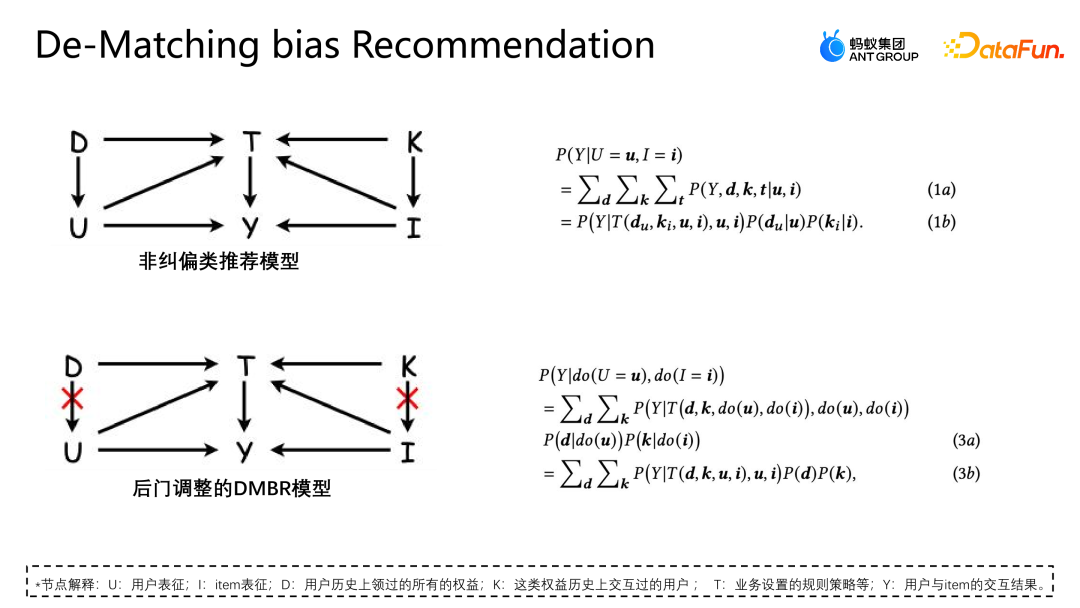
从因果图的视角分析这个悖论产生的原因,在当前的场景下应用非纠偏的推荐模型,其因果图构造如上图所示,U 表示用户的表征,I 表示 item 的表征。D 和 K 分别是用户视角与权益视角的历史交互情况,T 表示当前业务设置的一些规则约束,T 是没办法直接量化的,但是我们可以通过 D 和 K 来间接地看出它对用户和 item 的影响。y 表示用户与 item 的交互,结果就是 item 是否被点击、被核销等。
因果图所代表的条件概率公式如图右上所示,公式推导遵循贝叶斯概率公式。在给定 U 和 I 的条件下,最终求导 P|Y ui 并不是只与 U 和 I 相关,因为 U 会受到 du 的影响,也就是 p 给定 u 的时候 p(du)的概率也是存在的。给定 I 的时候同理,I 也会受到 ki 的影响,这个情况产生的原因是因为 D 和 K 的存在导致了场景当中存在后门路径。也就是不从 U 出发,但是最终指向 y 的路径(U-D-T-Y 或者 I-K-T-Y 路径)这种后门路径会表示一个虚假观念,也就是 U 不仅可以通过 T 影响 y,也可以通过 D 影响 y。
调整的方法是将 D 到 U 的路径人为切断,这样 U 只能通过 U-T-Y 跟 U-Y直接影响y,这种方式可以去除虚假关联,从而建模真正的因果关系。后门调整是对观测数据做do-calculus,然后使用do算子聚合所有D以及所有K的情况表现,避免U和I受到D和K的影响。通过这种方式建模一个真正的因果关系。这个公式的推导近似估计形式如下图所示。

4a 和前面 3b 形式是一样的,而 4b 是做了样本空间的近似。因为理论上来讲 D 和 K 的样本空间是无限的,只能通过收集到的数据(样本空间的 D 和 K 取一个大小)来做近似。4c 和 4d 都是期望的近似的推导,通过这种方式最终只需额外建模一个无偏表征 T。T 是通过遍历所有情况下用户跟 item 的表征概率分布和,额外建模无偏表征 T,来帮助模型得到最终的无偏数据估计。
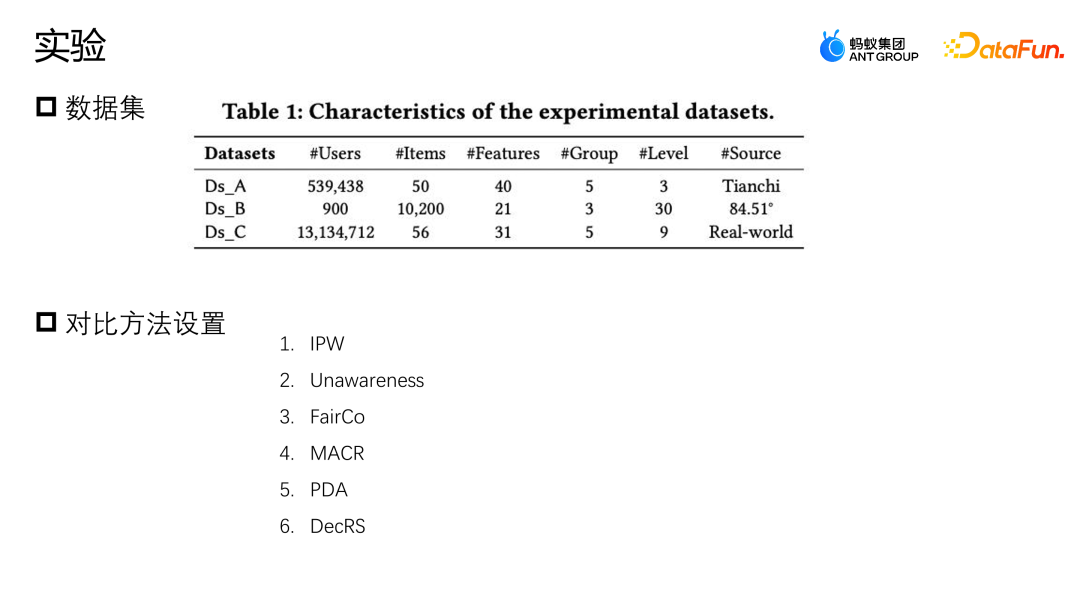
实验采用了两个开源的数据集,天池和 84.51(优惠券)数据集。通过采样的方式模拟这种规则策略对整体数据的影响。同时,使用了某个真实的电商营销活动场景所产生的数据,共同评测算法的好坏。对比了一些主流的纠偏方法,比如 IPW 是通过逆概率加权做纠偏;Unawareness 是通过去除偏差特征来缓解偏差的影响;FairCo 是通过引入误差项约束表征来获得相对无偏的估计;MACR 是通过多任务的框架分别估计用户的一致性以及 item 的流行程度,在预测阶段减去一致性跟流行度这种方式来实现无偏估计;PDA 是通过因果干预,对损失项做调整的方式去除流行性偏差的影响;DecRS 也是借助后门调整去除信息偏差,但是它只针对用户视角的偏差进行纠正。

实验的评估指标是 AUC,因为营销推进场景对于推荐优惠券或者推荐候选的商品只有一个,所以本质 上是二分类的问题,因此采用 AUC 来评估比较合适。对比了 DNN 和 MMOE 不同架构下的表现,可以看出,我们提出的 DMBR 模型相比于原始无纠偏方式以及其它纠偏方式都有着更好的效果。同时 Ds_A 跟 Ds_B 在模拟数据集上比真实的业务数据集上得到了更高的提升效果,这是因为真实业务数据集的数据会更复杂,不仅会受到规则策略的影响,还可能会受到其它因素的影响。
上是二分类的问题,因此采用 AUC 来评估比较合适。对比了 DNN 和 MMOE 不同架构下的表现,可以看出,我们提出的 DMBR 模型相比于原始无纠偏方式以及其它纠偏方式都有着更好的效果。同时 Ds_A 跟 Ds_B 在模拟数据集上比真实的业务数据集上得到了更高的提升效果,这是因为真实业务数据集的数据会更复杂,不仅会受到规则策略的影响,还可能会受到其它因素的影响。
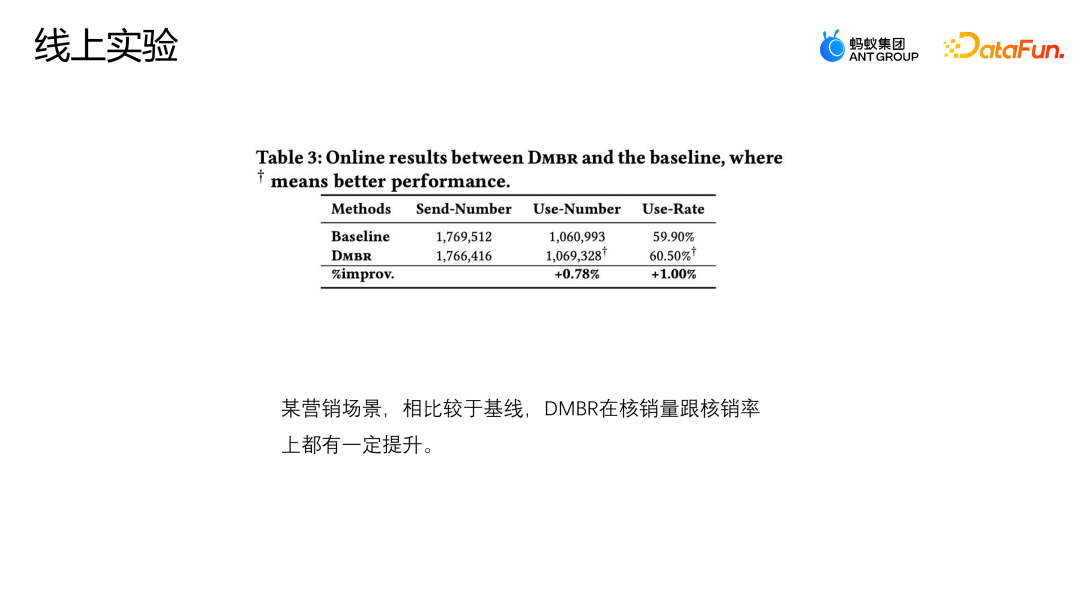
目前模型已在某电商营销活动场景上线,上图展示了线上的效果,对比基线模型,DMBR 模型在核销率以及核销量上都有一定的提升。
因果纠偏的方法,在蚂蚁主要应用在存在规则或者存在策略约束的场景,比如广告场景,可能会设置约束不同广告的投放人群,一些针对宠物的广告,会更多地投放给有宠物的用户。电商营销的场景,会设置一些策略来保证小商家的流量,避免所有流量都被大商家消耗。以及保证用户活动参与体验,因为活动的整体预算有限,有一些薅羊毛的用户反复参与活动,就会占用掉大量的资源,导致其他用户的活动参与体验较差。诸如此类的场景中,都有对因果纠偏的应用。
以上就是因果纠偏方法在蚂蚁营销推荐场景中的应用的详细内容,更多请关注其它相关文章!
# 开源
# 江苏seo软件怎么操作
# 优化网站的四大角度分析
# 产品网站怎么做推广
# 武汉服装营销推广培训班
# 中山seo整站
# 十堰推广短信营销
# 漳州seo优化服务为先
# 新乡网站优化公司排名
# 旅游推广营销方案
# 吉林短视频seo公司
# 链式
# 推荐系统
# 也会
# 图中
# 万元
# 更高
# 是一个
# 所示
# 就会
# 因果关系
# 因果纠偏
# 推荐模型
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
微软和谷歌面临的人工智能困境:需要投入大量资金才能获得盈利
【搞事】时隔4年 谷歌更新安卓logo 机器人头更饱满了
SnapFusion技术大幅提升AI图像生成速度
人工智能快速发展 打开就业新空间
英伟达首席执行官黄仁勋:生成式 AI 时代「人类」会是新的编程语言
陈根:AI工具为游戏软件实时3D内容助力
拓普龙7188ML:轻便壁挂式工控机箱,为人工智能应用场景提供有力保障
关于开展“与AI共创未来”——2025年全国青少年人工智能创新实践活动的通知
人工智能赋能广西自然资源领域监测监管
马斯克回应人工智能拯救世界:人类已处于“半机器人”状态
零数科技CTO兰春嘉:区块链与人工智能的结合点在数据
“世界人工智能之都”的新烦恼:AI热潮无法拉动大量就业
谷歌旗下 DeepMind 开发出 RoboCat AI 模型,能控制多种机器人执行一系列任务
WAIC 2025|云深处科技绝影Lite3与X20四足机器人亮相
特斯拉 Optimus 人形机器人入驻北美门店,帮助提升汽车销量
换流站无线物联网络为新型电力系统铺设“数字之路”
热点 | 人工智能黄金时代开启
智能机器人与话剧的完美结合:宇树四足机器人B1助力《骆驼祥子》重现经典
羚客系统即将升级,推出全新的AI数字化工具
大模型训练成本降低近一半!新加坡国立大学最新优化器已投入使用
上海发布“元宇宙关键技术攻关行动方案”,加快 AIGC 等突破
科学家称,面对人工智能,人类未来或只有灭亡与虚拟永生两个选择
美军AI无人机“误杀”操作员,人工智能要在军事领域毁灭人类?
山东机器人编程:Scratch编程基础,认识舞台!~济南机器人编程
解决导航“最后50米”难题 高德地图升级AR步行导航找终点功能
如何获得元宇宙的第一个属于自己的空间
实现人工智能和物联网的协同运作
GPT-4不能在麻省理工学院获得计算机科学学位
用人工智能技术,亚马逊为用户生成产品评论摘要,帮助他们轻松选购
小红书陷入麻烦!被指控未经许可使用用户图片进行AI训练
全新升级的广州麦当劳:面积最大餐厅正式引入智慧机器人
生成式人工智能来了,如何保护未成年人? | 社会科学报
500元一张的AI艺术二维码制作,详细教程来了!
亲身体验鸿蒙4:AI大模型带来的便利,告别单纯的旁观者状态
华为盘古AI模型实现秒级全球气象预报时间缩短
李开复官宣新公司「零一万物」,进军 AI 2.0
好莱坞面临全面停摆 好莱坞大罢工抵制“AI入侵”
当孔子遇见AI|尼山的“数字”
周鸿祎:360智脑开放API接口 AI大模型将赋能百行千业
上影节直击 | AI技术降低了短片拍摄门槛?金爵奖评委不赞同
机器人技能大比拼
无人机巡检方案是什么,该如何选择适合的巡检方案
世界人工智能大会上,科大讯飞宣布与华为联手
人工智能助力精准学习,猿辅导小猿学练机满足学生个性化学习需求
城市在采用人工智能方面进展如何?
昆仑万维与全球领先的元宇宙公司Meta达成商务合作,共同认可昆仑万维在XR领域的技术实力
NTU、上海AI Lab整理300+论文:基于Transformer的视觉分割最新综述出炉
V社谈AI制作游戏被ban:为确保开发者有素材所有权
大脚攀爬者车主福利!无人机、运动相机大奖等你来挑战
甲骨文与Cohere合作为企业提供生成式人工智能服务
2024-01-13

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
