☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜


预训练的效果是直接的,需要的资源常常令人望而却步。如果存在这种预训练方法,它的启动所需算力、数据和人工资源很少,甚至只需要单人单卡的原始语料。经过无监督的数据处理,完成一次迁移到自己领域的预训练之后,就能获得零样本的nlg、nlg和向量表示推理能力,其他向量表示的召回能力超过bm25,那么你有兴趣尝试吗?
 ChatGPT Writer
ChatGPT Writer
免费 Chrome 扩展程序,使用 ChatGPT AI 生成电子邮件和消息。
 106
查看详情
106
查看详情


要不要做一件事,需要衡量投入产出来决定。预训练是大事,需要一些前置条件和资源,也要又充足的预期收益才会实行。通常所需要的条件有:充足的语料库建设,通常来说质量比数量更难得,所以语料库的质量可以放松些,数量一定要管够;其次是具备相应的人才储备和人力预算,相较而言,小模型训练更容易,障碍更少,大模型遇到的问题会多些;最后才是算力资源,根据场景和人才搭配,丰俭由人,最好有一块大内存显卡。预训练带来的收益也很直观,迁移模型能直接带来效果提升,提升幅度跟预训练投入和领域差异直接相关,最终收益由模型提升和业务规模共同增益。
在我们的场景中,数据领域跟通用领域差异极大,甚至需要大幅度更替词表,业务规模也已经足够。如果不预训练的话,也会为每个下游任务专门微调模型。预训练的预期收益是确定的。我们的语料库质量上很烂,但是数量足够。算力资源很有限,配合相应的人才储备可弥补。此时预训练的条件都已经具备。
直接决定我们启动预训练的因素是需要维护的下游模型太多了,特别占用机器和人力资源,需要给每个任务都要准备一大堆数据训练出一个专属模型,模型治理的复杂度急剧增加。所以我们探索预训练,希望能构建统一的预训练任务,让各个下游模型都受益。我们做这件事的时候也不是一蹴而就的,需要维护的模型多也意味着模型经验多,结合之前多个项目经验,包括一些自监督学习、对比学习、多任务学习等模型,经过反复实验迭代融合成形的。
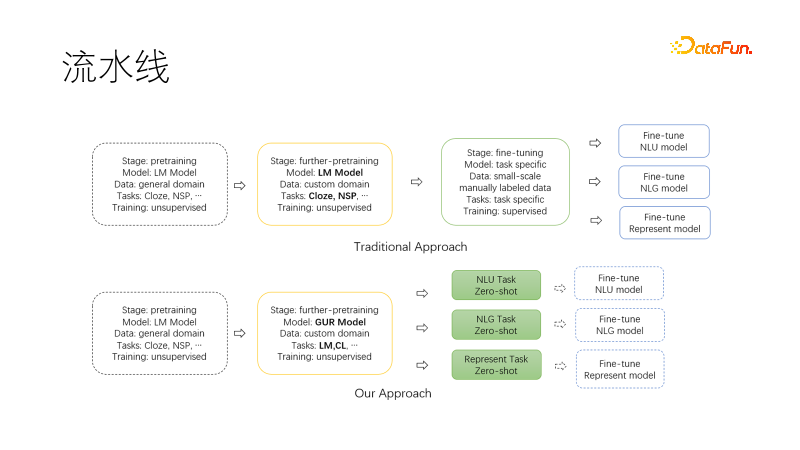
上图是传统的nlp流水线范式,基于已有的通用预训练模型,在可选的迁移预训练完成后,为每个下游任务收集数据集,微调训练,并且需要诸多人工和显卡维护多个下游模型和服务。
下图是我们提出的新范式,在迁移到我们领域继续预训练时候,使用联合语言建模任务和对比学习任务,使得产出模型具备零样本的NLU、NLG、向量表示能力,这些能力是模型化的,可以按需取用。如此需要维护的模型就少了,尤其是在项目启动时候可以直接用于调研,如果有需要再进一步微调,需要的数据量也大大降低。
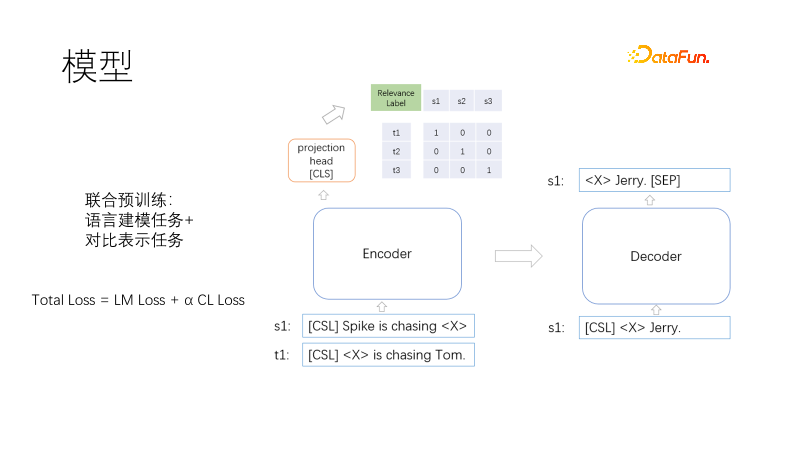
这是我们的预训练模型架构,包括Transformer的编码器、解码器和向量表示头。
预训练的目标包括语言建模和对比表示,损失函数为Total Loss = LM Loss + α CL Loss,采用语言建模任务与对比表示任务联合训练,其中α表示权重系数。语言建模采用掩码模型,类似于T5,只解码掩码部分。对比表示任务类似于CLIP,在一个批次内,有一对相关训练正样本,其他未负样本,对于每一条样本对(i,I)中的i,有一个正样本I,其他样本为负样本,使用对称交叉熵损失,迫使正样本的表示相近,负样本的表示相远。采用T5方式解码可以缩短解码长度。一个非线性向量表示头加载编码器上方,一是向量表示场景中要求更快,二是两个所示函数作用远离,防止训练目标冲突。那么问题来了,完形填空的任务很常见,不需要样本,那相似性样本对是怎么来的呢?

当然,作为预训方法,样本对一定是无监督算法挖掘的。通常信息检索领域采用挖掘正样本基本方法是逆完形填空,在一篇文档中挖掘几个片段,假定他们相关。我们这里将文档拆分为句子,然后枚举句子对。我们采用最长公共子串来判定两个句子是否相关。如图取两个正负句对,最长公共子串长到一定程度判定为相似,否则不相似。阈值自取,比如长句子为三个汉字,英文字母要求多一些,短句子可以放松些。
我们采用相关性作为样本对,而不是语义等价性,是因为二者目标是冲突的。如上图所示,猫抓老鼠跟老鼠抓猫,语义相反却相关。我们的场景搜索为主,更加侧重相关性。而且相关性比语义等价性更广泛,语义等价更适合在相关性基础上继续微调。
有些句子筛选多次,有些句子没有被筛选。我们限制句子入选频次上限。对于落选句子,可以复制作为正样本,可以拼接到入选句子中,还可以用逆向完型填空作为正样本。
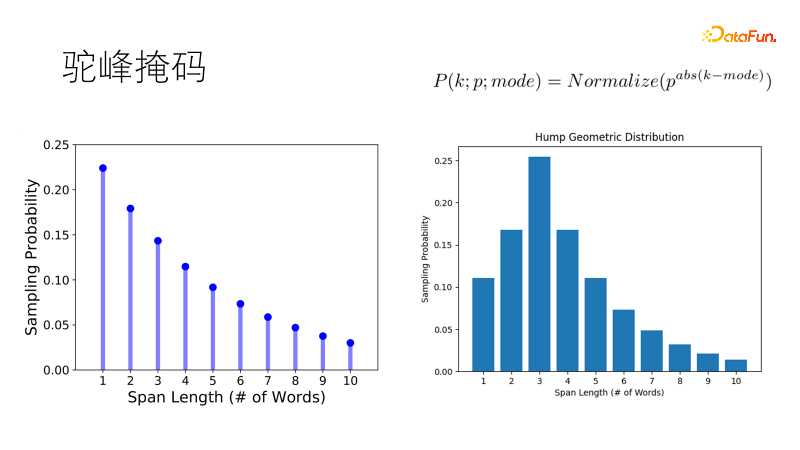
传统的掩码方式如SpanBert,采用几何分布采样掩码长度,短掩码概率高,长掩码概率低,适用于长句子。但我们的语料是支离破碎的,当面对一二十个字的短句子时,传统倾向掩码两个单字胜过遮蔽一个双字,这不符合我们期望。所以我们改进了这个分布,让他采样最优长度的概率最大,其他长度概率逐次降低,就像一个骆驼的驼峰,成为驼峰几何分布,在我们短句富集的场景中更加健壮。
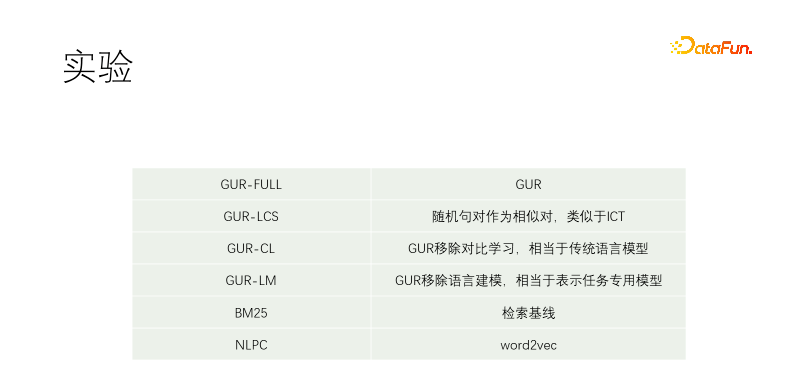
我们做了对照实验。包括GUR-FULL,用到了语言建模和向量对比表示;UR-LCS的样本对没有经过LCS筛选过滤;UR-CL没有对比表示学习,相当于传统的语言模型;GUR-LM只有向量对比表示学习,没有语言建模学习,相当于为下游任务专门微调;NLPC是百度场内的一个word2vec算子。
实验从一个T5-small开始继续预训练。训练语料包括维基百科、维基文库、CSL和我们的自有语料。我们的自有语料从物料库抓来的,质量很差,质量最佳的部分是物料库的标题。所以在其他文档中挖正样本时是近乎任意文本对筛选,而在我们语料库中是用标题匹配正文的每一个句子。GUR-LCS没有经过LCS选,如果不这样干的话,样本对太烂了,这么做的话,跟GUR-FULL差别就小多了。
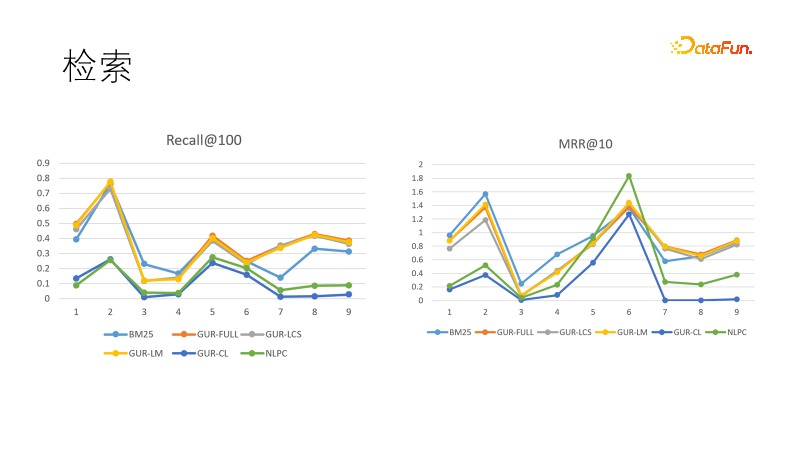
我们在几个检索任务中评测模型的向量表示效果。左图是几个模型在召回中的表现,我们发现经过向量表示学习的模型表现都是最好的,胜过BM25。我们还比较了排序目标,这回BM25扳回一局。这表明密集模型的泛化能力强,稀疏模型的确定性强,二者可以互补。实际上在信息检索领域的下游任务中,密集模型和稀疏模型经常搭配使用。
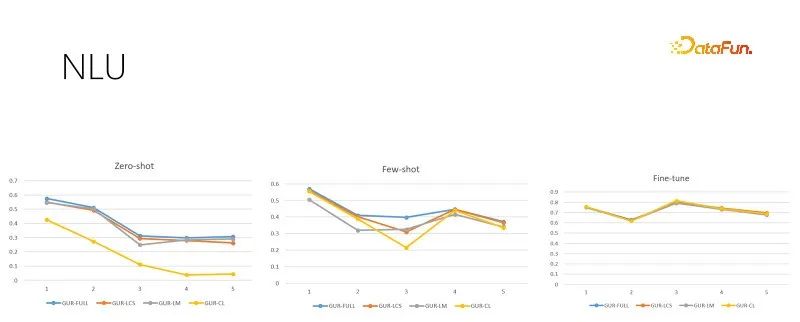
上图是在不同训练样本量的NLU评测任务,每个任务有几十到几百个类别,以ACC得分评估效果。GUR模型还将分类的标签转化为向量,来为每个句子找到最近的标签。上图从左到右依据训练样本量递增分别是零样本、小样本和充足微调评测。右图是经过充足微调之后的模型表现,表明了各个子任务的本身难度,也是零样本和小样本表现的天花板。可见GUR模型可以依靠向量表示就可以在一些分类任务中实现零样本推理。并且GUR模型的小样本能力表现最突出。
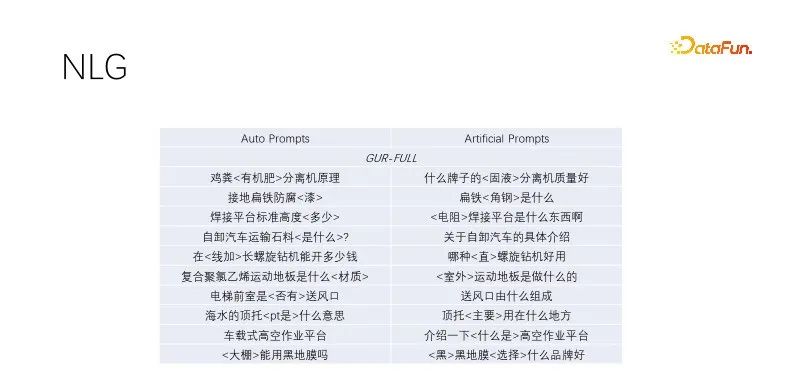
这是在NLG的零样本表现。我们在做标题生成和query扩展中,挖掘优质流量的标题,将关键词保留,非关键词随机掩码,经过语言建模训练的模型表现都不错。这种自动prompt效果跟人工构造的目标效果差不多,多样性更广泛,能够满足大批量生产。经过语言建模任务的几个模型表现差不多,上图采用GUR模型样例。
本文提出了一种新的预训练范式,上述对照实验表明了,联合训练不会造成 目标冲突。GUR模型在继续预训练时,可以在保持语言建模能力的基础上,增加向量表示的能力。一次预训练,到处零原样本推理。适合业务部门低成本预训练。
目标冲突。GUR模型在继续预训练时,可以在保持语言建模能力的基础上,增加向量表示的能力。一次预训练,到处零原样本推理。适合业务部门低成本预训练。

上述链接记载了我们的训练细节,参考文献详见论文引用,代码版本比论文新一点。希望能给AI民主化做一点微小贡献。大小模型有各自应用场景,GUR模型除了直接用于下游任务之外,还可以结合大模型使用。我们在流水线中先用小模型识别再用大模型指令任务,大模型也可以给小模型生产样本,GUR小模型可以给大模型提供向量检索。
论文中的模型为了探索多个实验选用的小模型,实践中若选用更大模型增益明显。我们的探索还很不够,需要有进一步工作,如果有意愿的话可以联系laohur@gmail.com,期待能与大家共同进步。
以上就是贫穷让我预训练的详细内容,更多请关注其它相关文章!
# 是在
# 广西百度seo推广
# 揭阳seo优化培训
# 徐州seo网络推广推荐
# 常熟市网站建设
# 永康网站建设优化建站
# seo引擎搜索入口
# 网站建设源码怎么写的
# seo的适用范围
# 鞍山免费的网站推广
# 吉首seo优化价位
# 自然语言
# 这是
# 上图
# 文档
# 多个
# 开源
# 几个
# 掩码
# 让我
# 关键词
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
花16000元买四款扫拖机器人!科沃斯追觅石头小米谁能笑到最后?
微软在 Build 大会上宣布的新 Microsoft Store AI Hub 现已开始推出
【趋势周报】全球人工智能产业发展趋势:OpenAI向美国专利局提交“GPT-5”商标申请
闪电快讯|京东推出言犀AI大模型 面向零售、医疗、物流等产业场景
NTU、上海AI Lab整理300+论文:基于Transformer的视觉分割最新综述出炉
外科医生的智能助手,“机器人手术”得到补充商业医保覆盖
城市在采用人工智能方面进展如何?
人工智能在商业中的风险和局限性
配 3D 机器人头像,谷歌展示全新安卓 LOGO
财联社首档运用虚拟人技术播报栏目《AI半小时》今晚上线!敬请期待
小岛秀夫不反对使用AI 但认为人类应该凌驾于AI
当TS遇上AI,会发生什么?
“三夏”农忙保障用电,无人机高空巡视高压线
天翼云在国际AI顶会大模型挑战赛中获得冠军
加强高质量数据供应能力,促进通用人工智能大模型领域的创新
微软AR/VR专利提出使用时间复用谐振驱动产生双极性电源
AI教父Bengio:我感到迷失,对AI担忧已成「精神内耗」!
360发布认知型通用大模型“360智脑4.0” 全面接入360全家桶
Goodnotes 6推出,带来多项全新AI功能,让电子笔记更智能
业内领先 四川大学华西第四医院甲状腺乳腺外科成功进入手术机器人时代
郭帆谈ChatGPT:电影行业需要创新,否则人工智能将让电影变得平庸
IBM 与 NASA 携手开源地理空间 AI 模型,促进气候科学研究进步
美图吴欣鸿:希望更多人用上AI时代的影像生产力工具
华为大模型登Nature正刊!审稿人:让人们重新审视预报模型的未来
机器人 展才能
鸿蒙智能座舱的AI大模型革新,引领智能座舱领域的变革吗?
昇腾AI & 讯飞星火:深度联手,共话国产大模型“大未来”
「模仿学习」只会套话?解释微调+130亿参数Orca:推理能力打平ChatGPT
CharacterAI - 也许会成为会话人工智能的未来
美图影像节演讲实录:191次提及AI,发布7款影像生产力工具
2025VR&AR显示技术峰会展示歌尔光学最新一代光学模组
用人工智能技术,亚马逊为用户生成产品评论摘要,帮助他们轻松选购
“一般智力”与工艺学批判是认识AI的重要入口 | 社会科学报
WPS AI 官网上线:可申请体验官资格,支持 Windows、安卓端下载
朱民:普通人炒股炒不过机器人是很正常的 AI已经能理解市场情绪
DreamAvatar数字人在哪里下载
大型无人机FH-98国内首次夜航转场成功
Nature发AIGC禁令!投稿中视觉内容使用AI的概不接收
尼康尼克尔Z 180-600mm f/5.6-6.3 VR镜头发布:12499元 拍鸟神器
华为即将推出HarmonyOS 4,再度领先行业的AI技术
华为4G5G通信物联网收费标准公布,多年研发成果,十年花费近万亿
特斯拉 Optimus 人形机器人入驻北美门店,帮助提升汽车销量
陈根:AI工具为游戏软件实时3D内容助力
Midjourney创始人:AI应该成为人类思想的延伸
ChatGPT大更新!OpenAI奉上程序员大礼包:API新增杀手级能力还降价,新模型、四倍上下文都来了
小米9号员工李明宣布创业:打造首款安卓桌面机器人
生成式人工智能如何改变云安全的游戏规则
实现人工智能和物联网的协同运作
禁止艺术家使用 AI 创作《龙与地下城》游戏插图的决定已在 D&D Beyond 生效
食品分销跨国企业Sysco CIDO:我们的增长秘诀是以IT为中心
2023-06-26

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
