自从大模型火爆出圈以后,人们对压缩大模型的愿望从未消减。这是因为,虽然大模型在很多方面表现出优秀的能力,但高昂的的部署代价极大提升了它的使用门槛。这种代价主要来自于空间占用和计算量。「模型量化」 通过把大模型的参数转化为低位宽的表示,进而节省空间占用。目前,主流方法可以在几乎不损失模型性能的情况下把已有模型压缩至 4bit。然而,低于 3bit 的量化像一堵不可逾越的高墙,让研究人员望而生畏。
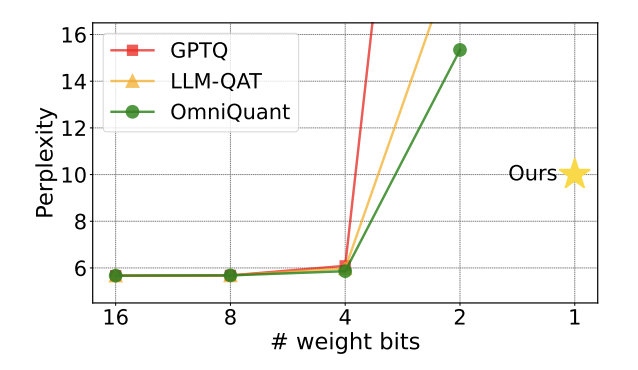
图 1 : 量化模型的困惑度在 2bit 时迅速上升
近期,一篇由清华大学、哈尔滨工业大学合作发表在 arXiv 上的论文为突破这一阻碍带来了希望,在国内外学术圈引起了不小的关注。这篇论文也在一周前登上 huggingface 的热点论文,并被著名论文推荐师 AK 推荐。研究团队直接越过 2bit 这一量化级别,大胆地进行了 1bit 量化的尝试,这在模型量化的研究中尚属首次。

论文标题:onebit: towards extremely low-bit large language models
论文地址:https://arxiv.org/pdf/2402.11295.pdf
作者提出的方法称作 「OneBit」,非常贴切地形容了这一工作的本质:把预训练大模型压缩到真正的 1bit。该论文提出了模型参数 1bit 表示的新方法,以及量化模型参数的初始化方法,并通过量化感知训练(QAT)把高精度预训练模型的能力迁移至 1bit 量化模型。实验表明,这一方法能够在极大幅度压缩模型参数的同时,保证 LLaMA 模型至少 83% 的性能。
作者指出,当模型参数压缩至 1bit 后,矩阵乘法中的 「元素乘」将不复存在,取而代之的是更快速的 「位赋值」操作,这将大大提升计算效率。这一研究的重要意义在于,它不但跨越了 2bit 量化的鸿沟,也使在 PC 和智能手机上部署大模型成为可能。
模型量化主要通过把模型的 nn.Linear 层(Embedding 层和 Lm_head 层除外)转化为低精度表示实现空间压缩。此前工作 [1,2] 的基础是利用 Round-To-Nearest(RTN)方法把高精度浮点数近似映射到附近的整数网格。这可以被表示成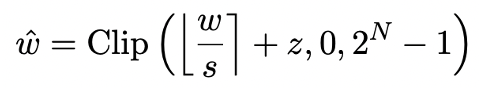 。
。
然而基于 RTN 的方法在极低位宽时(3bit 以下)存在严重的精度损失问题,量化后的模型能力损失十分严重。特别是,量化后参数以 1bit 表示时,RTN 中的缩放系数 s 和零点 z 会失去实际意义。这导致基于 RTN 的量化方法在 1bit 量化时几乎失效,难以有效地保留原模型的性能。
此外,此前的研究中也曾对 1bit 模型可能采用什么结构进行过探索。几个月前的工作 BitNet [3] 通过让模型参数通过 Sign (・) 函数并转为 + 1/-1 来实现 1bit 表示。但这一方法存在性能损失严重、训练过程不稳定的问题,限制了其实际应用。
OneBit 的方法框架包括全新的 1bit 层结构、基于 SVID 的参数初始化方法和基于量化感知知识蒸馏的知识迁移。
1. 新的 1bit 结构
OneBit 的终极目标是将 LLMs 的权重矩阵压缩到 1bit。真正的 1bit 要求每个权重值只能用 1bit 表示,即只有两种可能的状态。作者认为,在大模型的参数中,有两个重要因素都必须被考虑进来,那就是浮点数的高精度和参数矩阵的高秩。
因此,作者引入两个 FP16 格式的值向量以补偿由于量化导致的精度损失。这种设计不仅保持了原始权重矩阵的高秩,而且通过值向量提供了必要的浮点精度,有助于模型的训练和知识迁移。1bit 线性层的结构与 FP16 高精度线性层的结构对比如下图:
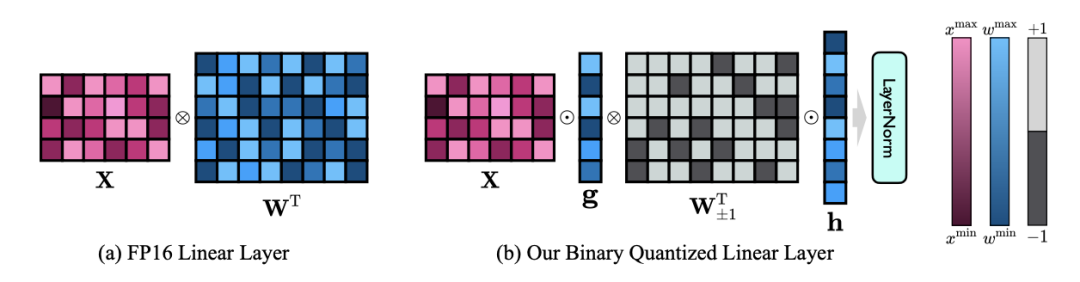
图 3 : FP16 线性层与 OneBit 线性层的对比
左侧的 (a) 是 FP16 精度模型结构,右侧的 (b) 是 OneBit 框架的线性层。可见,在 OneBit 框架中,只有值向量 g 和 h 保持 FP16 格式,而权重矩阵则全部由 ±1 组成。这样的结构兼顾了精度和秩,对保证稳定且高质量的学习过程很有意义。
OneBit 对模型的压缩幅度究竟如何?作者在论文中给了一个计算。假设对一个 4096*4096 的线性层进行压缩,那么 OneBit 需要一个 4096*4096 的 1bit 矩阵,和两个 4096*1 的 16bit 值向量。这里面总的位数为 16,908,288,总的参数个数为 16,785,408,平均每个参数占用仅仅约 1.0073 个 bit。这样的压缩幅度是空前的,可以说是真正的 1bit 大模型。
2. 基于 SVID 初始化量化模型
为了使用充分训练好的原模型更好地初始化量化后的模型,进而促进更好的知识迁移效果,作者提出一种新的参数矩阵分解方法,称为 「值 - 符号独立的矩阵分解(SVID)」。这一矩阵分解方法把符号和绝对值分开,并把绝对值进行秩 - 1 近似,其逼近原矩阵参数的方式可以表示成:
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 Machine Translation
Machine Translation
聚合多个来源的AI翻译
 49
查看详情
49
查看详情

这里的秩 - 1 近似可以通过常见的矩阵分解方式实现,例如奇异值分解(SVD)和非负矩阵分解(NMF)。而后,作者在数学上给出这种 SVID 方法可以通过交换运算次序来和 1bit 模型框架相匹配,进而实现参数初始化。并 且,论文还证明了符号矩阵在分解过程中确实起到了近似原矩阵的作用。
且,论文还证明了符号矩阵在分解过程中确实起到了近似原矩阵的作用。
3. 通过知识蒸馏迁移原模型能力
作者指出,解决大模型超低位宽量化的有效途径可能是量化感知训练 QAT。在 OneBit 模型结构下,通过知识蒸馏从未量化模型中学习,实现能力向量化模型的迁移。具体地,学生模型主要接受教师模型 logits 和 hidden state 的指导。
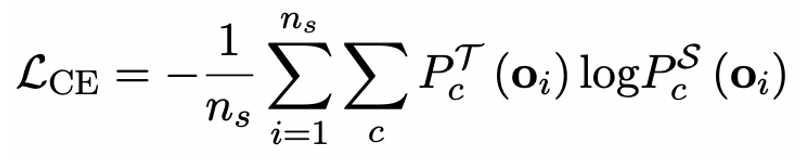
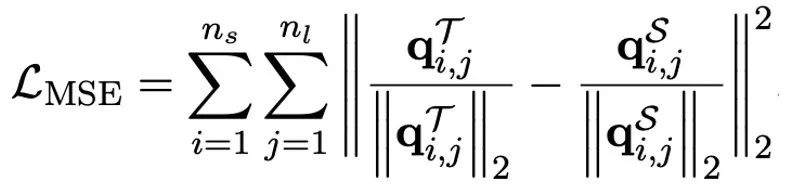
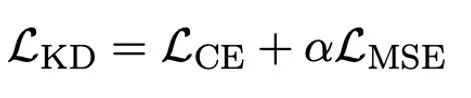
训练时,值向量和矩阵的值会被更新。模型量化完成后,直接把 Sign (・) 后的参数保存下来,在推理和部署时直接使用。
OneBit 与 FP16 Transformer、经典的训练后量化强基线 GPTQ、量化感知训练强基线 LLM-QAT 和最新的 2bit 权重量化强基线 OmniQuant 进行了比较。此外,由于目前还没有 1bit 权重量化的研究,作者只对自己的 OneBit 框架使用了 1bit 权重量化,而对其他方法采取 2bit 量化设置,属于典型的 「以弱胜强」。
在模型选择上,作者也选择了从 1.3B 到 13B 不同大小、OPT 和 LLaMA-1/2 不同系列的模型来证明 OneBit 的有效性。在评价指标上,作者沿用了以往模型量化的两大评价维度:验证集的困惑度和常识推理的 Zero-shot 准确度。
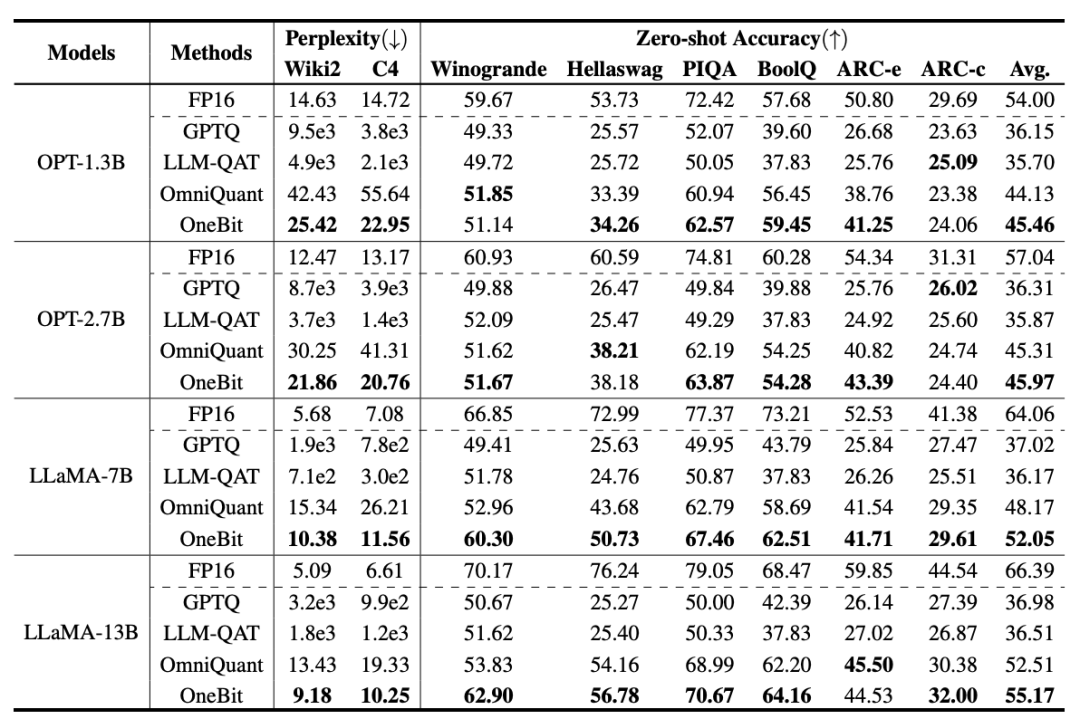
表 1 : OneBit 与基线方法的效果比较(OPT 模型与 LLaMA-1 模型)
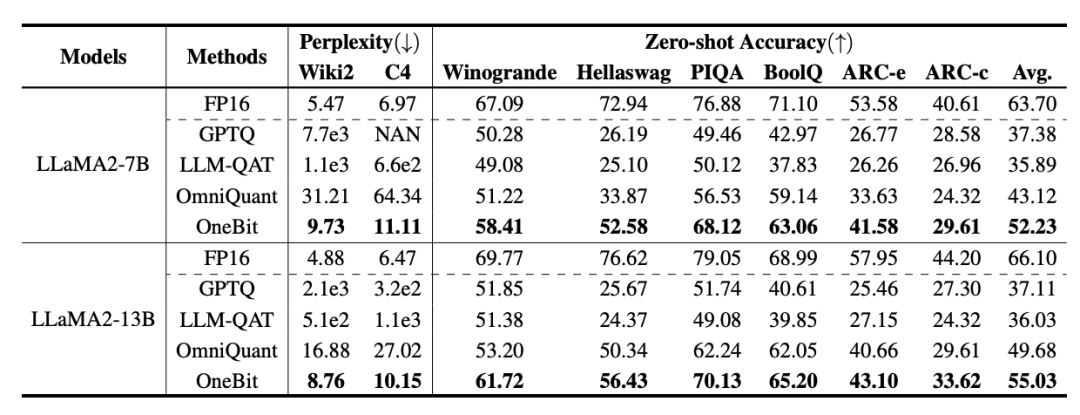
表 2 : OneBit 与基线方法的效果比较(LLaMA-2 模型)
表 1 和表 2 展示出了 OneBit 相比于其他方法在 1bit 量化时的优势。就量化模型在验证集的困惑度而言,OneBit 与 FP16 模型最为接近。就 Zero-shot 准确度而言,除 OPT 模型的个别数据集外,OneBit 量化模型几乎取得了最佳的性能。其余的 2bit 量化方法在两种评价指标上呈现较大的损失。
值得注意的是,OneBit 在模型越大时,效果往往越好。也就是说,随着模型规模增大,FP16 精度模型在困惑度降低上收效甚微,但 OneBit 却表现出更多的困惑度下降。此外,作者还指出量化感知训练对于超低位宽量化或许十分有必要。
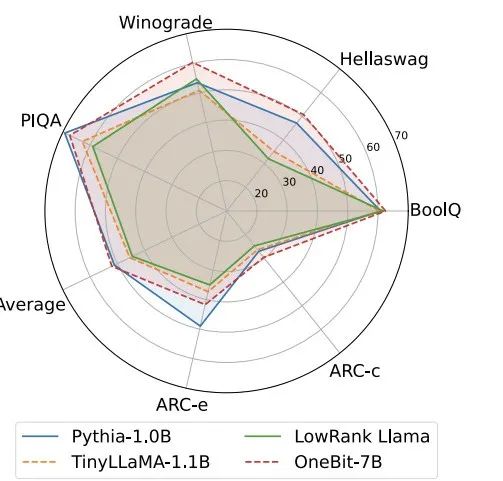
图 4 : 常识推理任务对比
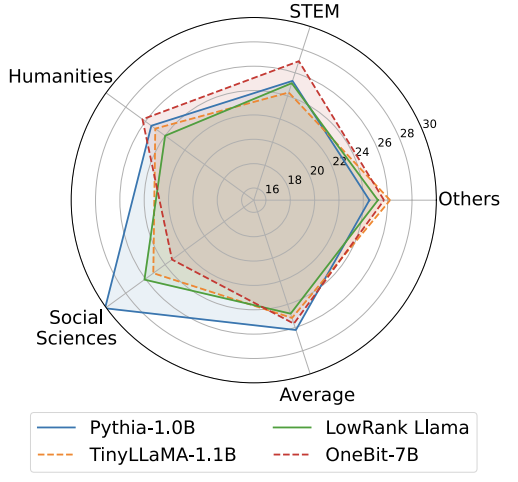
图 5 : 世界知识对比
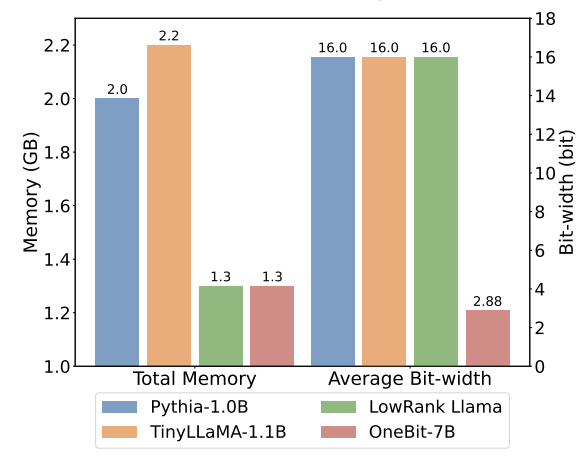
图 6 : 几种模型的空间占用和平均位宽
图 4 - 图 6 还对比了几类小模型的空间占用和性能损失,它们是通过不同的途径获得的:包括两个充分训练的模型 Pythia-1.0B 和 TinyLLaMA-1.1B,以及通过低秩分解获得的 LowRank Llama 和 OneBit-7B。可以看出,尽管 OneBit-7B 有最小的平均位宽、占用最小的空间,它在常识推理能力上仍然优于不逊于其他模型。作者同时指出,模型在社会科学领域面临较严重的知识遗忘。总的来说,OneBit-7B 展示出了其实际应用价值。正如图 7 所展示的,OneBit 量化后的 LLaMA-7B 模型经过指令微调后,展示出了流畅的文本生成能力。

图 7 : OneBit 框架量化后的 LLaMA-7B 模型的能力
1. 效率
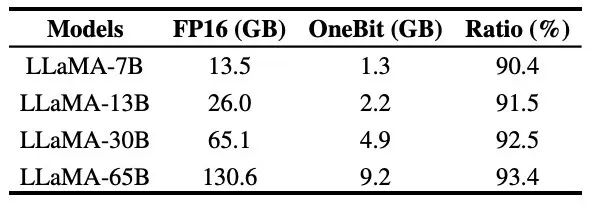
表 3 : OneBit 在不同 LLaMA 模型的压缩比
表 3 给出的是 OneBit 对不同规模 LLaMA 模型的压缩比。可以看出,OneBit 对模型的压缩比均超过 90%,这一压缩能力是史无前例的。其中值得注意的是,随着模型增大,OneBit 的压缩比越高,这是由于 Embedding 层这种不参与量化的参数占比越来越小。前文提到,模型越大,OneBit 带来的性能增益越大,这显示出 OneBit 在更大模型上的优势。
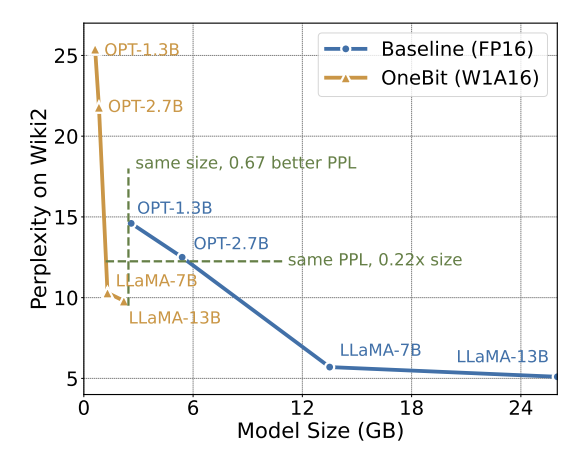
图 8 : 模型大小与性能的权衡
虽然超低比特量化可能会导致一定的性能损失,但如图 8 所示,它在大小和性能之间达到了良好的平衡。作者认为,压缩模型的大小十分重要,特别是在移动设备上部署模型时。
此外,作者还指出了 1bit 量化模型在计算上的优势。由于参数是纯二进制的,可以用 0/1 在 1bit 内表示,这毫无疑问地节省大量的空间。高精度模型中矩阵乘法的元素相乘可以被变成高效的位运算,只需位赋值和加法就可以完成矩阵乘积,非常有应用前景。
2. 鲁棒性
二值网络普遍面临训练不稳定、收敛困难的问题。得益于作者引入的高精度值向量,模型训练的前向计算和后向计算均表现的十分稳定。BitNet 更早地提出 1bit 模型结构,但该结构很难从充分训练的高精度模型中迁移能力。如图 9 所示,作者尝试了多种不同的学习率来测试 BitNet 的迁移学习能力,发现在教师指导下其收敛难度较大,也在侧面证明了 OneBit 的稳定训练价值。
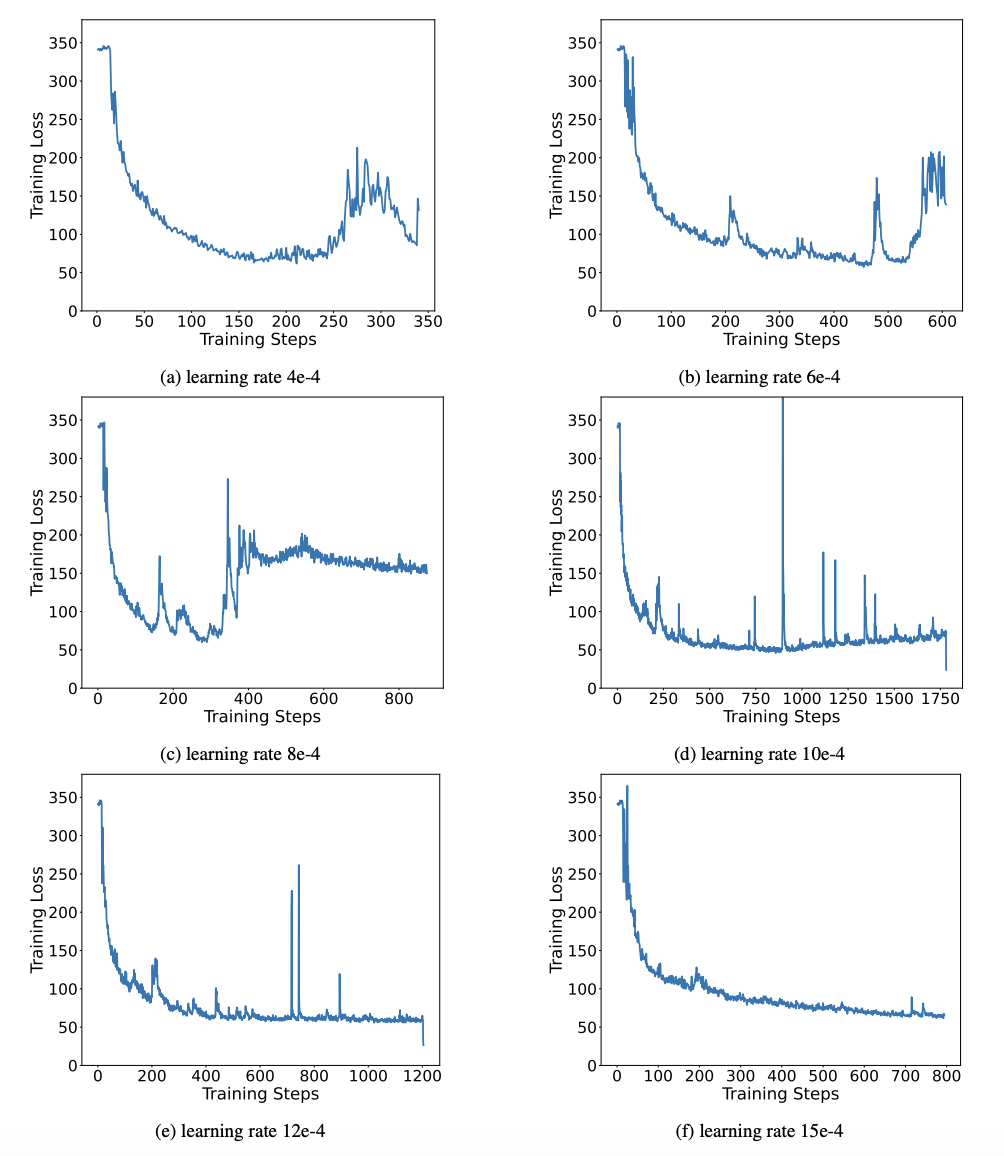
图 9 : BitNet 在多种不同学习率下的训练后量化能力
论文的最后,作者还建议了超低位宽未来可能得研究方向。例如,寻找更优的参数初始化方法、更少的训练代价,或进一步考虑激活值的量化。
更多技术细节请查看原论文。
以上就是清华、哈工大把大模型压缩到了1bit,把大模型放在手机里跑的愿望就快要实现了!的详细内容,更多请关注其它相关文章!
# 压缩
# seo七种误区
# 青龙网站优化电话多少
# 超低
# 出了
# 位宽
# 的是
# 这一
# 实现了
# 机里
# 在手
# 清华
# 哈工大
# llama
# 模型
# seo 日志分析软件
# 襄樊网站的推广
# 网站优化做外链要注意什么
# 成都营销推广竞价公司
# 优化seo厂商
# 深圳seo的优化价格
# seo属于什么专业术语
# 长尾词seo模型
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
上海发布“元宇宙关键技术攻关行动方案”,加快 AIGC 等突破
映宇宙集团执行总编辑:元宇宙还是要以人为媒介
争鸣:OpenAI奥特曼、Hinton、杨立昆的AI观点到底有何不同?
一次购买全年省心,入手科沃斯这几台机器人,省下时间就是金钱
美图第二届影像节发布七款AI影像创作工具
2025智源大会AI安全话题备受关注,《人机对齐》新书首发
Transformer六周年:当年连NeurIPS Oral都没拿到,8位作者已创办数家AI独角兽
SnapFusion技术大幅提升AI图像生成速度
Prompt解锁语音语言模型生成能力,SpeechGen实现语音翻译、修补多项任务
机构研选 | 虚拟电厂是电力物联网升级版 智能电网望迎来高速发展
人工智能加速走进百姓生活:从2025全球人工智能技术大会看行业新趋势
马斯克反讽人工智能AI炒作:“机器学习”本质就是统计
“苏南 vs 苏北” AI 分胜负,娱乐性比较工具 EitherChoice 上线
Meta推出VR订阅服务Quest +:每月免费玩两款游戏,7.99美元/月
【澎湃原动力】人工智能产业协同创新中心:全产业链资源在这里汇聚
亲身体验鸿蒙4:AI大模型带来的便利,告别单纯的旁观者状态
十个AI算法常用库J*a版
“直击”AI新世界,智能机器人再次“火出圈”了
Bing Chat 和 Bing Search 正式引入深色模式
OpenAI高管:AI能创造新的就业机会 但也会淘汰一些
DreamAvatar数字人在哪里下载
无人机协助盐城交通执法的协同训练
世界人工智能大会中西部县域数字就业中心组团亮相
论文插图也能自动生成了,用到了扩散模型,还被ICLR接收
2025年深圳举办的SUSECON 创新峰会开始接受报名
陈根:ChatGPT和人类合作开发机器人
AI成政客博弈工具,美国大选真假难辨,律师们的生意来了
360发布认知型通用大模型“360智脑4.0” 全面接入360全家桶
清华系面壁智能开源中文多模态大模型VisCPM :支持对话文图双向生成,吟诗作画能力惊艳
AYANEO AIR 1S 掌机发布:R7 7840U,预订价 4699 元起
令人震惊的特斯拉机器人
美图秀秀发布7款AI产品:支持用户创作、商业创作
世界人工智能大会(WAIC 2025)点燃魔都,博尔捷数字科技携前沿技术产品亮相
探索AI前沿理念 2025全球人工智能技术大会在杭州开幕
给小朋友最好的科技礼物:乐天派桌面机器人
苹果在韩举办首届中小企业智能制造论坛,加速推动工业4.0发展
乐天派桌面机器人加入小米米家生态系统,实现与其他智能设备的互联
当科幻走进现实 脑机接口新技术能为生活带来哪些惊喜?
自动驾驶汽车避障、路径规划和控制技术详解
GPT-4是如何工作的?哈佛教授亲自讲授
普渡机器人与变形金刚品牌合作,特别活动爆火,商品售罄!
海南省公安机关警用无人机培训班结业并举行警航比武演练
「模仿学习」只会套话?解释微调+130亿参数Orca:推理能力打平ChatGPT
严打“黑飞”,无人机检测反制设备护航大运会净空安全
生成式AI引路产业加速来袭,微美全息探索“AIGC+虚拟人”融合应用
甲骨文与Cohere合作为企业提供生成式人工智能服务
OpenAI 已全面开放 GPT-3.5 Turbo、DALL-E 及 Whisper API
食品分销跨国企业Sysco CIDO:我们的增长秘诀是以IT为中心
视觉中国推出AI灵感绘图功能,付费后可在“合法合规前提下使用”
两小时就能超过人类!DeepMind最新AI速通26款雅达利游戏
2024-03-04

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
