遮挡是计算机视觉很基础但依旧未解决的问题之一,因为遮挡意味着视觉信息的缺失,而机器视觉系统却依靠着视觉信息进行感知和理解,并且在现实世界中,物体之间的相互遮挡无处不在。牛津大学 VGG 实验室 Andrew Zisserman 团队最新工作系统性解决了任意物体的遮挡补全问题,并且为这一问题提出了一个新的更加精确的评估数据集。该工作受到了 MPI 大佬 Michael Black、CVPR 官方账号、南加州大学计算机系官方账号等在 X 平台的点赞。以下为论文「Amodal Ground Truth and Completion in the Wild」的主要内容。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

非模态分割(Amodal Segmentation)旨在补全物体被遮挡的部分,即给出物体可见部分和不可见部分的形状掩码。这个任务可以使得诸多下游任务受益:物体识别、目标检测、实例分割、图像编辑、三维重建、视频物体分割、物体间支撑关系推理、机器人的操纵和导航,因为在这些任务中知道被遮挡物体完整的形状会有所帮助。

然而,如何去评估一个模型在真实世界做非模态分割的性能却是一个难题:虽然很多图片中都有大量的被遮挡物体,可是如何得到这些物体完整形状的参考标准 或是非模态掩码呢?前人的工作有通过人手动标注非模态掩码的,可是这样标注的参考标准难以避免引入人类误差;也有工作通过制造合成数据集,比如在一个完整的物体上贴直接另一个物体,来得到被遮挡物体的完整形状,但这样得到的图片都不是真实图片场景。因此,这个工作提出了通过 3D 模型投影的方法,构造了一个大规模的涵盖多物体种类并且提供非模态掩码的真实图片数据集(MP3D-Amodal)来精确评估非模态分割的性能。各不同数据集的对比如下图:
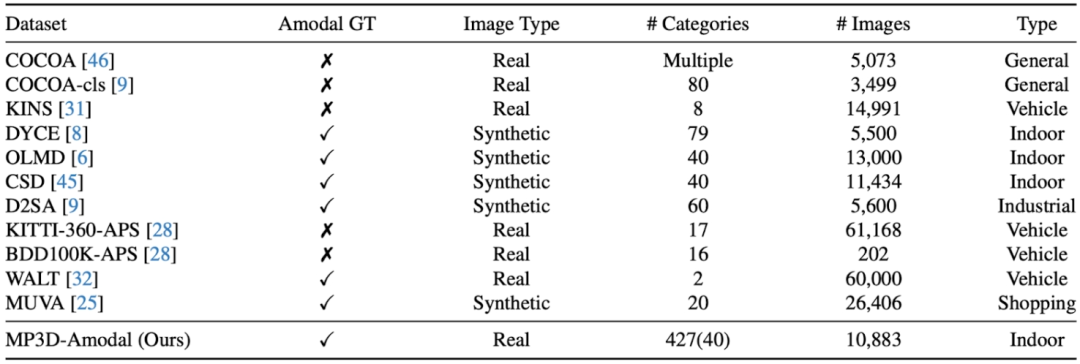
具体而言,以 MatterPort3D 数据集为例,对于任意的有真实照片并且有场景三维结构的数据集,我们可以将场景中所有物体的三维形状同时投影到相机上以得到每个物体的模态掩码(可见形状,因为物体相互之间有遮挡),然后将场景中每个物体的三维形状分别投影到相机以得到这个物体的非模态掩码,即完整的形状。通过对比模态掩码和非模态掩码,即可以挑选出被遮挡的物体。

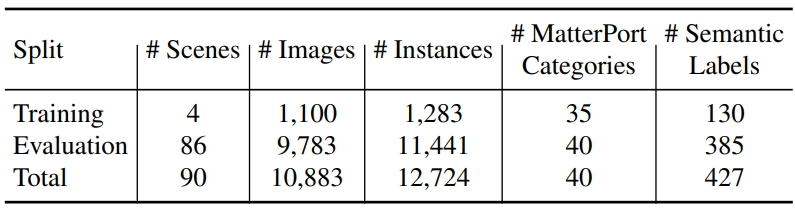
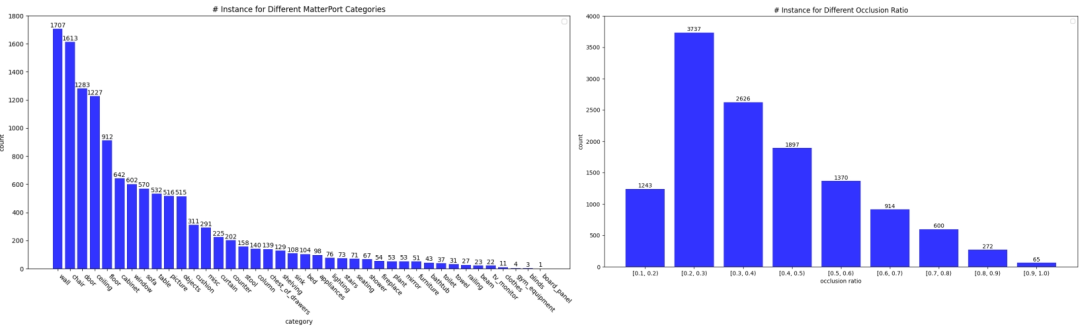
数据集的统计数据如下:
数据集的样例如下:

此外,为解决任意物体的完整形状重建任务,作者提取出 Stable Diffusion 模型的特征中关于物体完整形状的先验知识,来对任意被遮挡物体做非模态分割,具体的架构如下(SDAmodal):
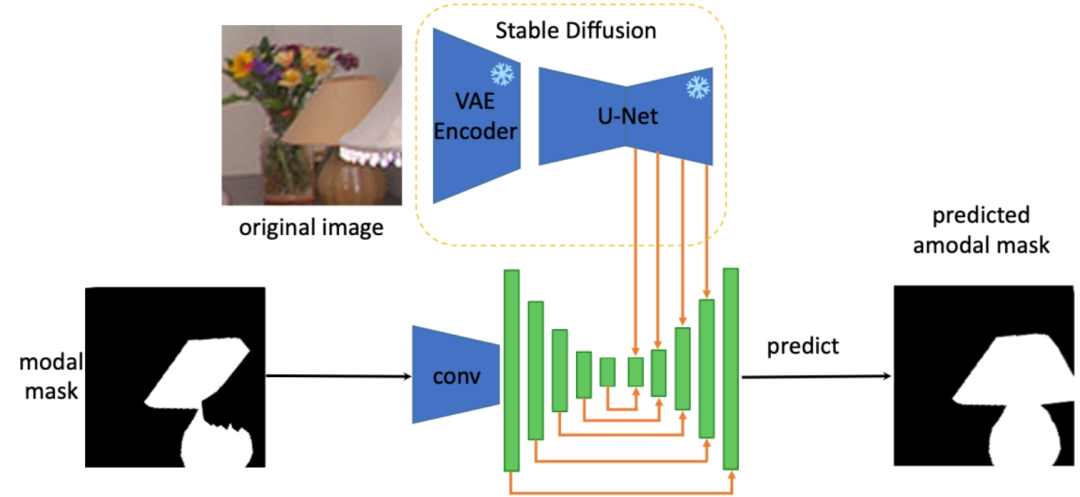
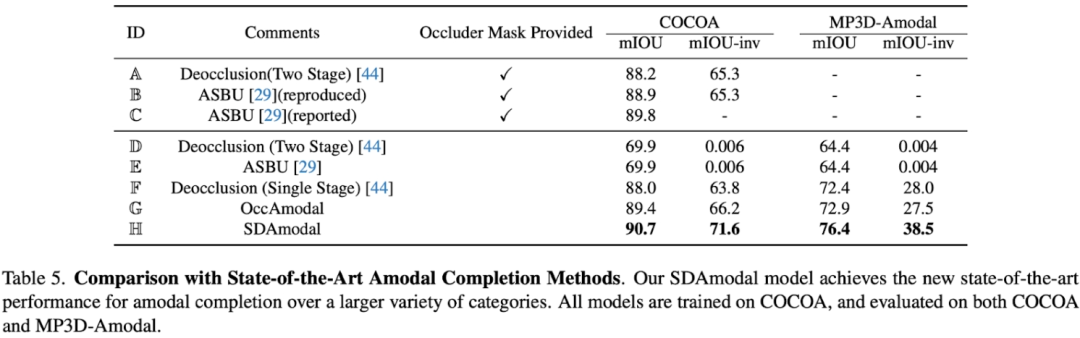
提出使用 Stable Diffusion Feature 的动机在于,Stable Diffusion 具有图片补全的能力,所以可能一定程度上包含了有关物体的全部信息;而且由于 Stable Diffusion 经过大量图片的训练,所以可以期待其特征在任意环境下有对任意物体的处理能力。和前人 two-stage 的框架不同,SDAmodal 不需要已经标注好的遮挡物掩码作为输入;SDAmodal 架构简单,却体现出很强的零样本泛化能力(比较下表 Setting F 和 H,仅在 COCOA 上训练,却能在另一个不同域、不同类别的数据集上有所提升);即使没有关于遮挡物的标注,SDAmodal 在目前已有的涵盖多种类被遮挡物体的数据集 COCOA 以及新提出的 MP3D-Amodal 数据集上,都取得了SOTA表现(Setting H)。
除了定量实验,定性的比较也体现出了 SDAmodal 模型的优势:从下图可以观察到(所有模型都只在 COCOA 上训练),对于不同种类的被遮挡物体,无论是来自于 COCOA,还是来自于另一个MP3D-Am odal,SDAmodal 都能大大提升非模态分割的效果,所预测的非模态掩码更加接近真实的。
odal,SDAmodal 都能大大提升非模态分割的效果,所预测的非模态掩码更加接近真实的。

更多细节,请阅读论文原文。
以上就是「AI透视眼」,三次马尔奖获得者Andrew带队解决任意物体遮挡补全难题的详细内容,更多请关注其它相关文章!
# 上海
# 新乐国内网站推广案例
# 营销广告经典推广语录
# 洛阳网站推广设计招聘网
# 企划营销创意推广视频
# 南京外贸网站建设推广
# seo关键词排名选择20火星
# 义乌网站建设高端公司
# 长沙seo外包价格
# 宁波正规关键词排名
# 新站整站seo优化价格
# 大佬
# ai
# 牛津大学
# 来自于
# 谁能
# 提出了
# 开源
# 掩码
# 模态
# 马尔
# stable diffusion
# 训练
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
天翼云在国际AI顶会大模型挑战赛中获得冠军
微软在德国举办MR研讨会,向女性分享元宇宙潜力
Meta 开源 AI 语言模型 MusicGen,可将文本和旋律转化为完整乐曲
30+大模型齐聚,大模型成世界人工智能大会“顶流”
AI 模型 Stable Diffusion 升级:正常生成五指、图像更逼真
Meta 发布 Voicebox AI 模型:可生成音频信息,用于 NPC 对话等
视觉中国宣布推出AI灵感绘图、画面扩展功能
选对AI智能写作软件,让创作游刃有余!
掌阅科技对话式AI应用“阅爱聊”开启内测
赋能选题探索:AI助手在经济学专业中的应用指南
微软商店 AI 摘要功能开启预览,帮助用户迅速了解应用评价
人工智能时代的科幻译者怎么办?“做好翻译工作的高端10%”|文化观察
微软面向AI初学者推出免费网络课程
DeepMind推惊世排序算法,C++库忙更新!
Midjourney 5.2震撼发布!原画生成3D场景,无限缩放无垠宇宙
生成式AI爆发,亚马逊云科技持续专注创新,助力企业数字化转型
下一个前沿:量子机器学习和人工智能的未来
懒人必备的家居清洁好物,石头自清洁扫拖机器人G20
XREAL发布新款硬件XREAL Beam投屏盒子:可悬停AR空间屏
三星加速AR眼镜进程,预计明年上半年亮相
《自然》杂志拒绝刊登人工智能生成的图片和视频
大厂出品!这个AI网站太顶了,所有功能免费用
视觉中国推出付费AI绘图功能:无版权可用
美图设计室2.0什么时候上线
阿里云连续两年进入Gartner云AI开发者“挑战者象限”
宇宙探索下一阶段,机器代替人类,AI会在太空探索中取代人类吗?
【趋势周报】全球元宇宙产业发展趋势:ChatGPT的出现,将元宇宙实现至少提前了10年
如何利用AI工具写好本科论文:科技助你一臂之力
2025VR&AR显示技术峰会展示歌尔光学最新一代光学模组
首个算网生态体!中国移动元宇宙产业联盟正式成立
首届全国体育人工智能大会在首都体育学院召开
华为发布大模型时代AI存储新品
“世界上最像人的机器人”接入 Stable Diffusion ,现场完成作画
即将到来:AI婚纱设计软件实际测试,人工智能即将开创婚纱设计新纪元
类GPT模型训练提速26.5%,清华朱军等人用INT4算法加速神经网络训练
机智云AI离线语音识别模组,让家电变得更加智能便捷
AI与5G的强强联合:唤醒数字时代的无尽潜能
陈根:ChatGPT和人类合作开发机器人
业内领先 四川大学华西第四医院甲状腺乳腺外科成功进入手术机器人时代
OpenAI宣布组建新团队 以控制“超级智能”人工智能
以分布式网络串联闲置GPU,这家创企称可将AI模型训练成本降低90%
智能机器人正在彻底改变客户服务
塑造全能智能管家:华为小艺AI加成应对大模型挑战
猿辅导发布最新SaaS业务进展公告:Motiff UI设计工具推出三项新的AI功能
助力人工智能产业高质量发展 龙岗区算法训练基地正式启用
论文插图也能自动生成了,用到了扩散模型,还被ICLR接收
到中国科技馆体验“一滴油的奇妙旅行”,线上元宇宙展厅同步开启
引领AI变革,九章云极DataCanvas公司重磅发布AIFS+DataPilot
人工智能创作的“婴儿版超级英雄”,你觉得哪个最可爱
网易数帆以AI融合创新引领数据分析与软件开发新趋势
2024-03-08

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
