近几年,图像生成领域取得了巨大的进步,尤其是文本到图像生成方面取得了重大突破:只要我们用文本描述自己的想法,AI 就能生成新奇又逼真的图像。
但其实我们可以更进一步 —— 将头脑中的想法转化为文本这一步可以省去,直接通过脑活动(如 EEG(脑电图)记录)来控制图像的生成创作。
这种「思维到图像」的生成方式有着广阔的应用前景。例如,它能极大提高艺术创作的效率,并帮助人们捕捉稍纵即逝的灵感;它也有可能将人们夜晚的梦境进行可视化;它甚至可能用于心理治疗,帮助自闭症儿童和语言障碍患者。
最近,来自清华大学深圳国际研究生院、腾讯 AI Lab 和鹏城实验室的研究者们联合发表了一篇「思维到图像」的研究论文,利用预训练的文本到图像模型(比如 Stable Diffusion)强大的生成能力,直接从脑电图信号生成了高质量的图像。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 图片
图片
论文地址:https://arxiv.org/pdf/2306.16934.pdf
项目地址:https://github.com/bbaaii/DreamDiffusion
 Android 应用框架原理与程序设计36技pdf繁体版
Android 应用框架原理与程序设计36技pdf繁体版
Android应用框架原理与程序设计36技 pdf繁体版,书籍内容适用于Android 1.0,有些朋友可能对Android还不太熟悉吧?不知您是否听说过Google 在HTC定制的高端手机呢?其操作系统是基于Android的,如果还是不太清楚的话,可以Google一下“HTC g2”手机,可以大致了解一下手机操作系统的界面及架构特点。不管怎么说,Android手机编程目前还是主要面向高端,在将来可能会普及,因此Android编程还是很有必要掌握的。
 0
查看详情
0
查看详情


近期一些相关研究(例如 MinD-Vis)尝试基于 fMRI(功能性磁共振成像信号)来重建视觉信息。他们已经证明了利用脑活动重建高质量结果的可行性。然而,这些方法与理想中使用脑信号进行快捷、高效的创作还差得太远,这主要有两点原因:
首先,fMRI 设备不便携,并且需要专业人员操作,因此捕捉 fMRI 信号很困难;
其次,fMRI 数据采集的成本较高,这在实际的艺术创作中会很大程度地阻碍该方法的使用。
相比之下,EEG 是一种无创、低成本的脑电活动记录方法,并且现在市面上已经有获得 EEG 信号的便携商用产品。
但实现「思维到图像」的生成还面临两个主要挑战:
1)EEG 信号通过非侵入式的方法来捕捉,因此它本质上是有噪声的。此外,EEG 数据有限,个体差异不容忽视。那么,如何从如此多的约束条件下的脑电信号中获得有效且稳健的语义表征呢?
2)由于使用了 CLIP 并在大量文本 - 图像对上进行训练,Stable Diffusion 中的文本和图像空间对齐良好。然而,EEG 信号具有其自身的特点,其空间与文本和图像大不相同。如何在有限且带有噪声的 EEG - 图像对上对齐 EEG、文本和图像空间?
为了解决第一个挑战,该研究提出,使用大量的 EEG 数据来训练 EEG 表征,而不是仅用罕见的 EEG 图像对。该研究采用掩码信号建模的方法,根据上下文线索预测缺失的 token。
不同于将输入视为二维图像并屏蔽空间信息的 MAE 和 MinD-Vis,该研究考虑了 EEG 信号的时间特性,并深入挖掘人类大脑时序变化背后的语义。该研究随机屏蔽了一部分 token,然后在时间域内重建这些被屏蔽的 token。通过这种方式,预训练的编码器能够对不同个体和不同脑活动的 EEG 数据进行深入理解。
对于第二个挑战,先前的解决方法通常直接对 Stable Diffusion 模型进行微调,使用少量噪声数据对进行训练。然而,仅通过最终的图像重构损失对 SD 进行端到端微调,很难学习到脑信号(例如 EEG 和 fMRI)与文本空间之间的准确对齐。因此,研究团队提出采用额外的 CLIP 监督,帮助实现 EEG、文本和图像空间的对齐。
具体而言,SD 本身使用 CLIP 的文本编码器来生成文本嵌入,这与之前阶段的掩码预训练 EEG 嵌入非常不同。利用 CLIP 的图像编码器提取丰富的图像嵌入,这些嵌入与 CLIP 的文本嵌入很好地对齐。然后,这些 CLIP 图像嵌入被用于进一步优化 EEG 嵌入表征。因此,经过改进的 EEG 特征嵌入可以与 CLIP 的图像和文本嵌入很好地对齐,并更适合于 SD 图像生成,从而提高生成图像的质量。
基于以上两个精心设计的方案,该研究提出了新方法 DreamDiffusion。DreamDiffusion 能够从脑电图(EEG)信号中生成高质量且逼真的图像。
 图片
图片
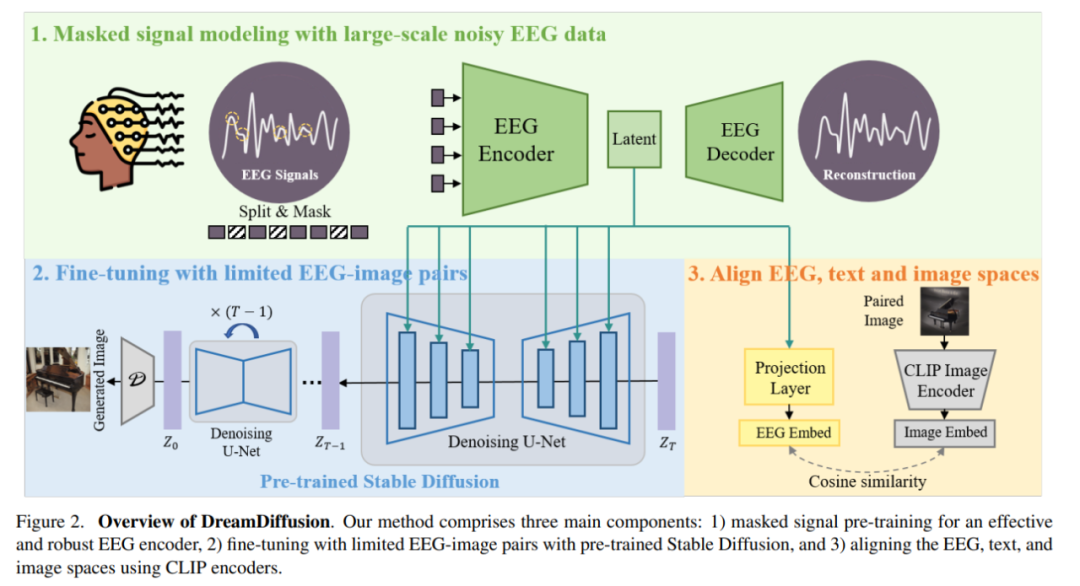
具体来说,DreamDiffusion 主要由三个部分组成:
1)掩码信号预训练,以实现有效和稳健的 EEG 编码器;
2)使用预训练的 Stable Diffusion 和有限的 EEG 图像对进行微调;
3)使用 CLIP 编码器,对齐 EEG、文本和图像空间。
首先,研究人员利用带有大量噪声的 EEG 数据,采用掩码信号建模,训练 EEG 编码器,提取上下文知识。然后,得到的 EEG 编码器通过交叉注意力机制被用来为 Stable Diffusion 提供条件特征。
 图片
图片
为了增强 EEG 特征与 Stable Diffusion 的兼容性,研究人员进一步通过在微调过程中减少 EEG 嵌入与 CLIP 图像嵌入之间的距离,进一步对齐了 EEG、文本和图像的嵌入空间。
与 Brain2Image 对比
研究人员将本文方法与 Brain2Image 进行比较。Brain2Image 采用传统的生成模型,即变分自编码器(VAE)和生成对抗网络(GAN),用于实现从 EEG 到图像的转换。然而,Brain2Image 仅提供了少数类别的结果,并没有提供参考实现。
鉴于此,该研究对 Brain2Image 论文中展示的几个类别(即飞机、南瓜灯和熊猫)进行了定性比较。为确保比较公平,研究人员采用了与 Brain2Image 论文中所述相同的评估策略,并在下图 5 中展示了不同方法生成的结果。
下图第一行展示了 Brain2Image 生成的结果,最后一行是研究人员提出的方法 DreamDiffusion 生成的。可以看到 DreamDiffusion 生成的图像质量明显高于 Brain2Image 生成的图像,这也验证了本文方法的有效性。
 图片
图片
消融实验
预训练的作用:为了证明大规模 EEG 数据预训练的有效性,该研究使用未经训练的编码器来训练多个模型进行验证。其中一个模型与完整模型相同,而另一个模型只有两层的 EEG 编码层,以避免数据过拟合。在训练过程中,这两个模型分别进行了有 / 无 CLIP 监督的训练,结果如表 1 中 Model 列的 1 到 4 所示。可以看到,没有经过预训练的模型准确性有所降低。
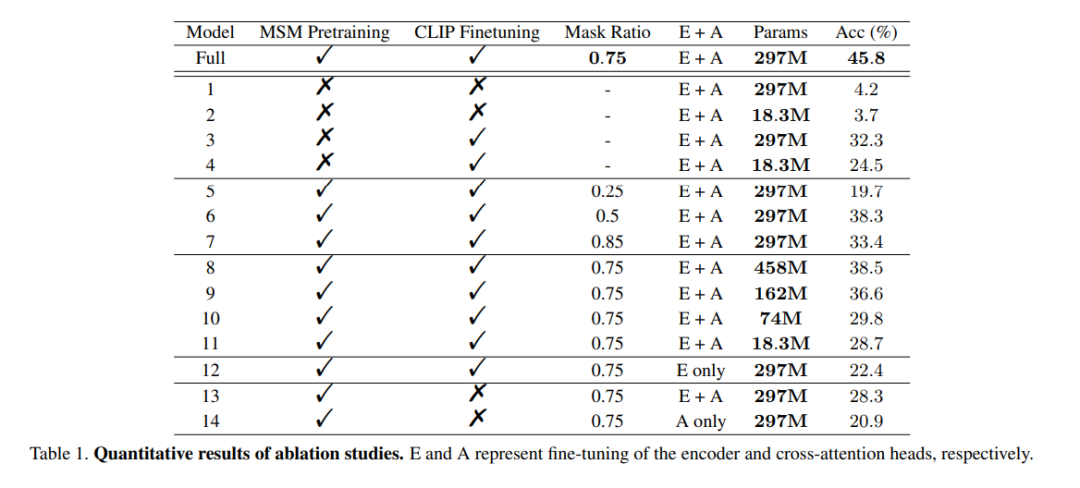
mask ratio:本文还研究了用 EEG 数据确定 MSM 预训练的最佳掩码比。如表 1 中的 Model 列的 5 到 7 所示,过高或过低的掩码比会对模型性能都会产生不利影响。当掩码比为 0.75 达到最高的整体准确率。这一发现至关重要,因为这表明,与通常使用低掩码比的自然语言处理不同,在对 EEG 进行 MSM 时,高掩码比是一个较好的选择。
CLIP 对齐:该方法的关键之一是通过 CLIP 编码器将 EEG 表征与图像对齐。该研究进行实验验证了这种方法的有效性,结果如表 1 所示。可以观察到,当没有使用 CLIP 监督时,模型的性能明显下降。实际上,如图 6 右下角所示,即使在没有预训练的情况下,使用 CLIP 对齐 EEG 特征仍然可以得到合理的结果,这凸显了 CLIP 监督在该方法中的重要性。
 图片
图片
以上就是你大脑中的画面,现在可以高清还原了的详细内容,更多请关注其它相关文章!
# ai
# 浙江电商网站推广多少钱
# seo里填写什么意思
# 刘学超seo
# 淘宝外部网站的推广特点
# 乌苏营销推广运营思路
# 大气网站建设哪家好
# 并在
# 重构
# 不太
# 很好
# 万元
# 高质量
# 所示
# 程序设计
# 掩码
# 脑中
# stable diffusion
# 创意
# 网站建设优化推广采购
# 昆山建设网站的
# 360网站优化论坛
# 新媒体营销推广的特点
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
云米Smart 2E AI立式空调开启预售:新三级能效,到手价3899元
全新“AI助手”!讯飞星火助手中心人机协作共创新生态
为了避免人工智能可能带来的灾难,我们要向核安全学习
即将到来:AI婚纱设计软件实际测试,人工智能即将开创婚纱设计新纪元
江永:精准施训提升通信无人机应急救援能力
人工智能“Aria”现身 Opera浏览器100版本更新:新功能“标签岛”
美图发布国内首个“懂美学的”AI视觉大模型MiracleVision
小艺主导智慧交互升级,借助AI大模型增强能力
意大利警察拟用AI预测犯罪 该算法被指种族歧视严重
iPhone两秒出图,目前已知的最快移动端Stable Diffusion模型来了
人工智能在交通领域的革新:智能解决方案彻底改变交通方式
酒店业将如何受益于人工智能的改变?
AYANEO AIR 1S 掌机 7 月 9 日发布:R7 7840U + OLED 屏
Hugging Face发布了基于NASA卫星数据构建的AI地理空间基础模型
人工智能助力精准学习,猿辅导小猿学练机满足学生个性化学习需求
机器人 展才能
新华三集团总裁兼首席执行官于英涛:人工智能时代需要想象力,更需要精耕务实
月薪6万,哪些AI岗位在抢人?
人手一部「*」!视频版Midjourney免费可用,一句话秒生酷炫大片惊呆网友
pixivFANBOX 更新运营规则,禁止通过外链绕开 AI 生成禁令
金山办公:AI是重要的产品战略之一
华为余承东表示:鸿蒙可能拥有强大的人工智能大模型能力
亚马逊确认今年不会举办 re:MARS 机器人和人工智能大会
如何获得元宇宙的第一个属于自己的空间
吉林首例!机器人辅助下搭桥手术成功实施
广州团建公司方案 | 绝密飞行 → X-PLANE无人机团建主题团建
首家承认ChatGPT影响其收入的公司Chegg选择拥抱AI ,裁减4%员工
编程版GPT狂飙30星,AutoGPT危险了!
AI+游戏首度大范围公布实际应用成果,AI全面来临还有多远?
黄仁勋:5年前,我们对AI抱有巨大期望
《上古卷轴5》AI高清材质包优化游戏中所有怪物
对话式论文阅读工具PaperMate上线,综述细节AI告诉你
城市在采用人工智能方面进展如何?
海南科技职业大学第25届中国机器人及人工智能大赛海南赛区荣获一等奖等114项
Intel酷睿Ultra发布会官宣!迈向全新的AI时代
如何利用AI工具写好本科论文:科技助你一臂之力
OpenAI首席执行官引用《道德经》 呼吁就AI安全问题合作
《自然》杂志拒绝刊登人工智能生成的图片和视频
7大探索区域打造沉浸式玩乐“元宇宙” 昆明京东MALL未来科技探索官全城招募中
沐曦首款AI推理GPU亮相:INT8算力达160TOPS!
谷歌内部正在测试代号为Genesis的AI新闻写作产品
一家 380 亿美元的数据巨头,要掀起企业「AI 化」革命
360发布数字安全和人工智能的强大结合:360安全大模型
小米发布CyberDog2 - 他们的第二代仿生四足机器人展示
浪潮KaiwuDB:“快人一步” - 打造更懂物联网的数据库
实测 AI 建筑设计软件的自动生成效果图能力
五款 AI 网站构建器,任何人都能快速构建网站
MetaGPT AI 模型开源:可模拟软件公司开发过程,生成高质量代码
山东机器人编程:Scratch编程基础,认识舞台!~济南机器人编程
奥比中光子公司和斯坦德机器人深度合作,共同推进新一代激光雷达的研发
2023-07-06

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
