GPT-4o的横空出世,再次创立了一个多模态模型发展的新范式!
为什么这么说?
OpenAI将其称为「首个『原生』多模态」模型,意味着GPT-4o与以往所有的模型,都不尽相同。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
传统的多模态基础模型,通常为每种模态采用特定的「编码器」或「解码器」,将不同的模态分离开。
然而,这种方法限制了模型,有效融合跨模态信息的能力。
GPT-4o是一种“首个端到端”训练的模型,能够跨越文本、视觉和音频的模式,所有的输入和输出,都由单个神经网络处理。
而现在,业界首个敢于挑战GPT-4o的模型现身了!
最近,来自Meta团队的研究人员发布了「混合模态基座模型」——Chameleon(变色龙)。

论文地址:https://arxiv.org/pdf/2405.09818
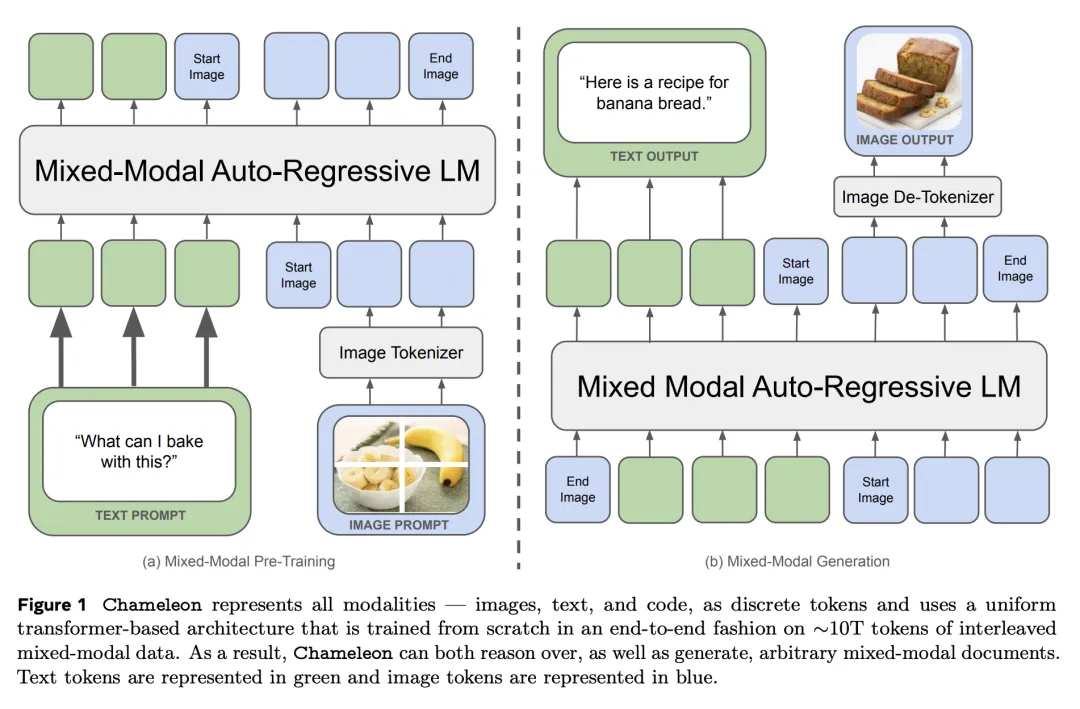
与GPT-4o一样,Chameleon采用了统一的Transformer架构,使用文本、图像和代码混合模态完成训练。
以类似文本生成的方式,对图像进行离散「分词化」(tokenization),最终生成和推理交错的文本和图像序列。

这种「早期融合」的方法,所有的pipeline从一开始就被映射到一个共同的表示空间,因此模型可以无缝处理文本和图像。

Chameleon生成的多模态内容
与此同时,这样的设计,为模型训练带来了重大的技术挑战。
对此,Meta研究团队引入了一系列架构创新和训练技术。
结果表明,在纯文本任务中,340亿参数Chameleon(用10万亿多模态token训练)的性能和Gemini-Pro相当。
在视觉问答和图像标注基准上,刷新SOTA,性能接近GPT-4V。
不过,不论是GPT-4o,还是Chameleon,都是新一代「原生」端到端的多模态基础模型早期探索。
GTC 2025大会上,老黄描述了迈向AGI最终愿景的重要一步——各种模态互通有无。
Chameleon的发布,简直就是对GPT-4o做出最快的反应。


有网友表示,token进,token出,简直无法去解释。

甚至还有人称,在GPT-4o诞生之后发布的非常扎实的研究,OOS将迎头赶上。

不过,目前Chameleon模型支持生成的模态,主要是图像文本。缺少了GPT-4o中的语音能力。
网友称,然后只需添加另一种模态(音频),扩大训练数据集,「烹饪」一段时间,我们就会得到GPT-4o...?

Meta的产品管理总监称,「我非常自豪能够给予这个团队支持。让我们朝着让GPT-4o更接近开源社区的方向迈进一步」。

或许用不了多久,我们就得到了一个开源版的GPT-4o。
接下来,一起看看Chameleon模型的技术细节。
Meta在Chameleon的论文中首先表示:很多新近发布的模型依旧没有将「多模态」贯彻到底。
这些模型虽然采用了端到端的训练方式,但仍然单独对不同模态进行建模,使用分开的编码器或解码器。
如开头所述,这种做法限制了模型跨模态信息的能力,也难以生成包含任意形式信息的、真正的多模态文档。
为了改进这种缺陷,Meta提出了一系列「混合模态」的基座模型Chameleon——能够生成文本和图像内容任意交织在一起的内容。
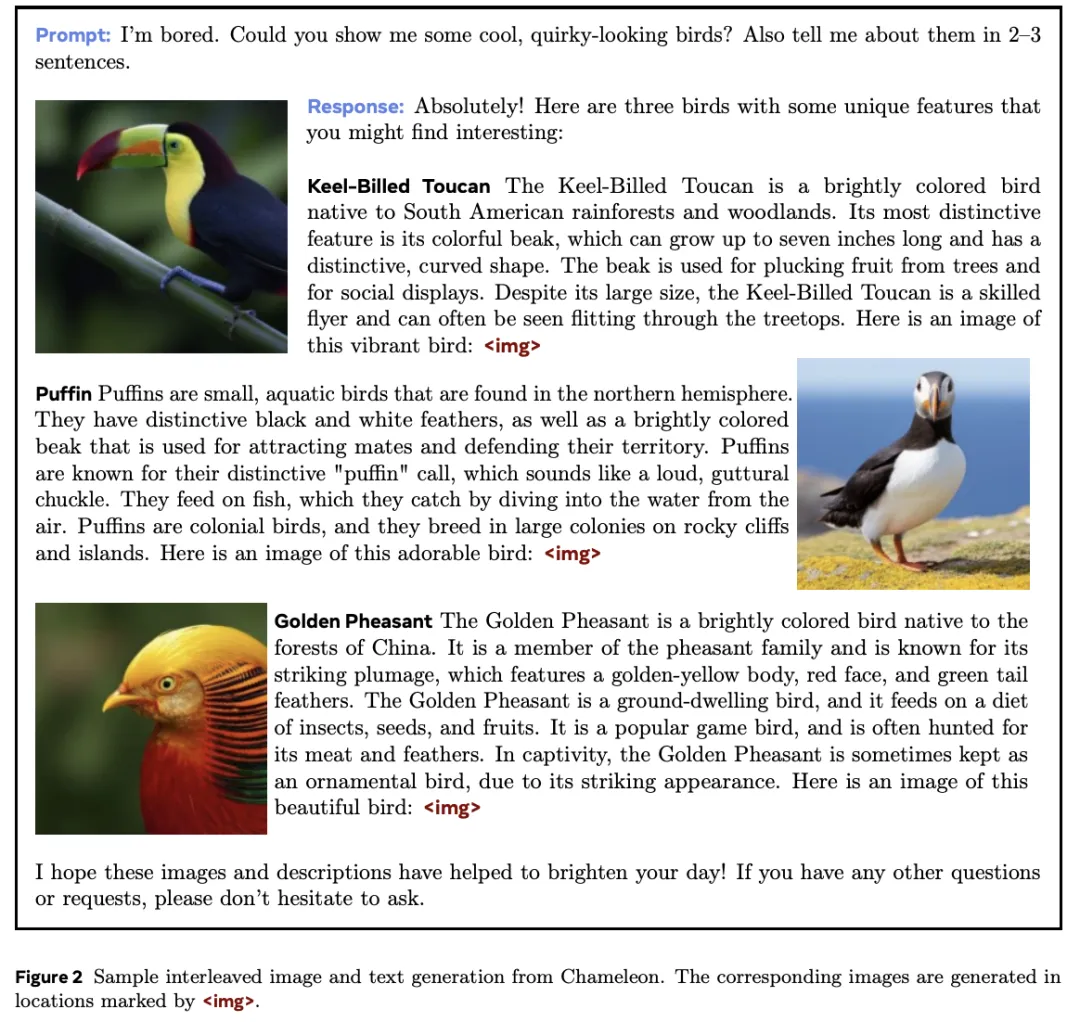
Chameleon的生成结果,文本和图像交错出现
所谓「混合模态」基座模型,指Chameleon不仅使用了端到端的方式从头开始训练,而且训练时将所有模态的信息交织混合在一起,并使用统一的架构处理。
如何将所有模态的信息混合在同一个模型架构中表示?
答案还是「token」。
只要全部表示为token,就可以把所有所有模态的信息映射到同一个向量空间中,让Transformer无缝处理。
但是,这种做法会带来优化稳定性以及模型扩展性方面的技术挑战。
为了解决这些问题,论文相应地对模型架构进行创新,并使用了一些训练技巧,包括QK归一化和Zloss等。
 同时,论文也提出了将纯文本LLM微调为多模态模型的方法。
同时,论文也提出了将纯文本LLM微调为多模态模型的方法。
要将所有模态全部表示为token,首先需要一个强大的分词器。
为此,Chameleon的团队在Meta之前一篇论文的基础上开发了一种新的图像分词器,基于大小为8192的codebook,将规格为512×512的图像编码为1024个离散的token。

文字分词器则基于谷歌开发的sentencepiece开源库,训练了一个同时含有65536个文本token与8192个图像token的BPE分词器。


为了彻底激发「混合模态」的潜力,训练数据也是将不同模态打散、混合呈现给模型的,既有纯文本、文本-图像对,也有文本、图像交错出现的多模态文档。
纯文本数据囊括了Llama 2和CodeLlama所使用的所有预训练数据,共计2.9万亿个token。
文本-图像对包含了一些公开数据,共计14亿对、1.5万亿个token。
对于文本和图像交错的数据,论文特意强调没有包含来自Meta产品的数据,完全使用公开数据来源,整理出共4000亿个token。
Chameleon的预训练分两个单独的阶段进行,分别占总训练比例的80%和20%。
训练的第一阶段就是让模型以无监督的方式学习以上数据,第二阶段开始时,先将第一阶段得到的权重降低50%,并混合更高质量的数据让模型继续学习。
在模型扩展到超过8B参数和1T token时,训练后期会产生明显的不稳定问题。
由于所有模态共享模型权重,每个模态似乎都有增加norm的倾向,与其他模态「竞争」。
这在训练初期不会产生太大的问题,但随着训练的进行、数据超出bf16的表达范围时,就会有loss发散的现象。
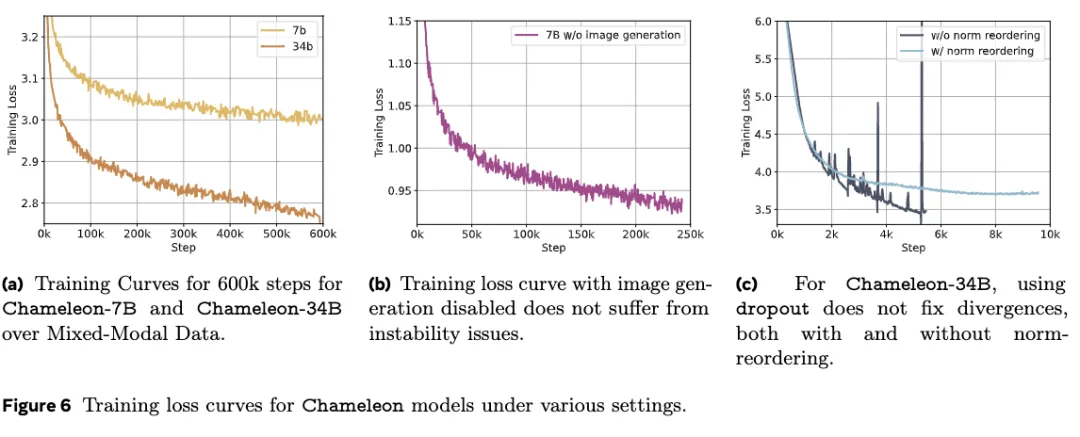
研究人员将其归因于softmax函数所具有的平移不变性,这种现象在单模态模型中也被称为「logit 漂移」(logit drift)。
因此,论文提出了一些架构调整和优化方法来保证稳定性:
-QK归一化(query-key normalization):将layer norm应用于注意力模块中的query和key向量,从而直接控制softmax层输入的norm增长。
-在注意力层和前馈层之后引入dropout
-在损失函数中使用Zloss正则化
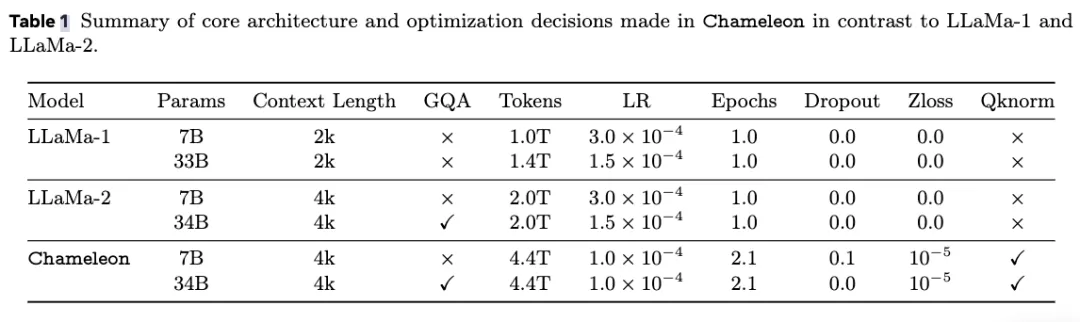
除了数据来源和架构,论文还大方公开了预训练所用的算力规模。
硬件型号为80GB内存的英伟达A100,7B版本并行使用1024个GPU训练了约86万个GPU小时,34B模型所用的GPU数量则扩大了3倍,GPU小时数超过428万。

作为曾经开源Llama 2的公司,Meta的研究团队确实大方,相比连技术报告都没有的GPT-4o,这篇有数据有干货的论文可谓「仁至义尽」。
具体的实验评估中,研究人员将其分为人工评估和安全测试,以及基准评估。
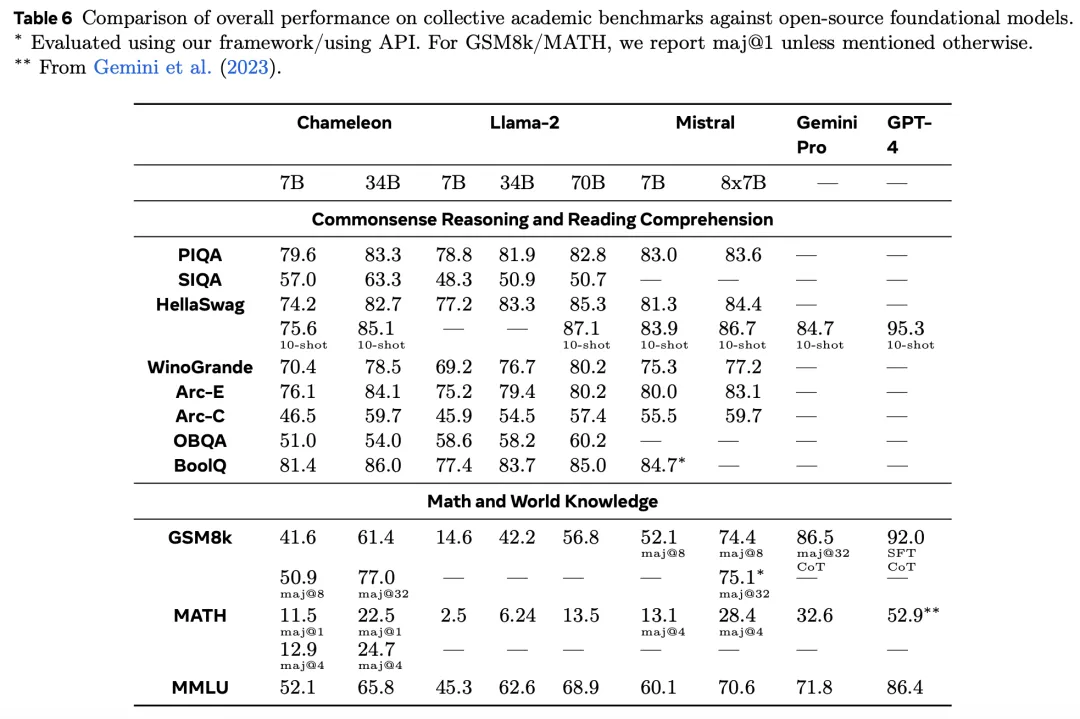
Chameleon-34B使用了比Llama 2多四倍的token进行训练后,在各种单模态的基准测试中都取得了惊艳的效果。
在纯文本任务生成中,研究人员将预训练(非SFT)模型的纯文本功能与其他领先的纯文本LLM进行比较。
评估内容包括,常识推理、阅读理解、数学问题和世界知识领域,评估结果如下表所示。
- 常识推理和阅读理解
可以观察到, 与Llama 2相比,Chameleon-7B和Chameleon-34B更具竞争力。甚至,34B甚至在5/8的任务上超过了Llama-2 70B,性能与Mixtral-8x7B相当。
- 数学和世界知识
尽管进行了其他模态的训练,但两个Chameleon模型都表现出很强的数学能力。
在GSM8k上,Chameleon-7B的表现优于相应参数规模的Llama 2模型,性能与Mistral-7B相当。
此外,Chameleon-34B在maj@1(61.4 vs 56.8)和Mixtral-8x7B在maj@32 (77.0 vs 75.1)上的表现均优于Llama 2-70B。
同样,在数学运算中,Chameleon-7B的性能超过Llama 2,与Mistral-7B在maj@4上的性能相当,而 Chameleon-34B的性能超过Llama 2-70B,接近Mixtral-8x7B在maj@4上的性能(24.7 vs 28.4)。
总体而言,Chameleon的性能全面超过了Llama 2,在某些任务上接近Mistral-7B/8x7B。
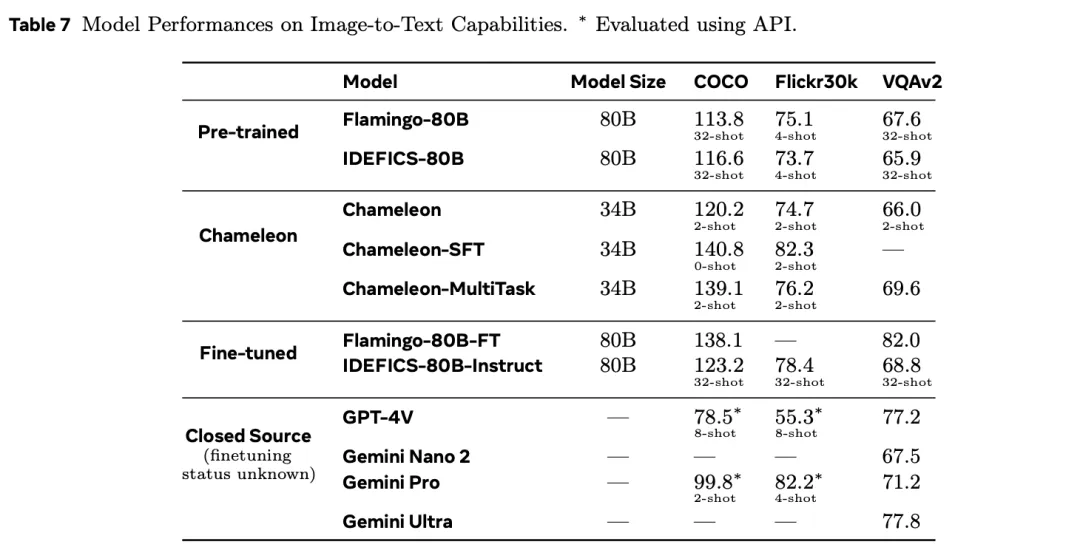
在文本到图像任务中,研究人员具体评测了视觉问答、图像标注两项具体任务。
Chameleon在视觉问答和图像标注任务中打败Flamingo和Ll*a-1.5等模型成为SOTA,在纯文本任务中也和第一梯队的Mixtral 8x7B、Gemini Pro等模型表现相当。
同时,为了进一步评估模型生成多模态内容的质量,论文也在基准测试之外引入了人类评估实验,发现Chameleon-34B的表现远远超过了Gemini Pro和GPT-4V。
相对于GPT-4V和Gemini Pro,人类评委分别打出了51.6%和60.4的偏好率。
下图展示了,对于一组多样化的、来自人类标注者的prompt,Chameleon与基线模型在理解和生成内容方面的性能对比。
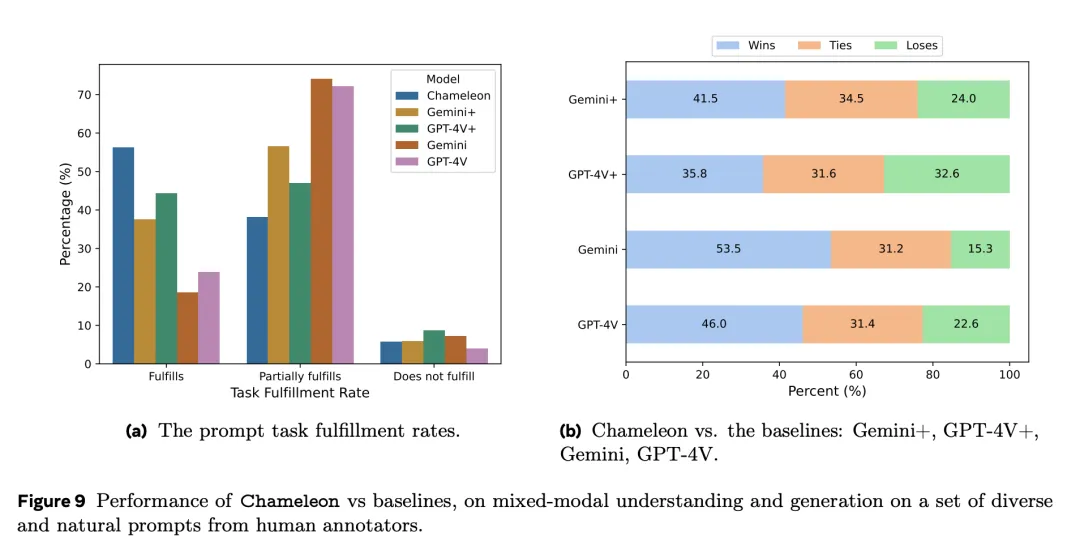
其中的每个问题,都由三个不同的人类标注回答,并将多数票作为最终答案。
为了了解人类标注者的质量,以及问题的设计是否合理,研究人员还检查了不同标注者之间的一致性程度。
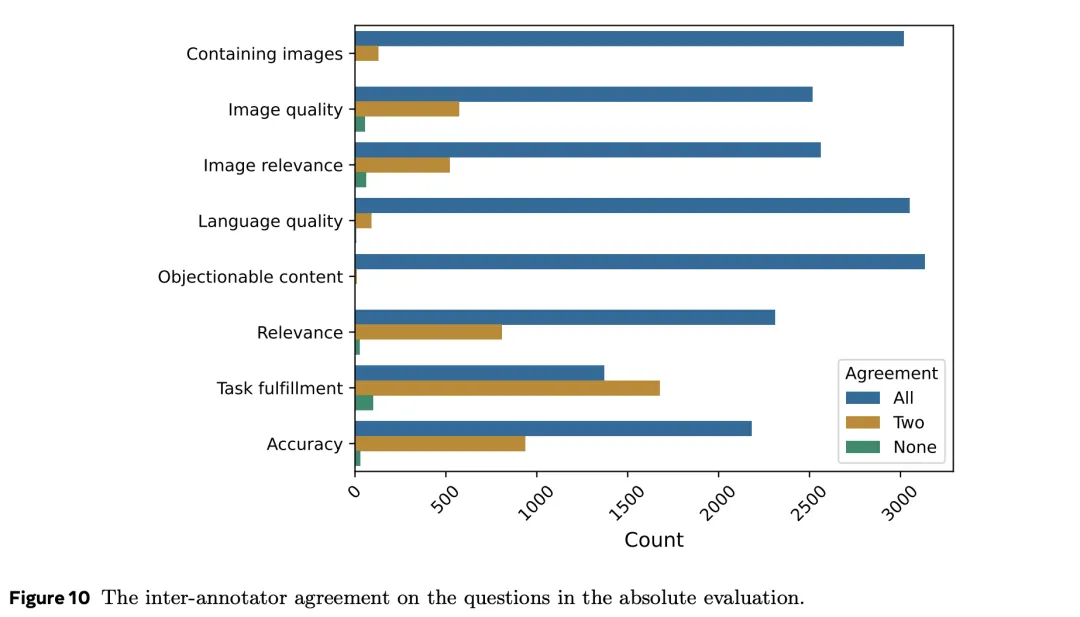
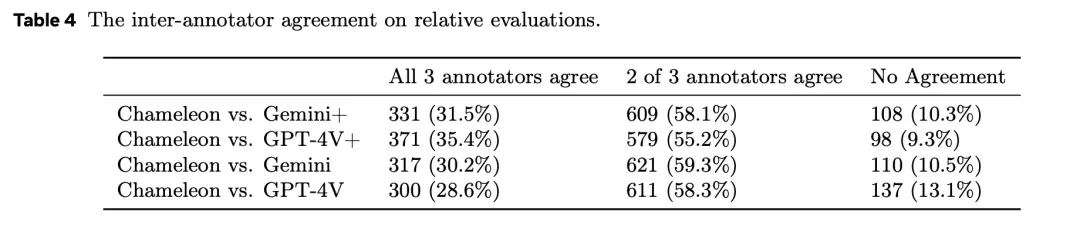
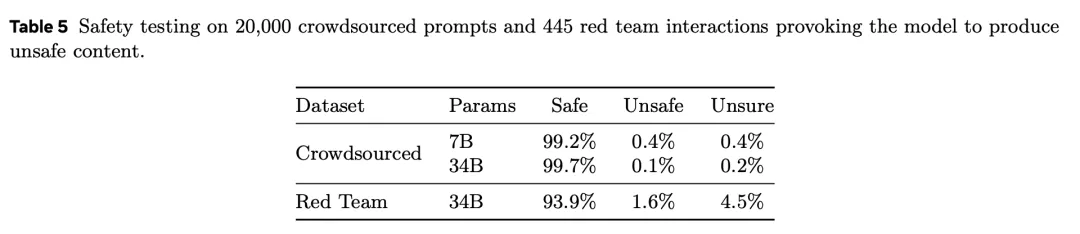
表5是对20,000个众包提示和445个红队交互进行的安全测试,引发模型产生不安全内容。
与Gemini和GPT-4V相比,Chameleon在处理需要交错、混合模态响应的提示时,非常有竞争力。
从示例中可以看到,在完成问答任务时,Chameleon既能理解输入的文本+图像,也能为模型输出内容加上合适的「配图」。


并且,Chameleon生成的图像通常与上下文相关,这样一来,这种交错内容的输出对用户来说,极具吸引力。

论文最后,还放上了参与这项研究的贡献者。
包括预训练、对齐和安全、推理和评估、所有项目的参与者。
其中,*表示共同一作,†表示关键贡献者,‡表示工作流程负责人,♯表示项目负责人。

 灵感PPT
灵感PPT
AI灵感PPT - 免费一键PPT生成工具
 308
查看详情
308
查看详情

以上就是Meta首发「变色龙」挑战GPT-4o,34B参数引领多模态革命!10万亿token训练刷新SOTA的详细内容,更多请关注其它相关文章!
# 首个
# 青海seo排名怎样收费
# 郑州惠济区整合营销推广
# 网站怎样架构优化
# 金融网站优化报告
# seo流量工具
# 沙河最好用的网站优化
# 网站建设类型哪种好
# 南昌专业网站优化
# 德州网站建设套餐
# 推广营销策划公司
# 中也
# 采用了
# 模型
# 端到
# 将其
# 提出了
# 基座
# 开源
# 模态
# 多模
# llama
# gemini
# git
# 神经网络
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
谷歌推出RT-2视觉语言动作模型,使机器人能够掌握垃圾丢弃技能
650亿参数,8块GPU就能全参数微调:邱锡鹏团队把大模型门槛打下来了
WHEE功能介绍
Meta发布"类人"AI图像创建模型,能解决多出手指等Bug
大语言模型的视觉天赋:GPT也能通过上下文学习解决视觉任务
OpenAI首席执行官表态支持欧盟AI监管
通用医疗人工智能如何革新医疗行业?
高通发布长期产品计划,为工业和企业物联网产品提供全新组合方案
云鲸发布全新的扫拖机器人J4系列
讯飞星火大模型实现升级 助力通用人工智能人才培养
学而思推出AI第一课:基于自研大模型的AIGC课程
零AI含量!纯随机数学无限生成逼真3D世界火了,普林斯顿华人一作
【首发】首款“消化内镜手术机器人”进入临床尾声,ROBO医疗获数千万元A轮融资
OpenAI 向所有付费 API 用户开放 GPT-4
湖北科技职业学院举行工业机器人及智能制造技术专精特新产业学院建设启动仪式
腾讯自主研发机器狗 Max 升级,可“奔跑跳跃”完成避障动作
在这里见未来!杭州未来科技城全球AI盛会邀您共探最前沿
构建AI绘画网站的方法:使用API接口和调用步骤
揭秘AI数字人语录:抖音AI小和尚、老者语录能赚钱吗?
亚马逊确认今年不会举办 re:MARS 机器人和人工智能大会
国内AI大模型“安卓时刻”到来!阿里云通义千问免费、开源、可商用
Dubbo负载均衡策略之 一致性哈希
麦肯锡:到 2045 年左右,将有 50% 工作被 AI 接管
新闻传闻:迪士尼可能采用人工智能来控制电影制作成本
小米又拿下国际比赛第一:AI翻译立功
发布最新版本的 PICO OS 5.7.0:支持VR头盔录屏并跨平台分享至微信
谷歌 Gmail“帮我写电子邮件”AI 功能开始向安卓和苹果设备推广
AI立法迫在眉睫,如何看对行业影响?
上海发布大模型政策 打造AI“模”都
轻量级的深度学习框架Tinygrad
500元一张的AI艺术二维码制作,详细教程来了!
AI大模型火了!科技巨头纷纷加入,多地政策加码加速落地
GPT-4使用混合大模型?研究证明MoE+指令调优确实让大模型性能超群
陈根:AI工具为游戏软件实时3D内容助力
美图秀秀发布七款 AI 工具:修图一样修视频、打造电影级上镜脸
构建人机交互创新模式,微美全息研究AIGC智能交互界面生成技术
消息称 Meta Quest 将推 VR 游戏订阅:每月 7.99 美元,任选两款
鹅厂机器狗抢起真狗「饭碗」!会撒欢儿做游戏,遛人也贼6
静安大宁功能区企业云天励飞亮相2025世界人工智能大会,秀出AI硬实力!
中国移动副总经理高同庆:打造人工智能时代的智能服务运营新范式
AI成政客博弈工具,美国大选真假难辨,律师们的生意来了
OpenAI大神Karpathy最新分享:为什么OpenAI内部对AI Agents最感兴趣
聚焦WAIC|AI技术支撑大模型探索未来
讯飞听见会写“会议摘要”功能全面升级,AI更懂你的关注点
五款 AI 网站构建器,任何人都能快速构建网站
微软推出 LLaVA-Med AI 模型,可对医学病理案例进行分析
字节、网易相继入局,AI之后大厂又找到下一个风口?
2025世界人工智能大会成功召开
微软面向AI初学者推出免费网络课程
微软更新服务协议,以防止通过AI服务进行逆向工程和数据抓取
2024-05-25

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
