
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
minicpm-v团队主要作者是余天予,他是清华大学2025级硕士研究生,他的主要研究方向是通用多模态基础大模型构建及其对齐方法。
近期,由清华大学自然语言处理实验室联合面壁智能推出的全新开源多模态大模型 MiniCPM-Llama3-V 2.5 引起了广泛关注,在发布后火速登顶 Hugging Face、GitHub、Papers With Code 的 Trending 榜首,与 Meta、微软、谷歌等科技巨头共同从全球 66 万模型中脱颖而出。与此同时,该模型使用的多模态对齐数据集也登上了 Hugging Face Trending 第二位。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
仅有 8B 体量的 MiniCPM-Llama3-V 2.5 不仅在多模态综合性能上超越了商用闭源的 GPT-4V、Gemini Pro、Claude3,同时在模型可信度方面也达到了开源模型中的最高水平。其出色的性能离不开背后的一项关键性技术 ——RLAIF-V。这项技术基于完全开源的范式进行多模态大模型的对齐,实现了超越 GPT-4V 的可信度。

论文:RLAIF-V: Aligning MLLMs through Open-Source AI Feedback for Super GPT-4V Trustworthiness
论文地址: https://arxiv.org/abs/2405.17220
项目地址:https://github.com/RLHF-V/RLAIF-V
DEMO:https://huggingface.co/spaces/openbmb/RLAIF-V-12B
RLAIF-V 核心特点
从亦步亦趋迈向切磋琢磨,通过开源反馈实现超越 GPT-4V 的可信度。
已有的多模态大模型对齐方案主要采用蒸馏 GPT-4V 等昂贵的闭源模型的方式,实际上提供了一种模仿的方法(“亦步亦趋”)。随着开源社区的不断发展,我们急需一种能够让开源模型利用能力相仿或者相同的模型提供反馈,进行自动对齐的方案(“切磋琢磨”)。RLAIF-V 通过无偏候选构造和分而治之的反馈收集策略,可以从 OmniLMM 12B 等常规开源模型收集大规模的高质量反馈数据。通过充分利用这些数据,RLAIF-V 12B 模型在生成任务和判别任务中都实现了超越 GPT-4V 的可信度。

RLAIF-V 学习范式与模型可信度对比
具备优秀泛用性的大规模高质量反馈数据。
研究团队将训练 RLAIF-V 7B 和 RLAIF-V 12B 过程中所构造的高质量对齐数据整理为规模超过 83k 的多任务多模态对齐数据集 RLAIF-V Dataset,包括图片详细描述、图片知识问答、文字识别等多类指令,图片种类覆盖照片、艺术作品、名人、地标、场景文字等。实验表明,该数据集可有效减少 LLaVA 1.5, MiniCPM-V 等不同多模态大模型在多种任务中的幻觉,展现出了优秀的泛用性。

RLAIF-V 数据泛用性
迭代对齐的高效反馈学习。
在现有的模型训练中,采用的偏好数据是静态的,但随着训练的进行,模型的输出分布却在不断变化,这导致训练数据分布与模型真实分布产生偏移,从而无法充分利用偏好数据,影响模型的对齐效率。RLAIF-V 采用了迭代的方式进行对齐训练,相较于非迭代方法表现出了更高的学习效率和更好的性能,具有更优秀的规模效应。

迭代与非迭代式训练的效果对比
更可靠全面的多模态评测集 RefoMB。
随着模型能力的发展,已有的评测集或存在评测饱和的情况,或评测准确性不足,从而难以正确区分不同可信度的模型。为此,RLAIF-V 提出了新的 RefoMB 评测集,其指令覆盖了多模态模型感知和推理任务中的 8 个子能力,并包含了卡通图片、富文字图片、照片等多样化的图片类型,用于评估现有多模态模型在开放生成时的回复可信度和通用性能。通过人工标注图片详细描述作为评判参考,RefoMB 有效提高了评测准确性,人工一致性可以达到 96%。

RefoMB 指令类型分布
RLAIF-V 框架
RLAIF-V 包含两项创新方法:数据层面,提出完全基于开源模型的高质量反馈数据构造方法;算法层面,采用迭代对齐算法进行模型优化。

RLAIF-V 框架
大规模高质量开源模型反馈数据的构造
为了减小反馈对齐数据的获取成本,实现规模化的反馈对齐数据获取,并提高开源多模态大模型提供反馈的质量,研究团队结合分而治之的思想,提出了如下数据构造流程以实现高质量开源模型反馈的获取:
无偏候选回复生成(deconfounded candidate response generation):使用随机解码方法生成多个候选响应。在这种生成方式下,不同回复来自一个相同的分布,有效消除了样本对之间的文本风格差异等混淆因素,使训练过程专注于内容的可信度,从而提高数据效率。
分而治之(divide-and-conquer):将复杂的响应分解为更简单、可以单独评估的子问题。这种简化使开源多模态大模型可以提供更可靠的反馈。
应用这种数据构造方法,我们不仅可以利用具有更高模型性能的开源多模态大模型为性能较弱的模型提供反馈,还能够通过模型自身反馈的方式,使 OmniLMM 12B 模型实现超越 GPT-4V 的可信度。
迭代对齐算法
为了缓解现有对齐算法存在的分布偏移问题,一个直接的思路是在每步优化时更新反馈数据。但是,这种在线反馈的方式开销大、训练不稳定。因此,研究团队采用了一种迭代对齐算法,在每轮迭代中更新反馈数据,提升数据与模型分布的一致性。具体而言,在每一轮迭代时,利用上一轮训练得到的模型权重生成新的反馈数据,并使用新数据进行训练。

迭代对齐算法
RefoMB 评测集
在开放问答下的多模态幻觉评测中,有两类常见评测方式。一类是利用图片标注的常见物体类型,对模型回复中的存在性幻觉进行评测的方式,例如基于 MSCOCO 标注信息的 CHAIR 评测。另一类则利用 GPT-4 模型作为裁判,根据参考信息对模型回复的可信度进行打分,如 MMHal Bench 评测。
然而,随着模型能力的增强,仅考虑物体存在性幻觉的评测指标接近饱和,难以区分更加先进的模型之间的可信度差异;而采用 GPT-4 打分的形式构造的评测集则因为提供的图片参考信息缺乏全面性,影响了可信度判断的准确性。
针对这两个问题,我们需要一个更加准确、且能够评估更加全面的幻觉类型的评测集,以真实反映目前多模态模型的可信度情况。为此,研究团队采用了如下方法:
 码上飞
码上飞
码上飞(CodeFlying) 是一款AI自动化开发平台,通过自然语言描述即可自动生成完整应用程序。
 430
查看详情
430
查看详情

人工标注详尽图片描述:通过提供人工标注的详尽图片描述,GPT-4 模型能够更好地掌握图片的完整信息,从而提供更准确的判断。

人工标注详尽图片描述样例
基于比较的评估:受语言大模型评测集 AlpacaEval 的启发,研究团队采用 GPT-4 模型对两个多模态模型的回复优劣进行比较,并选择其中更优的回复。相比于直接对模型回复进行打分,这种比较的形式可以产生更高的判断准确率。

评测结果样例
通过以上改进,RefoMB 能够在人工一致性上显著优于已有的开放问答幻觉评测集 MMHal Bench,达到 96% 的准确率。

RefoMB 与 MMHal Bench 的评测人工一致性比较
实验验证和结果
1.RLAIF-V 在 LLaVA 1.5 和 OmniLMM 两种多模态大模型上均产生了显著的可信度提升。
为了评估模型的幻觉水平,研究团队测试了模型在开放生成任务和幻觉识别任务中的可信度表现。团队还通过 LLaVA Bench 评测集评估了模型在开放对话和推理方面的性能。此外,为了全面了解模型的通用能力,研究团队还在结合了 6 个常用多模态评测数据集的综合评测集 MMStar 上进行了测试。
实验结果表明:相比于人类反馈和 GPT-4V 反馈,RLAIF-V 提出的开源模型反馈方法甚至实现了更好的效果。RLAIF-V 12B 模型更是在幻觉评测指标上远超已有的开源多模态大模型甚至 GPT-4V,在通用能力方面也能维持优秀的性能。
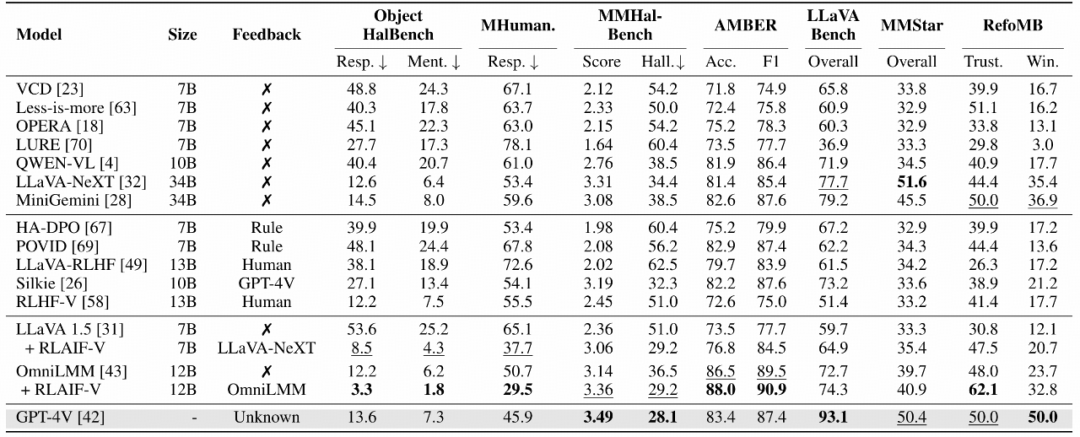
RLAIF-V 与其他开源模型及 GPT-4V 在可信度和通用能力上的对比
2. 采用 RLAIF-V 提出的分治反馈方法能够有效提高开源多模态大模型的反馈质量。
为了验证 RLAIF-V 所提分治算法的有效性,研究团队分别对三种不同的反馈模型采用直接反馈与分治反馈的方式构造了训练数据,并评测训练后模型在开放生成任务和幻觉识别任务中的可信度表现。
实验结果表明,在不同性能的反馈模型中,采用分治反馈方式训练得到的模型效果均显著优于直接反馈。

分治反馈算法与直接反馈相比的模型可信度对比
3.RLAIF-V 数据能够与其他多模态反馈数据互补,进一步提升模型可信度。
目前已经有一些工作构造了基于人工标注或启发式规则的多模态反馈数据,为了探究不同方法构造数据之间的互补性,研究团队将不同类型的反馈数据进行了合并训练,并观察模型性能的变化。从实验结果来看,应用 RLAIF-V 数据能够显著提高模型可信度,而进一步融合其他反馈数据时,模型可信度能够进一步提升。
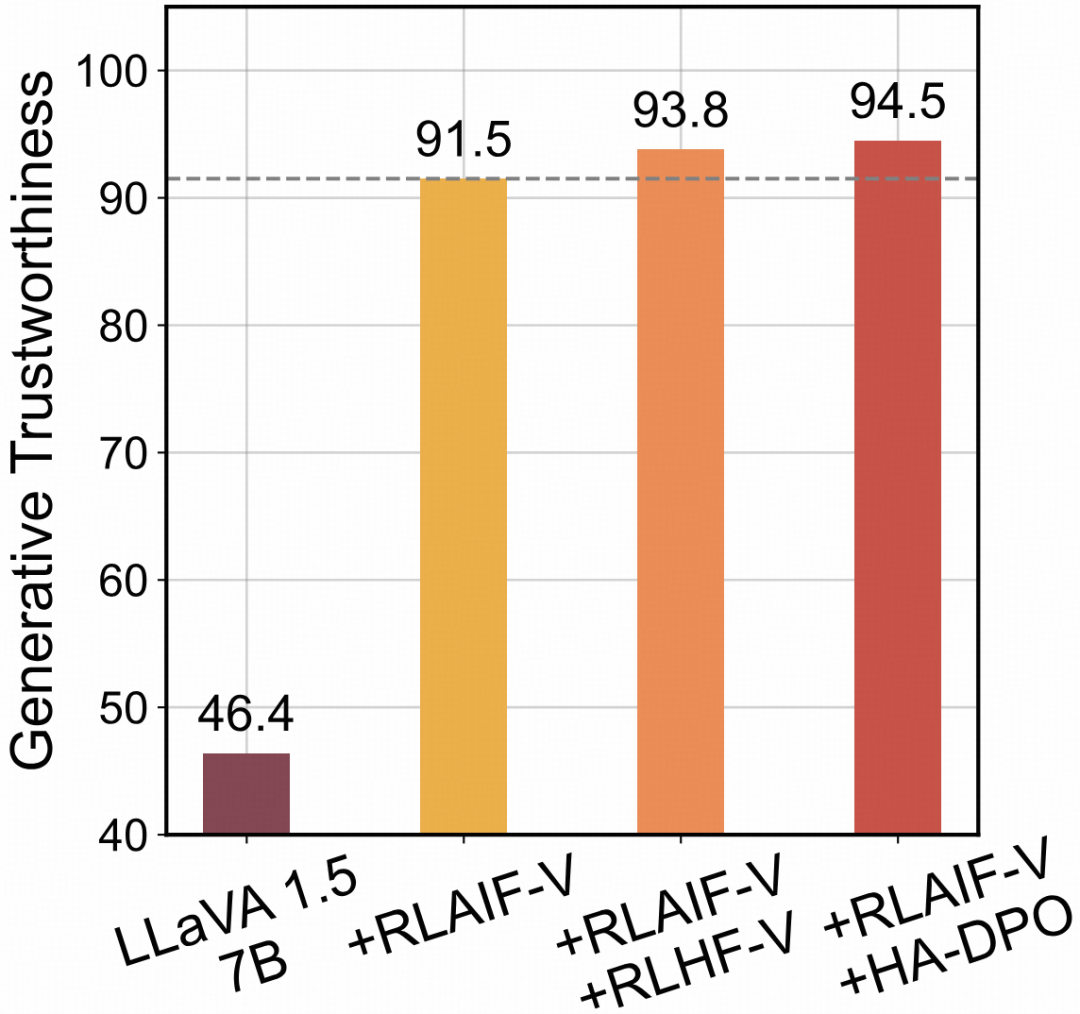
同时使用 RLAIF-V 数据与其他多模态反馈数据的效果
效果展示
使用 RLAIF-V 方法训练 LLaVA 1.5 7B 模型以及 OmniLMM 12B 模型后,在开放生成问题下,RLAIF-V 模型与 GPT-4V 模型的表现如下:
测试效果 1:RLAIF-V 7B 模型能够进行正确的推理,并具有更优的可信度。

RLAIF-V 7B 与 GPT-4V 效果对比,其中红色部分为幻觉,绿色部分为正确的回答。注:原始问题和回答均为英文,翻译为中文方便阅读
当用户提问 “分析图中任务之间的关系” 时,RLAIF-V 7B 与 GPT-4V 均能够根据图中的信息判断出同事关系,但 GPT-4V 错误地认为讲话者是站立的状态,产生了人物动作上的幻觉。
测试效果 2:RLAIF-V 12B 模型能够在回复可信度上显著优于 GPT-4V。

RLAIF-V 12B 与 GPT-4V 效果对比,其中红色部分为幻觉,绿色部分为正确的回答。注:原始问题和回答均为英文,翻译为中文方便阅读
可以看到,当用户提问:“图中可以看到的主要颜色是哪些” 时,RLAIF-V 12B 以及 GPT-4V 均能够正确回答出问题。但 GPT-4V 的回答中对文字颜色和背景颜色的识别均产生了 错误。
错误。
测试效果 3:在更多类型的图片和指令上,例如代码问答任务上,RLAIF-V 方法同样能减少模型幻觉,产生更可信的回复。

LAIF-V 12B 与 GPT-4V 效果对比,其中红色部分为幻觉,绿色部分为正确的回答。注:原始问题和回答均为英文,翻译为中文方便阅读
当要求模型解释代码输出时,RLAIF-V 12B 与 GPT-4V 均能够正确推理出代码的运行结果,但 GPT-4V 错误地认为图片中缺少一个分号,因此代码无法编译成功。这表明 RLAIF-V 方法所构造的偏好对齐数据能够让模型在诸如 OCR 等更广泛的能力上的可信度同步提高。
总结
将模型输出对齐人类偏好是构建实用化人工智能的关键环节。RLAIF-V 方法通过分而治之与迭代式训练的方式实现了仅利用开源模型进行可信度提升的对齐目标。未来,研究团队也将进一步探索逻辑推理、复杂任务等更广泛能力上的对齐方法。
以上就是可信度超越GPT-4V,清华&面壁揭秘「小钢炮」模型背后的高效对齐技术的详细内容,更多请关注其它相关文章!
# 分而治之
# 扬州网站建设推广招聘网
# seo炒作
# 手机网站建设哪家做得好
# 微博营销推广方案设计
# 市场营销的营业推广方式
# 新营销推广软件
# 企业网站网站建设
# 广东推广网站建设怎么做
# 关键词手机排名优化
# 慈溪seo外包
# 采用了
# 英文
# 切磋琢磨
# 均为
# 产业
# 高质量
# 迭代
# 开源
# 多模
# 清华
# claude
# gemini
# openbmb
# hugging face
# git
# rlaif-v
# 面壁智能
# 清华大学
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
国内阅读行业首款对话式AI应用“阅爱聊”封闭内测
Vision Pro 太贵,苹果基于 iPhone 的 VR 头显专利曝光
微软为 AI 初学者推出免费网课:为期 12 周,共 24 节课
pixivFANBOX 更新运营规则,禁止通过外链绕开 AI 生成禁令
小岛秀夫不反对使用AI 但认为人类应该凌驾于AI
亚马逊确认今年不会举办 re:MARS 机器人和人工智能大会
PS AI修图免费平替来了!Stability AI又放大招,核弹级更新一键扩图
农业产业升级:AI驱动的“崃·见田”开启农田未来展望
V社悄悄封禁使用AI生成美术素材的游戏
全国体育人工智能大会举办,专家聚焦体育人工智能领域人才培养
美妆行业在AI时代蓬勃发展
Moka AI产品后观察:HR SaaS迈进AGI时代
生成式人工智能如何改变云安全的游戏规则
“三夏”农忙保障用电,无人机高空巡视高压线
ChatGPT大更新!OpenAI奉上程序员大礼包:API新增杀手级能力还降价,新模型、四倍上下文都来了
首家承认ChatGPT影响其收入的公司Chegg选择拥抱AI ,裁减4%员工
MiracleVision视觉大模型
真全息产品,亮相深圳文博会——dipal数伴拓展元宇宙非沉浸式体验
微软商店 AI 摘要功能开启预览,帮助用户迅速了解应用评价
七大主流AI企业包括OpenAI、谷歌等联合承诺:引入水印技术,并允许第三方审核AI内容
XREAL发布新款硬件XREAL Beam投屏盒子:可悬停AR空间屏
李开复:未来几年,人工智能会革了所有人的命,除非你这么做
丰田汽车研究院推出生成式人工智能汽车设计工具
OpenAI已向中国申请注册“GPT-5”商标,此前已在美国提交申请
海南科技职业大学第25届中国机器人及人工智能大赛海南赛区荣获一等奖等114项
如布科技发布新产品AI口袋学习机S12
Gartner预测:到2025年,全球对话式人工智能支出预计将达到1860亿美元
人工智能时代 数字文明对话向“尼”走来
OpenAI 向所有付费 API 用户开放 GPT-4
企业软件行业更将被AI全面重构!Moka李国兴:未来优秀组织和个人将一定是善于使用AI生产力的
清华&中国气象局大模型登Nature:解决世界级难题,「鬼天气」预报时效首次达3小时
1000万张照片训练AI模型 科学家找到水下定位新方法
了解 AGI:智能的未来?
美图发布国内首个“懂美学的”AI视觉大模型MiracleVision
人形机器人打开精密齿轮市场全新空间!受益上市公司梳理
写出优质文章的妙招:利用"稿见AI助手"的实用指南
当科幻走进现实 脑机接口新技术能为生活带来哪些惊喜?
百度创始人、董事长兼首席执行官李彦宏:AI原生应用比大模型数量更重要
微软面向AI初学者推出免费网络课程
日媒:AI高效解析纳斯卡地画
普林斯顿Infinigen矩阵开启!AI造物主100%创造大自然,逼真到炸裂
AI 作画工具 Midjourney 推出“pan”功能,可平移扩展图片外场景
世界水下机器人大赛:9国青年携手逐梦深蓝
字节、网易相继入局,AI之后大厂又找到下一个风口?
人工智能如何用于家庭安全
两架海燕号无人机交付中国气象局 助力建设国家级机动气象观测业务
“一般智力”与工艺学批判是认识AI的重要入口 | 社会科学报
“长沙造”无人机,领先的不止植保
论文插图也能自动生成了,用到了扩散模型,还被ICLR接收
世界人工智能大会|“AI领航,共筑未来”高端保险论坛成功举办
2024-06-11

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
