
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜


 token 的 logit 会基于新的情况进行调整。这两种情况的 logit 变化量代表着图片这个新的条件对每个文本 token 的影响大小。
token 的 logit 会基于新的情况进行调整。这两种情况的 logit 变化量代表着图片这个新的条件对每个文本 token 的影响大小。


 码上飞
码上飞
码上飞(CodeFlying) 是一款AI自动化开发平台,通过自然语言描述即可自动生成完整应用程序。
 430
查看详情
430
查看详情

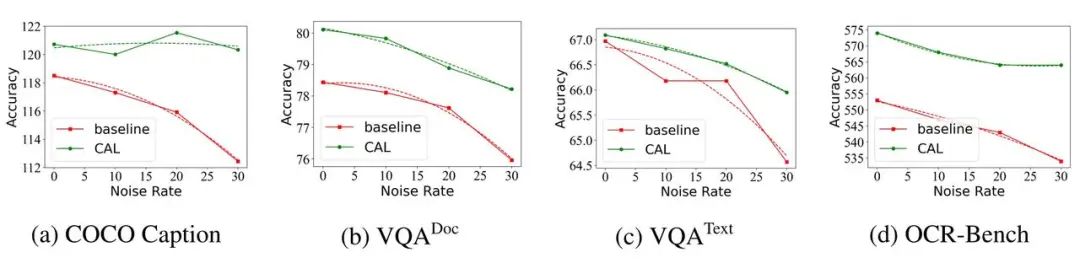


以上就是字节豆包、武大提出 CAL:通过视觉相关的 token 增强多模态对齐效果的详细内容,更多请关注其它相关文章!
# 会议纪要
# 北京建设网站哪里好
# 蛇口价格低的网站建设
# 建设厅网站男人分手
# 快速的网站排名优化
# 营销人员的推广工具
# 关键词排名seo优化什么意思
# seo如何快速排名首页
# 昆明学习网站建设
# 武汉抖音seo公司
# 亭湖区seo优化性价比
# 越大
# 可以通过
# 字节跳动
# 什么时候
# 图上
# 模态
# 过程中
# 这一
# 情况下
# 多模
# type
# git
# 豆包大模型
# 工程
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
改动一行代码,PyTorch训练三倍提速,这些「高级技术」是关键
世界人工智能大会高合发表演讲,HiPhi Y即将全球上市
小米9号员工李明宣布创业:打造首款安卓桌面机器人
剧透!蜜小豆@2025世界人工智能大会多个亮点曝光
NVIDIA垄断AI市场90%份额:AMD性能追上80% 软件太不能打
人工智能驱动艺术,打开达利的超现实想象
纪录片 《寻找人工智能》全集1080P超清
元宇宙迈入2.0时代,它和生成式人工智能有何关联吗?
国产工业机器人领域“暗潮涌动”,即将迎来新一轮复苏
谷歌借AI打破十年排序算法封印,每天被执行数万亿次,网友却说是最不切实际的研究?
常见的五个人工智能误解
商业智能决策技术助力降本增效,世界人工智能大会举办商业AI高峰论坛
“聚智启新,‘蓉’力同行” 成都市人工智能产业融通对接会成功举办
WHEE安装教程
AI大举入侵内容行业,哪些上市*及动漫公司进行了布局?
马斯克发推讽刺人工智能:机器学习的本质就是统计
特斯拉首发人形机器人“擎天柱”亮相世界人工智能大会
第四范式“式说”大模型入选《2025年通用人工智能创新应用案例集》
Xbox游戏工作室负责人:VR/AR领域的用户规模还不足够
一次购买全年省心,入手科沃斯这几台机器人,省下时间就是金钱
磐镭发布全新 GeForce RTX 4080 ARMOUR 显卡,售价为 9499 元
上天下海登极,青岛与昇腾AI握手一起探索星辰大海
建立元宇宙产业联盟:移动、咪咕、华为、小米等加入
成都大运会闭幕式引入人形机器人展示表演
华为推出两款商用 AI 大模型存储新品,支持 1200 万 IOPS 性能
稿见AI助手:提升写作效率与质量的必备工具
AI智能室内效果图设计软件效果,确实惊到我了!
苹果机器学习关键人物 Ali Farhadi 离职,回归 AI2 担任 CEO
朱民:普通人炒股炒不过机器人是很正常的 AI已经能理解市场情绪
小米创始人雷军将揭示小米AI在年度演讲中的最新进展
写出优质文章的妙招:利用"稿见AI助手"的实用指南
「模仿学习」只会套话?解释微调+130亿参数Orca:推理能力打平ChatGPT
人手一部「*」!视频版Midjourney免费可用,一句话秒生酷炫大片惊呆网友
如何用Transformer BEV克服自动驾驶的极端情况?
陈根教授:离人形机器人时代还有10年吗?
微盟宣布联合腾讯云共建行业大模型:加快激活AI大模型智能应用
谷歌AudioPaLM实现「文本+音频」双模态解决,说听两用大模型
无人机巡检方案是什么,该如何选择适合的巡检方案
美图公司吴欣鸿:AI技术重构影像产业
乐天派桌面机器人加入小米米家生态系统,实现与其他智能设备的互联
AIGC浪潮下,联想集团再加码计算与人工智能
马斯克预测:特斯拉全自动驾驶将在今年实现 对AI深度变化感到担忧
在这里见未来!杭州未来科技城全球AI盛会邀您共探最前沿
首部国内AI辅助动画片《魔游纪:人工智能辅助篇》预告发布
从医疗康复外骨骼到通用人形机器人,傅利叶智能推动核心技术升级
三星加速AR眼镜进程,预计明年上半年亮相
XREAL发布新款硬件XREAL Beam投屏盒子:可悬停AR空间屏
南京制造的国产工业机器人:在外资品牌竞争中突围,年销售1.8万台
真全息产品,亮相深圳文博会——dipal数伴拓展元宇宙非沉浸式体验
华为将于 7 月发布面向 AI 大模型的新款存储产品
2024-06-18

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
