奥林匹克竞赛里选最聪明的AI:Claude-3.5-Sonnet vs. GPT-4o?
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
上海交通大学生成式人工智能实验室 (GAIR Lab) 的研究团队,主要研究方向是:大模型训练、对齐与评估。AI技术日新月异,近来Anthropic公司最新发布的Claude-3.5-Sonnet因在知识型推理、数学推理、编程任务及视觉推理等任务上设立新行业基准而引发广泛讨论:Claude-3.5-Sonnet 已经取代OpenAI的GPT4o成为世界上”最聪明的AI“(Most Intelligent AI)了吗?回答这个问题的挑战在于我们首先需要一个足够挑战的智力测试基准,使得我们可以区分目前最高水平的AI。上海交通大学生成式人工智能实验室(GAIR Lab)推出的OlympicArena[1] (奥林匹克竞技场)满足了这个需求。奥林匹克学科竞赛不仅是对人类(碳基智能)思维敏捷性、知识掌握和逻辑推理的极限挑战,更是AI(“硅基智能”)锻炼的绝佳练兵场,是衡量AI与“超级智能”距离的重要标尺。OlympicArena——一个真正意义上的AI奥运竞技场。在这里,AI不仅要展示其在传统学科知识上的深度(数学、物理、生物、化学、地理等顶级竞赛),还要在模型间的认知推理能力上展开较量。
近日,同样是研究团队,首次提出使用"奥林匹克竞赛奖牌榜"的方法,根据各AI模型在奥林匹克竞技场(各学科)的综合表现进行排名,选出迄今为止智力最高的AI。在此次竞技场中,研究团队重点分析并比较了最近发布的两个先进模型——Claude-3.5-Sonnet和Gemini-1.5-Pro,以及OpenAI的GPT-4系列(e.g., GPT4o)。通过这种方式,研究团队希望能够更有效地评估和推动AI技术的发展。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
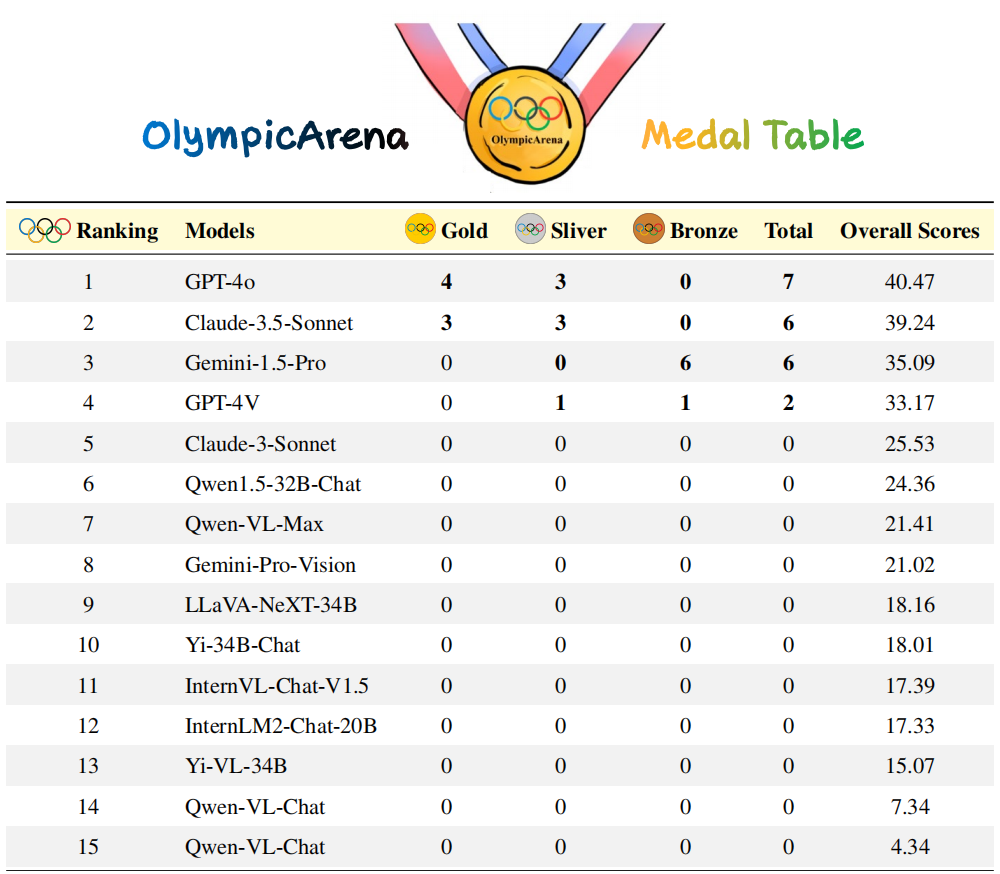
注:研究团队首先依据金牌数量对模型进行排序,如果金牌数量相同,则按照整体性能分数来排序。
- Claude-3.5-Sonnet在整体表现上与GPT-4o相比极具竞争力,甚至在一些科目上超过了GPT-4o(比如在物理、化学和生物学上)。
- Gemini-1.5-Pro和GPT-4V排名紧随GPT-4o和Claude-3.5-Sonnet之后,但它们之间存在明显的表现差距。
- 来自开源社区的AI模型性能明显落后于这些专有模型。
- 这些模型在此基准测试上的表现不尽人意,表明我们在实现超级智能之路上还有很长的路要走。
- 项目主页:https://gair-nlp.github.io/OlympicArena/
研究团队采取OlympicArena的测试集进行评估。该测试集的答案并未公开,有助于防止数据泄露,从而反映模型的真实性能。研究团队测试了多模态大模型(LMMs)和纯文本大模型(LLMs)。对于LLMs的测试,输入时不提供任何与图像相关的信息给模型,仅提供文本。所有评估均采用零样本(zero-shot)思维链(Chain of Thought)提示词。研究团队评估了一系列开源和闭源的多模态大模型(LMMs)和纯文本大模型(LLMs)。对于LMMs,选择了GPT-4o、GPT-4V、Claude-3-Sonnet、Gemini Pro Vision、Qwen-VL-Max等闭源模型,此外还评估了LLaVA-NeXT-34B、InternVL-Chat-V1.5、Yi-VL-34B和Qwen-VL-Chat等开源模型。对于LLMs,主要评估了Qwen-7B-Chat、Qwen1.5-32B-Chat、Yi-34B-Chat和InternLM2-Chat-20B等开源模型。此外,研究团队特别包括了新发布的Claude-3.5-Sonnet以及Gemini-1.5-Pro,并将它们与强大的GPT-4o和GPT-4V进行比较。以反映最新的模型性能表现。衡量标准 鉴于所有问题都可以通过基于规则的匹配进行评估,研究团队对非编程任务使用准确率,并对编程任务使用公正的pass@k指标,定义如下: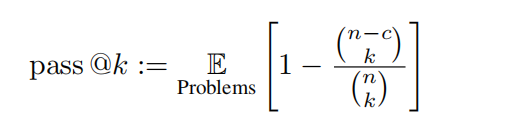
本次评估中设定k = 1且n = 5,c表示通过所有测试用例的正确样本数量。与奥运会使用的奖牌系统类似,是一个专门设计用来评估AI模型在各个学术领域性能的先驱性排名机制。该表为在任一给定学科中取得前三名成绩的模型颁发奖牌,从而为比较不同模型提供了一个明确且具有竞争性的框架。研究团队首先依据金牌数量对模型进行排序,如果金牌数量相同,则按照整体性能分数来排序。它提供了一种直观简洁的方式来识别不同学术领域中的领先模型,使研究人员和开发者更容易理解不同模型的优势和劣势。研究团队还基于不同学科、不同模态、不同语言以及不同类型的逻辑和视觉推理能力进行基于准确性的细粒度评估。分析内容主要关注Claude-3.5-Sonnet和GPT-4o,同时也对Gemini-1.5-Pro的性能表现进行了部分讨论。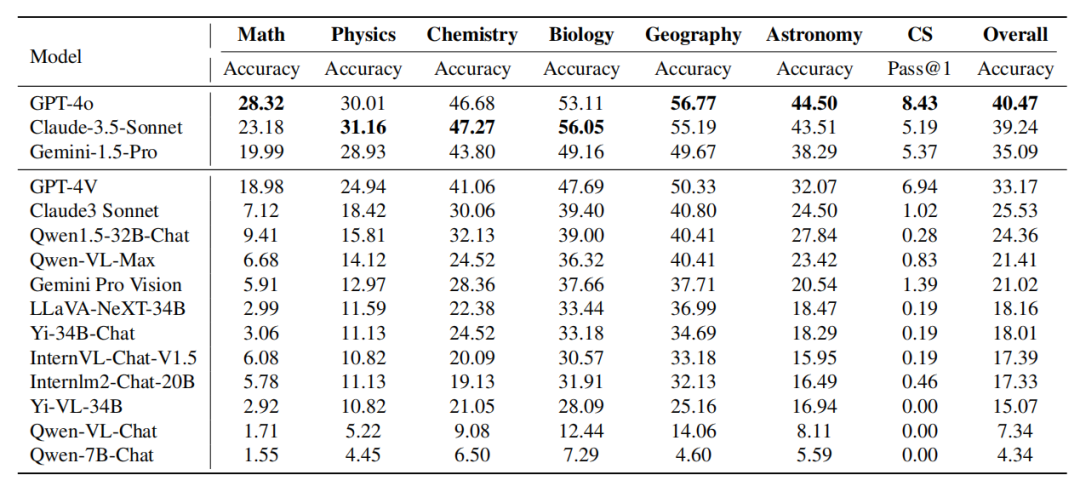
- 新发布的Claude-3.5-Sonnet性能强大,达到了几乎与GPT-4o
 相当的水平。两者的整体准确率差异仅约1%。
相当的水平。两者的整体准确率差异仅约1%。
- 新发布的Gemini-1.5-Pro也展现出了相当的实力,在大多数学科中的表现超过了GPT-4V(OpenAI当前第二强大的模型)。
- 值得注意的是,在撰写本报告时,这三个模型中最早的发布时间仅为一个月前,反映了这一领域的快速发展。
GPT-4o vs. Claude-3.5-Sonnet:尽管GPT-4o和Claude-3.5-Sonnet在整体上表现相似,但两个模型都展现了不同的学科优势。GPT-4o在传统的演绎和归纳推理任务上展现出更优秀的能力,特别是在数学和计算机科学方面。Claude-3.5-Sonnet在物理、化学和生物等学科表现出色,特别是在生物学上,它超过GPT-4o 3%。GPT-4V vs. Gemini-1.5-Pro:在Gemini-1.5-Pro与GPT-4V的比较中,可以观察到类似的现象。Gemini-1.5-Pro在物理、化学和生物学方面的表现显著优于GPT-4V。然而,在数学和计算机科学方面,Gemini-1.5-Pro优势不明显甚至不如GPT-4V。
- OpenAI的GPT系列在传统的数学推理和编程能力上表现突出。这表明GPT系列模型已经经过了严格训练以处理需要大量演绎推理和算法思维的任务。
- 相反,当涉及到需要将知识与推理结合的学科,如物理、化学和生物学时,其他模型如Claude-3.5-Sonnet和Gemini-1.5-Pro展现出了具有竞争性的表现。这体现了不同模型的专业领域以及潜在的训练重点,表明在推理密集型任务以及知识整合型任务可能存在的权衡。

码上飞
码上飞(CodeFlying) 是一款AI自动化开发平台,通过自然语言描述即可自动生成完整应用程序。
 430
查看详情
430
查看详情
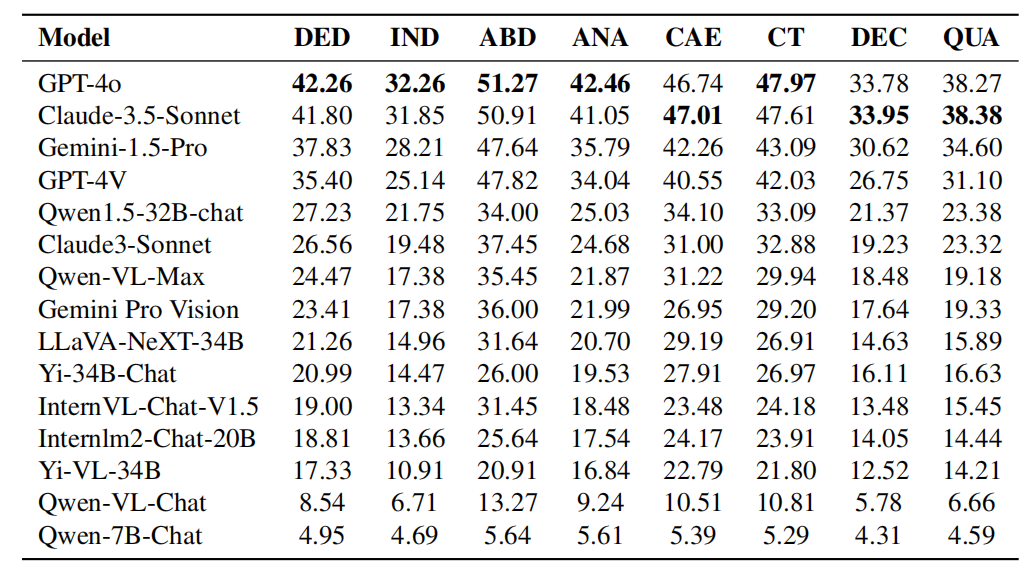
 Caption: 各模型在逻辑推理能力上的表现。逻辑推理能力包括:演绎推理(DED)、归纳推理(IND)、溯因推理(ABD)、类比推理(ANA)、因果推理(CAE)、批判性思维(CT)、分解推理(DEC)和定量推理(QUA)。GPT-4o 与 Claude-3.5-Sonnet 在逻辑推理能力上的比较:从表格的实验结果可以看出,GPT-4o在大多数的逻辑推理能力上优于Claude-3.5-Sonnet,例如演绎推理、归纳推理、溯因推理、类比推理和批判性思维方面。然而,Claude-3.5-Sonnet在因果推理、分解推理和定量推理上的表现超过了GPT-4o。整体而言,两个模型的表现相当,虽然GPT-4o在大多数类别上略有优势。
Caption: 各模型在逻辑推理能力上的表现。逻辑推理能力包括:演绎推理(DED)、归纳推理(IND)、溯因推理(ABD)、类比推理(ANA)、因果推理(CAE)、批判性思维(CT)、分解推理(DEC)和定量推理(QUA)。GPT-4o 与 Claude-3.5-Sonnet 在逻辑推理能力上的比较:从表格的实验结果可以看出,GPT-4o在大多数的逻辑推理能力上优于Claude-3.5-Sonnet,例如演绎推理、归纳推理、溯因推理、类比推理和批判性思维方面。然而,Claude-3.5-Sonnet在因果推理、分解推理和定量推理上的表现超过了GPT-4o。整体而言,两个模型的表现相当,虽然GPT-4o在大多数类别上略有优势。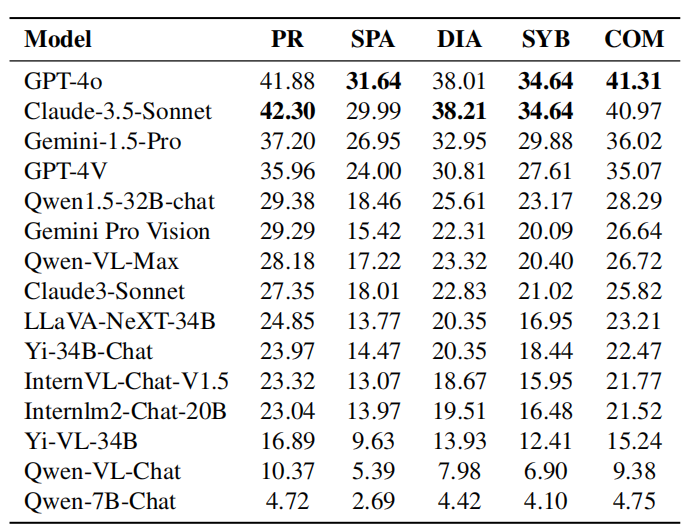
表: 各模型在视觉推理能力上的表现。视觉推理能力包括:模式识别(PR)、空间推理(SPA)、图表推理(DIA)、符号解释(SYB)和视觉比较(COM)。GPT-4o vs. Claude-3.5-Sonnet 在视觉推理能力上的表现:从表格的实验结果可以看出,Claude-3.5-Sonnet在模式识别和图表推理方面能力领先,展现了其在模式识别和解读图表方面的竞争力。两个模型在符号解释方面表现相当,表明它们在理解和处理符号信息方面具有相当的能力。然而,GPT-4o在空间推理和视觉比较方面优于Claude-3.5-Sonnet,展示了其在需要理解空间关系和比较视觉数据的任务上的优越性。
- 数学和计算机编程强调复杂演绎推理技巧和基于规则导出普适性结论,倾向于较少依赖预先存在的知识。相比之下,像化学和生物学这样的学科往往需要大量的知识库来基于已知的因果关系和现象信息进行推理。这表明,尽管数学和编程能力仍然是衡量模型推理能力的有效指标,其他学科更好地测试了模型在基于其内部知识进行推理和问题分析方面的能力。
- 不同学科的特点表明了定制化训练数据集的重要性。例如,要提高模型在知识密集型学科(如化学和生物学)中的表现,训练期间模型需要广泛接触特定领域的数据。相反,对于需要强大逻辑和演绎推理的学科,如数学和计算机科学,模型则能从专注于纯逻辑推理的训练中受益。
- 此外,推理能力和知识应用之间的区别表明了模型跨学科应用的潜力。例如,具有强大演绎推理能力的模型可以协助需要系统化思维解决问题的领域,如科学研究。而拥有丰富知识的模型在重度依赖现有信息的学科中非常宝贵,如医学和环境科学。理解这些细微差别有助于开发更专业和多功能的模型。
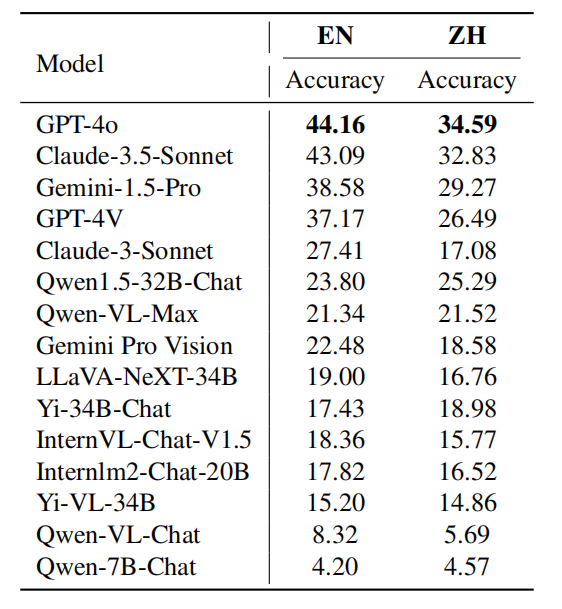 Caption: 各模型在不同语言问题的能力表现。
Caption: 各模型在不同语言问题的能力表现。
以上表格展示了模型在不同语言上的性能表现。研究团队发现大多数模型在英语上的准确度比中文要高,这种差距在排名靠前的模型中尤为显著。推测可能有以下几个原因:
- 尽管这些模型包含了大量中文训练数据并且具有跨语言泛化能力,但它们的训练数据主要以英语为主。
- 中文问题的难度比英文问题更具挑战性,尤其是在物理和化学等科目中,中国奥林匹克竞赛的问题更难。
- 这些模型在识别多模态图像中的字符方面能力不足,中文环境下这一问题更为严重。
然而,研究团队也发现一些中国厂商开发或基于支持中文的基模型进行微调的模型,在中文场景下的表现优于英文场景,例如Qwen1.5-32B-Chat、Qwen-VL-Max、Yi-34B-Chat和Qwen-7B-Chat等。其他模型如InternLM2-Chat-20B和Yi-VL-34B,虽然仍然在英语上表现更好,但与排名靠前的闭源模型相比,它们在英语和中文场景间的准确度差异要小得多。这表明,为中文数据乃至全球更多语言优化模型,仍然需要显著的关注。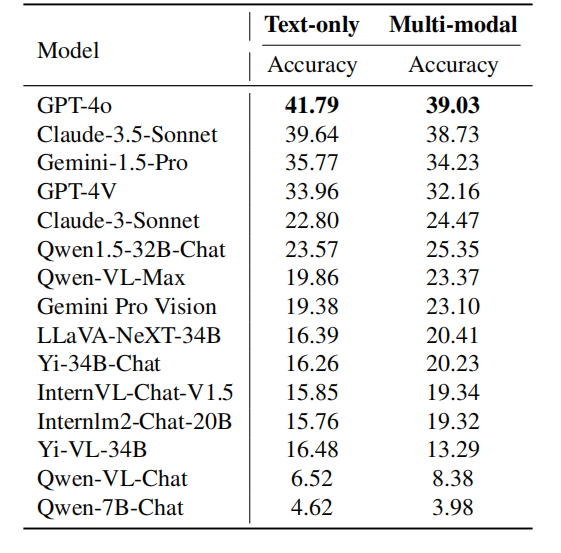
Caption: 各模型在不同模态问题的能力表现。以上表格展示了模型在不同模态上的性能表现。GPT-4o在纯文本和多模态任务中均优于Claude-3.5-Sonnet,并在纯文本上表现更突出。另一方面,Gemini-1.5-Pro在纯文本和多模态任务上表现均优于GPT-4V。这些观察表明,即使是目前可用的最强模型,在纯文本任务上也比多模态任务有更高的准确率。这说明模型在利用多模态信息解决复杂推理问题方面仍有相当大的改进空间。研究团队在本次评测中主要关注最新的模型:Claude-3.5-Sonnet 和 Gemini-1.5-Pro,并将它们与 OpenAI 的 GPT-4o 和 GPT-4V 进行比较。此外,研究团队还设计了一种用于大模型的新颖排名系统——OlympicArena Medal Table,用来清晰的比较不同的模型的能力。研究团队发现,GPT-4o 在数学和计算机科学等科目上表现突出,具有较强的复杂演绎推理能力和基于规则得出普遍结论的能力。另一方面,Claude-3.5-Sonnet 更擅长根据已有的因果关系和现象进行推理。另外,研究团队还观察到这些模型在英语语言问题上表现更好,并且在多模态能力方面有显著的改进空间。理解模型这些细微差别有助于开发更专业化的模型,以更好地满足不同学术和专业领域的多样化需求。随着四年一度的奥运盛事日益临近,我们不禁想象,如果人工智能也能参与其中,那将是一场怎样的智慧与技术的巅峰对决?不再仅仅是肢体的较量,AI的加入无疑将开启对智力极限的新探索, 也期待更多AI选手加入这场智力的奥运会。[1] Huang et al., OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI https://arxiv.org/abs/2406.12753v1以上就是奥林匹克竞赛里选最聪明的AI:Claude-3.5-Sonnet vs. GPT-4o?的详细内容,更多请关注其它相关文章!
# gair lab
# 工程
# 多模
# 奥林匹克
# type
# 硅基智能
# qwen
# claude
# gemini
# git
# 独立英文网站如何优化
# 文成网站建设推广
# 池州抖音seo价格
# 新站seo怎么玩
# 南坪seo优化如何
# 网页设计与建设网站
# 博野县网站seo
# 新乡网站全网推广代理商
# 渭南网站建设公司比较好
# 菏泽好的网站品牌推广店
# 模态
# 出了
# 这一
# 可以看出
# 细粒度
# 开源
# 是在
# 英语
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
如何用Transformer BEV克服自动驾驶的极端情况?
郭帆:AI发展日新月异,或是弯道超车好莱坞的最好机会
280万条多模态指令-响应对,八种语言通用,首个涵盖视频内容的指令数据集MIMIC-IT来了
微软AR/VR专利提出使用时间复用谐振驱动产生双极性电源
阿里达摩院发布免费开放100项AI专利许可的动机是什么?
上影节直击 | AI技术降低了短片拍摄门槛?金爵奖评委不赞同
能抓取玻璃碎片、水下透明物,清华提出通用型透明物体抓取框架,成功率极高
小米创始人雷军将揭示小米AI在年度演讲中的最新进展
泗洪:畅通城市“血管” ,管下机器人来帮忙
华为HarmonyOS 4将集|成人|工智能大型模型
马斯克回应人工智能拯救世界:人类已处于“半机器人”状态
北京公司实施AI技术,推行4.5天工作制,抵制996文化,提升员工工作幸福感
腾讯TRS之元学习与跨域推荐的工业实战
云米Smart 2E AI立式空调开启预售:新三级能效,到手价3899元
借助ChatGPT快速上手ElasticSearch dsl
阿里云全面支持Llama2训练部署,助力企业快速构建自有大型模型
标贝科技亮相国际顶会ICASSP2025 加速布局海外AI数据市场
AYANEO AIR 1S 掌机发布:R7 7840U,预订价 4699 元起
烟台大学学生首次在全国大学生无人机航拍竞赛中获奖
智能机器人正在彻底改变客户服务
周鸿祎参加中美青年科技创新峰会,分享人工智能创新机遇
找对了风口想不火都难,乐天派机器人,安卓机器人的最终形态?
实测 AI 建筑设计软件的自动生成效果图能力
AI浪潮席卷,时空壶为何能成为AI翻译时代的破局者
自研4D激光雷达L1 + GPT大语言模型 宇树Unitree Go2四足机器人有啥黑科技?
当孔子遇见AI|尼山的“数字”
无人机在电力巡检中的应用:全面解析高效巡检流程
企业软件行业更将被AI全面重构!Moka李国兴:未来优秀组织和个人将一定是善于使用AI生产力的
机器人加速!稀土永磁也被带火,持续性如何?
遵义市首次引入手术机器人,成功实施全膝关节置换术
Stability AI 推出文生图模型 SDXL0.9,GPU要求下探至消费级水平
普渡机器人与变形金刚品牌合作,特别活动爆火,商品售罄!
图像生成过程中遭「截胡」:稳定扩散的失败案例受四大因素影响
中国最强AI研究院的大模型为何迟到了
AI新风口?首个高质量「文生视频」模型Zeroscope引发开源大战:最低8G显存可跑
“踩油门,也要会踩刹车” 互联网企业高管谈人工智能发展
鉴智机器人发布基于地平线征程5的标准视觉感知产品
英伟达CEO宣称生成式AI已迎来“划时代时刻”
从GOXR到PartyOn,XRSPACE致力打造多元共赢的元宇宙世界
华为大模型登Nature正刊!审稿人:让人们重新审视预报模型的未来
华为4G5G通信物联网收费标准公布,多年研发成果,十年花费近万亿
跑不动的元宇宙,虚拟世界比现实更冷酷
AI与5G的强强联合:唤醒数字时代的无尽潜能
日媒:AI高效解析纳斯卡地画
首家承认ChatGPT影响其收入的公司Chegg选择拥抱AI ,裁减4%员工
“上海市民营企业人工智能赋能创新中心”揭牌成立
脑机接口产业联盟发布十大脑机接口关键技术
华为盘古AI模型实现秒级全球气象预报时间缩短
OpenAI 为开发者推出 GPT 聊天机器人 API 大更新,同时降低价格
650亿参数,8块GPU就能全参数微调:邱锡鹏团队把大模型门槛打下来了
2024-06-24


 相当的水平。两者的整体准确率差异仅约1%。
相当的水平。两者的整体准确率差异仅约1%。
