???本文的主要贡献可以归纳为以下几个核心方面:
系统性地评估并揭示了层冻结策略的有效机制: 明确了不同冻结策略(FR1、FR2、FR3)在性能与效率上的权衡关系。 从理论层面解释了其有效性源于对卷积神经网络层次化特征学习规律(早期层通用、后期层专用)的利用。 通过梯度分析,揭示了不同策略下模型的优化动态,表明适度的冻结(如FR2)能在特征保留和适应灵活性之间取得最佳平衡。 提出了基于数据集特性的、可操作的冻结策略选择指南: 明确指出最优冻结策略并非普适,而是直接由目标数据集的特征决定。 提供了具体的应用建议: 重度数据增强/大域偏移 -> 完全微调 极端类别不平衡/密集小目标 -> FR1(冻结4个块) 多类别/上下文丰富场景 -> FR2(冻结主干网络) 资源严重受限 -> FR1(冻结4个块) 阐明了模型规模(尺度)对冻结策略选择的关键影响: 发现了模型大小与冻结策略耐受性之间的重要关系,弥补了先前研究的空白。 指出小模型需要更宽松的冻结(如FR1)以保持性能,而大模型因参数容量大,可以承受更激进的冻结(如FR2)。 这为从业者根据可用计算资源选择模型和对应策略提供了明确框架。 引入了结合梯度监控与可视化的诊断方法论: 开发了一种将定量性能指标与定性模型行为解释相连接的分析方法。 这不仅验证了策略有效性,还能提前识别训练不稳定或失败模式(如不平衡数据集下的异常梯度)。 为深入理解迁移学习在目标检测中的内在机理提供了工具,并为未来开发自动化冻结优化工具奠定了基础。 实证了层冻结在效率上的显著优势: 通过实验量化了策略性冻结带来的巨大效率提升(FR1和FR2分别最高节省28%和44%的GPU内存,并大幅减少训练时间)。 挑战了“完全微调才是最佳”的传统迁移学习观念,证明选择性冻结能同时提升精度(通过防止过拟合)和效率。☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

博主简介

AI小怪兽 | 计算机视觉布道者 | 视觉检测领域创新者
深耕计算机视觉与深度学习领域,专注于视觉检测前沿技术的探索与突破。长期致力于YOLO系列算法的结构性创新、性能极限优化与工业级落地实践,旨在打通从学术研究到产业应用的最后一公里。
? 核心专长与技术创新
YOLO算法结构性创新:于CSDN平台原创发布《YOLOv13魔术师》、《YOLOv12魔术师》等全系列深度专栏。系统性提出并开源了多项原创自研模块,在模型轻量化设计、多维度注意力机制融合、特征金字塔重构等关键方向完成了一系列突破性实践,为行业提供了具备高参考价值的技术路径与完整解决方案。 技术生态建设与知识传播:独立运营 “计算机视觉大作战” 公众号(粉丝1.6万),成功构建高质量的技术交流社群。致力于将复杂算法转化为通俗易懂的解读与可复现的工程代码,显著降低了计算机视觉的技术入门门槛。? 行业影响力与商业实践
荣获PHP中文网年度影响力作者与创作之星奖项,内容质量与专业性获行业权威平台认证。 全网累计拥有 7万+ 垂直领域技术受众,专栏文章总阅读量突破百万,在目标检测领域形成了广泛的学术与工业影响力。 具备丰富的企业级项目交付经验,曾为工业视觉检测、智慧城市安防等多个关键领域提供定制化的算法模型与解决方案,驱动业务智能化升级。? 未来方向与使命
秉持 “让每一行代码都有温度” 的技术理念,未来将持续聚焦于实时检测、语义分割及工业缺陷检测的商业化闭环等核心方向。愿与业界同仁协同创新,共同推动技术边界,以坚实的技术能力赋能实体经济与行业变革。

论文:https://arxiv.org/pdf/2509.05490
摘要:You Only Look Once(YOLO)架构对于实时目标检测至关重要。然而,在资源受限的环境(如无人机)中部署它,需要高效的迁移学习。尽管层冻结是一种常用技术,但各种冻结配置对当代YOLOv8和YOLOv10架构的具体影响,特别是冻结深度、数据集特性和训练动态之间的相互作用,仍未得到探索。本研究通过详细分析层冻结策略来弥补这一空白。我们使用代表关键基础设施监控的四个具有挑战性的数据集,在YOLOv8和YOLOv10变体上系统地研究了多种冻结配置。我们的方法结合了梯度行为分析(L2范数)和可视化解释(Grad-CAM),以更深入地了解不同冻结策略下的训练动态。我们的结果表明,不存在通用的最优冻结策略,相反,最优策略取决于数据的特性。例如,冻结主干网络能有效保留通用特征,而较浅层的冻结则更适合处理极端的类别不平衡问题。与完全微调相比,这些配置将图形处理器(GPU)内存消耗降低了高达28%,并且在某些情况下,其平均精度(mAP@50)得分超过了完全微调的结果。梯度分析证实了这些发现,显示了适度冻结模型的独特收敛模式。最终,这项工作为选择冻结策略提供了实证结果和实践指南。它为资源有限场景下的目标检测任务提供了一种实用的、基于证据的平衡迁移学习方法。
以下是几种层冻结策略的伪代码实现:
import torchimport torch.nn as nnfrom torch.optim import Adamfrom torch.utils.data import DataLoaderclass YOLOFreezingTrainer: def __init__(self, model, train_loader, val_loader, config): self.model = model self.train_loader = train_loader self.val_loader = val_loader self.config = config # 定义优化器和损失函数 self.optimizer = Adam( filter(lambda p: p.requires_grad, model.parameters()), lr=config['learning_rate'] ) self.criterion = nn.MSELoss() # 简化为MSE损失,实际YOLO使用复合损失 def freeze_layers(self, layers_to_freeze): """冻结指定层""" for name, param in self.model.named_parameters(): for layer_name in layers_to_freeze: if layer_name in name: param.requires_grad = False break def unfreeze_layers(self, layers_to_unfreeze): """解冻指定层""" for name, param in self.model.named_parameters(): for layer_name in layers_to_unfreeze: if layer_name in layer_name: param.requires_grad = True break def train_epoch(self): """训练一个epoch""" self.model.train() total_loss = 0 for batch_idx, (images, targets) in enumerate(self.train_loader): self.optimizer.zero_grad() outputs = self.model(images) loss = self.criterion(outputs, targets) loss.backward() self.optimizer.step() total_loss += loss.item() return total_loss / len(self.train_loader)# 策略1: 渐进式解冻策略def progressive_unfreezing_strategy(model, train_loader, val_loader, config): """ 渐进式解冻策略伪代码 从浅层到深层逐步解冻网络层 """ trainer = YOLOFreezingTrainer(model, train_loader, val_loader, config) # YOLO模型层分组 backbone_layers = ['backbone.conv1', 'backbone.conv2', 'backbone.conv3'] neck_layers = ['neck.upsample', 'neck.conv'] head_layers = ['head.conv1', 'head.conv2'] # 阶段1: 仅训练检测头 print("阶段1: 仅训练检测头") trainer.freeze_layers(backbone_layers + neck_layers) trainer.unfreeze_layers(head_layers) for epoch in range(config['head_only_epochs']): loss = trainer.train_epoch() print(f"阶段1 Epoch {epoch}: 损失 = {loss:.4f}") # 阶段2: 解冻颈部网络 print("阶段2: 解冻颈部网络") trainer.unfreeze_layers(neck_layers) for epoch in range(config['neck_epochs']): loss = trainer.train_epoch() print(f"阶段2 Epoch {epoch}: 损失 = {loss:.4f}") # 阶段3: 解冻骨干网络浅层 print("阶段3: 解冻骨干网络浅层") trainer.unfreeze_layers(['backbone.conv1']) for epoch in range(config['shallow_backbone_epochs']): loss = trainer.train_epoch() print(f"阶段3 Epoch {epoch}: 损失 = {loss:.4f}") # 阶段4: 完全解冻所有层 print("阶段4: 完全解冻所有层") trainer.unfreeze_layers(backbone_layers) for epoch in range(config['full_train_epochs']): loss = trainer.train_epoch() print(f"阶段4 Epoch {epoch}: 损失 = {loss:.4f}")# 策略2: 基于验证损失的动态冻结策略def dynamic_freezing_based_on_val_loss(model, train_loader, val_loader, config): """ 基于验证损失的动态冻结策略 当验证损失停止改善时解冻更多层 """ trainer = YOLOFreezingTrainer(model, train_loader, val_loader, config) layers_groups = [ ['head.conv1', 'head.conv2'], # 组1: 检测头 ['neck.upsample', 'neck.conv'], # 组2: 颈部 ['backbone.conv1'], # 组3: 骨干浅层 ['backbone.conv2', 'backbone.conv3'] # 组4: 骨干深层 ] current_group = 0 best_val_loss = float('inf') patience_counter = 0 # 初始状态:仅解冻第一组 for i in range(1, len(layers_groups)): trainer.freeze_layers(layers_groups[i]) trainer.unfreeze_layers(layers_groups[0]) for epoch in range(config['max_epochs']): # 训练 train_loss = trainer.train_epoch() # 验证 val_loss = trainer.validate() print(f"Epoch {epoch}: 训练损失 = {train_loss:.4f}, 验证损失 = {val_loss:.4f}") # 早停和层解冻逻辑 if val_loss < best_val_loss: best_val_loss = val_loss patience_counter = 0 else: patience_counter += 1 # 如果验证损失停止改善,解冻下一组层 if patience_counter >= config['patience'] and current_group < len(layers_groups) - 1: current_group += 1 trainer.unfreeze_layers(layers_groups[current_group]) patience_counter = 0 print(f"解冻第 {current_group + 1} 组层") # 重置优化器学习率 trainer.adjust_learning_rate(config['lr_decay_factor'])# 策略3: 任务感知冻结策略def task_aware_freezing_strategy(model, train_loader, val_loader, config, task_type): """ 任务感知冻结策略 根据目标任务类型调整冻结策略 """ trainer = YOLOFreezingTrainer(model, train_loader, val_loader, config) if task_type == "domain_adaptation": # 领域适应:冻结骨干网络,微调检测头 trainer.freeze_layers(['backbone', 'neck']) trainer.unfreeze_layers(['head']) elif task_type == "fine_grained_detection": # 细粒度检测:冻结浅层特征,微调深层特征 trainer.freeze_layers(['backbone.conv1', 'backbone.conv2']) trainer.unfreeze_layers(['backbone.conv3', 'neck', 'head']) elif task_type == "novel_class_detection": # 新类别检测:完全解冻检测头,部分冻结骨干 trainer.freeze_layers(['backbone.conv1']) trainer.unfreeze_layers(['backbone.conv2', 'backbone.conv3', 'neck', 'head']) # 训练循环 for epoch in range(config['epochs']): loss = trainer.train_epoch() print(f"任务感知训练 Epoch {epoch}: 损失 = {loss:.4f}")# 策略4: 层重要性评估冻结策略def layer_importance_freezing_strategy(model, train_loader, val_loader, config): """ 基于层重要性的冻结策略 首先评估各层重要性,然后选择性冻结 """ trainer = YOLOFreezingTrainer(model, train_loader, val_loader, config) # 步骤1: 评估层重要性 layer_importance_scores = evaluate_layer_importance(model, val_loader) # 步骤2: 根据重要性得分决定冻结策略 important_layers = [] unimportant_layers = [] threshold = config['importance_threshold'] for layer_name, score in layer_importance_scores.items(): if score > threshold: important_layers.append(layer_name) else: unimportant_layers.append(layer_name) # 冻结不重要的层 trainer.freeze_layers(unimportant_layers) trainer.unfreeze_layers(important_layers) print(f"重要层: {important_layers}") print(f"冻结层: {unimportant_layers}") # 训练循环 for epoch in range(config['epochs']): loss = trainer.train_epoch() print(f"重要性感知训练 Epoch {epoch}: 损失 = {loss:.4f}")def evaluate_layer_importance(model, val_loader): """ 评估各层重要性的辅助函数 通过计算梯度或性能影响来评估 """ importance_scores = {} model.eval() # 简化的重要性评估方法 # 实际实现可能更复杂,涉及梯度计算或消融研究 for name, module in model.named_modules(): if isinstance(module, nn.Conv2d): # 使用权重范数作为重要性代理 importance = torch.norm(module.weight).item() importance_scores[name] = importance # 归一化重要性得分 max_importance = max(importance_scores.values()) for name in importance_scores: importance_scores[name] /= max_importance return importance_scores# 主训练流程def main(): # 配置参数 config = { 'learning_rate': 0.001, 'head_only_epochs': 10, 'neck_epochs': 10, 'shallow_backbone_epochs': 10, 'full_train_epochs': 20, 'patience': 5, 'lr_decay_factor': 0.1, 'importance_threshold': 0.5, 'max_epochs': 50, 'epochs': 30 } # 加载模型和数据 model = YOLOModel() # 假设的YOLO模型 train_loader = DataLoader(...) val_loader = DataLoader(...) # 选择冻结策略 strategy = "progressive" # 可选择: progressive, dynamic, task_aware, importance_based if strategy == "progressive": progressive_unfreezing_strategy(model, train_loader, val_loader, config) elif strategy == "dynamic": dynamic_freezing_based_on_val_loss(model, train_loader, val_loader, config) elif strategy == "task_aware": task_aware_freezing_strategy(model, train_loader, val_loader, config, "domain_adaptation") elif strategy == "importance_based": layer_importance_freezing_strategy(model, train_loader, val_loader, config)if __name__ == "__main__": main()这个伪代码实现了论文中提到的几种关键层冻结策略:
渐进式解冻策略:从检测头开始,逐步解冻更深层的网络基于验证损失的动态冻结:根据验证集性能动态决定何时解冻更多层任务感知冻结策略:根据具体任务类型调整冻结模式基于层重要性的冻结:评估各层重要性后选择性冻结这些策略旨在平衡训练效率和模型性能,避免灾难性遗忘同时加速收敛。
You Only Look Once (YOLO) 架构通过单次前向传播即可完成检测、定位和分类,彻底改变了实时目标检测领域,使其特别适用于监控、自动驾驶和基于无人机的监测等时间敏感型应用 [1-4]。然而,平衡高检测精度与计算需求仍然是一个挑战,尤其是在边缘设备和嵌入式系统等资源受限的环境中部署时。
通过层冻结进行迁移学习已成为一种应对这些限制的有效策略。它能使预训练模型适应新任务而无需完全重新训练,从而在降低计算开销的同时保留已学到的知识 [5,6]。尽管现有研究表明,在将基于大规模数据集(如 COCO [7])预训练的模型适配到特定领域数据集 [8,9] 时,迁移学习可以提升模型性能,但对于现代 YOLO 架构中层冻结策略的系统性分析仍存在显著空白。
具体而言,目前尚缺乏关于不同层冻结配置如何影响 YOLOv8 和 YOLOv10 架构中关键性能指标(mAP@50, mAP@50:95)、训练效率和资源利用率之间权衡的全面研究。这种理解对于在实际应用中优化 YOLO 模型的从业者至关重要,因为在那些场景中准确性和效率都至关重要 [10,11]。
本研究系统地调查了各种层冻结策略对应用于关键基础设施监测任务的现代 YOLO 架构(YOLOv8 [12] 和 YOLOv10 [13])的影响。我们在四个具有挑战性的数据集上,针对不同的冻结配置与传统微调方法进行了评估,分析了精度指标、计算效率和训练动态。
本文的其余部分组织如下:第 2 节回顾相关工作,第 3 节描述 YOLO 架构,第 4 节详细介绍数据集,第 5 节概述实验方法,第 6 节展示结果,第 7 节讨论研究发现与局限性,第 8 节总结全文。
深度神经网络中的层冻结概念已成为优化迁移学习的关键技术,尤其是在计算效率至关重要的场景中。迁移学习利用在大型数据集上预训练的模型,通过微调(调整所有参数)或选择性冻结(固定某些层同时让其他层自适应)[5],来适应新的、通常规模较小的任务特定数据集。层冻结不仅能加速收敛,还能减少分布式训练中的内存消耗和通信成本,并有助于在目标数据集有限时减轻过拟合 [10,11,14]。
已有多种优化层冻结的策略被提出。文献 [10] 的工作引入了 AutoFreeze,这是一种根据训练进度动态决定冻结哪些层的方法,并在自然语言处理(NLP)和计算机视觉(CV)任务中证明了其有效性。类似地,先前的工作探索了 Transformer 架构中的层冻结,显示出在性能权衡极小的情况下训练效率的显著提升 [11,14,15]。将冻结与剪枝相结合的混合方法也显示出潜力,尤其是在资源受限的环境中 [16,17]。
然而,在目标检测领域,尽管层冻结在优化像 YOLO 这样计算需求高的架构方面具有潜力,但对其的系统性分析仍然有限。文献 [8] 的早期工作研究了在 COCO 上预训练并在较小数据集上微调的 YOLOv5 模型中冻结主干网络层,发现冻结的主干网络比完全微调的模型获得了更高的 mAP@50 分数。文献 [9] 的研究将这一分析扩展到车辆检测,证实了冻结主干网络的优越性能,特别是对于类别不平衡的情况。文献 [18] 的最新工作将这一分析扩展到基于无人机的目标检测,表明主干网络冻结结合架构修改可以在减少计算开销的同时提高性能。然而,文献 [19] 的研究指出了在细粒度检测任务中的局限性,即冻结模型尽管推理速度更快,但会遗漏细微的细节。
现代 YOLO 架构的出现催生了更复杂的迁移学习方法。文献 [20] 的工作在 YOLOv8 上系统评估了三种迁移学习方法(冻结层、域自适应和零样本学习)用于建筑图纸检测,发现选择性层冻结(尤其是颈部和头部之间的中间层)实现了最高的 mAP。最近,文献 [21] 的研究表明,在 YOLOv8n 上进行更深度的微调在细粒度任务上能带来显著的性能提升,同时在原始 COCO 基准测试上保持可忽略不计的性能下降。
表 1 总结了近期研究的关键发现。尽管取得了进展,但现代 YOLO 架构(YOLOv8, YOLOv10)仍缺乏在真实世界场景下的全面评估,现有研究主要集中于特定应用或单一冻结策略,缺乏对梯度动态、计算权衡或跨不同数据集特性的性能的系统性评估。本研究通过对关键基础设施监测的冻结策略进行详细分析,平衡准确性与效率,填补了这一空白。
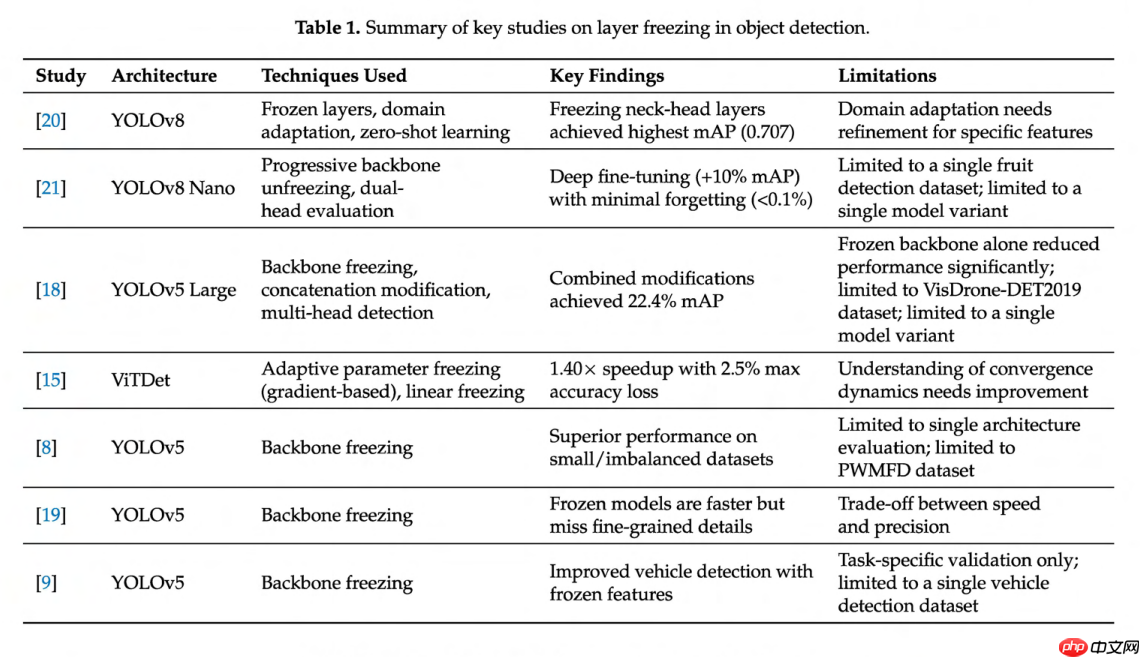
在我们的研究中,我们选择使用 YOLOv8 [12] 和 YOLOv10 [13] 架构,因为它们相对于前代版本取得了显著的进展和优化,并具备最先进的性能和效率。这些架构的开发旨在提升目标检测任务的性能、准确性和效率。
YOLOv8 主要是在 YOLOv5 架构基础上进行的一系列改进和增强,代表了 YOLO 系列的重大演进。它融合了多项创新特性,提升了其在各种目标识别任务中的性能。虽然 YOLOv8 的许多变更涉及模型缩放和架构优化,旨在解决先前版本中的一些局限性,但本研究将深入探讨与网络层冻结最相关的那些变更:
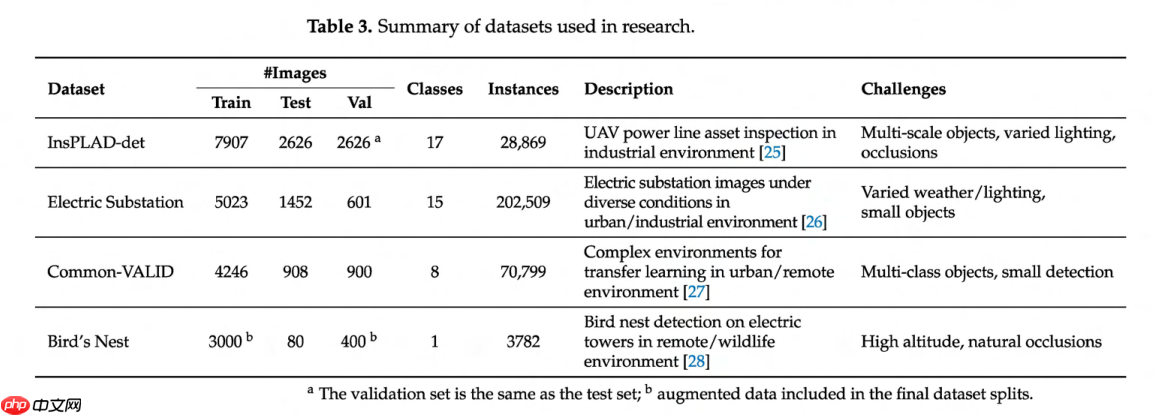
增强的特征金字塔网络(FPN):YOLOv8 算法采用了 FPN 的先进版本,称为空间金字塔池化-快速版(SPPF),这显著增强了其识别不同尺度目标的能力。这一增强对于检测图像中的小目标尤为关键,这是许多实际应用中的常见挑战。 改进的主干网络:YOLOv8 的主干网络经过显著优化,以实现更好的特征提取。它使用了与 YOLOv5 类似的主干网络,但对 CSPLayer 进行了修改,现称为 C2f 模块(具有两次卷积的跨阶段部分瓶颈层)。C2f 模块将高层次特征与上下文信息相结合,从而提高了检测精度。此外,主干网络采用了 CSPNet(跨阶段部分网络)[22],这有助于在保持高精度的同时降低计算成本。该主干网络具体是 CSPDarknet53 [23] 特征提取器,以其高效的特征提取能力而闻名。这些对 FPN 和主干网络的增强突显了它们在整体 YOLOv8 架构中的关键作用。该架构包含三个主要组成部分:主干网络、颈部网络和头部网络。负责特征提取的主干网络通常在迁移学习过程中是需要保持的最重要部分。在 YOLOv8 中,主干网络包含模型的前 9 个块 [24],每个块包含数量不等的层,其中 SPPF 块是颈部网络的一部分。通过专注于这一关键组件,我们旨在确保基本特征提取能力得以保留,这对迁移学习的成功至关重要。图 1 概述了与我们实验相关的 YOLOv8 架构的关键组件,并突出显 示了我们在应用冻结技术时将操作的块。
示了我们在应用冻结技术时将操作的块。
对 YOLOv8 配置的更深入分析表明,块 0-3 专用于纯特征提取层,它们被策略性地放置在任何特征拼接过程之前。具体来说,这些初始块包括:(i)块 0 包含初始卷积和 P1/2 下采样,(ii)块 1 包含 P2/4 下采样卷积,(iii)块 2 包含用于特征处理的 C2f 模块,以及(iv)块 3 实现 P3/8 下采样。首次特征拼接发生在头部的块 14 处,其中来自块 4(P3/8 级别)的主干特征与通过拼接方式上采样的特征进行合并。这种架构设计形成了一个自然的边界,其中块 0-3 捕获基础的、领域无关的视觉表示(边缘、纹理、基本几何图案),而后续的块则参与任务特定的特征融合操作。主干网络包含块 0-8,块 9 处的 SPPF 模块标志着向颈部组件的过渡。
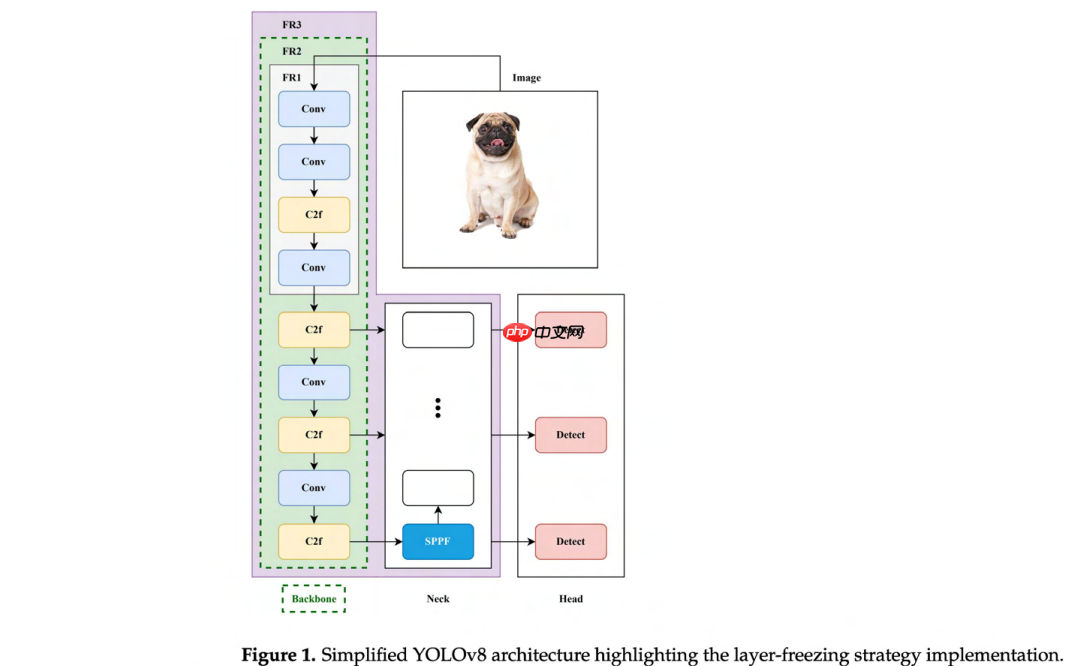
图1. 简化的YOLOv8架构,突出了层冻结策略的实施。 该模型由主干网络(特征提取)、颈部网络(特征融合)和头部网络(检测)组件构成。高亮区域FR1、FR2和FR3指明了渐进式冻结方法:FR1冻结前4个块(约占参数的1%),FR2冻结包含9个块的完整主干网络(约占参数的35-44%),FR3冻结22个块,包括大部分颈部网络(约占参数的72-87%)。此架构概览展示了不同的冻结策略如何保留不同级别的预训练知识,同时允许进行有针对性的适应。
截至 2025 年 8 月,YOLOv10 成为 YOLO 系列的最新演进,代表了当前实时、端到端目标检测的最高水平 [13]。它相比前代版本,特别是 YOLOv8,引入了若干重大改进。结合我们研究层冻结对训练效率和精度指标影响的主要目标,YOLOv10 纳入的主要增强如下:
增强的模型架构:YOLOv10 引入了若干架构创新,例如轻量级分类头、空间-通道解耦下采样和秩引导块设计。这些变更旨在减少计算冗余、提高参数利用率并增强整体模型效率。此外,YOLOv10 集成了一个部分自注意力模块以提升模型能力,从而以最小的计算开销实现更好的精度。 Transformer 块集成:YOLOv10 集成了 Transformer 块,特别是多头自注意力(MHSA)以及后续的前馈网络(FFN)。这种集成有助于更有效地捕获全局上下文信息,从而提高检测精度。通过仅将部分自注意力(PSA)模块放置在最后阶段之后,模型在增强全局表示学习能力的同时,最小化了计算复杂度。YOLOv10 保持了 YOLOv8 确立的基本架构原则,同时融入了先进的注意力机制。初始的四块边界(块 0-3)保持一致,保留了相同的纯特征提取模式:初始卷积与 P1/2 和 P2/4 下采样、C2f 特征处理以及 P3/8 下采样。关键的是,YOLOv10 的架构增强,包括部分自注意力(PSA)模块以及带有多头自注意力(MHSA)和前馈网络(FFN)的 Transformer 块,被策略性地安排在这个初始特征提取阶段之后。PSA 模块主要集成在主干网络和颈部网络的后期阶段,使得块 0-3 中的基础卷积特征提取保持不变。秩引导块设计在优化参数利用率的同时,保持了对于迁移学习至关重要的架构边界。这种设计确保了领域无关的特征提取能力在初始块中得到保留,而增强的注意力机制在后续处理阶段提供了任务特定的适应能力。
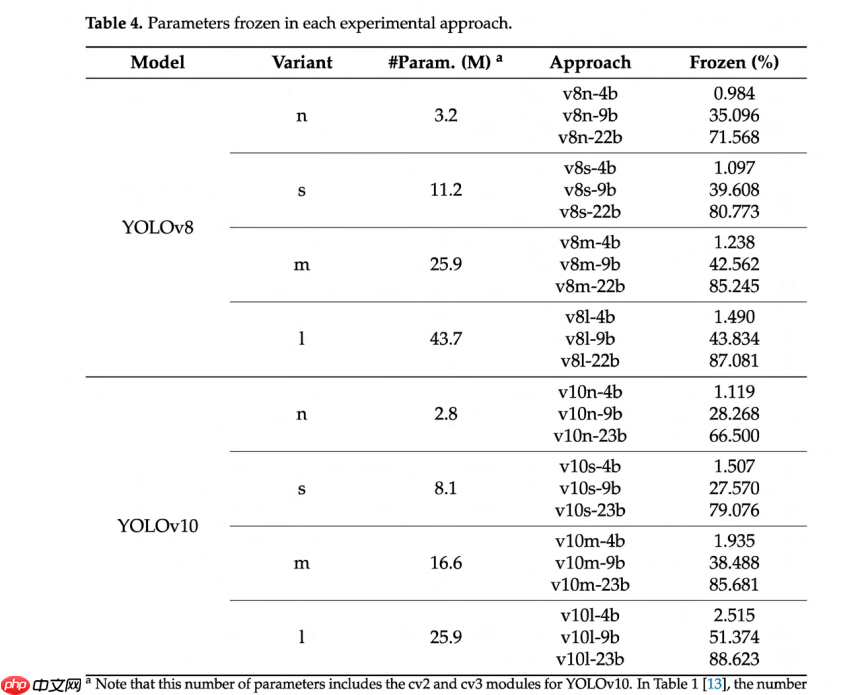
这些进展突显了 YOLOv10 复杂的架构,它由主干网络、颈部网络和头部网络组成。YOLOv10 的主干网络采用秩引导块风格设计,旨在最大化特征提取能力,同时保持计算效率。具体来说,YOLOv10 的主干网络包含 9 个块,经过优化以提取对于高精度检测任务至关重要的深度和丰富特征。此外,SPPF 和 PSA 块(假定遵循 [24] 中提出的风格,属于颈部网络的一部分)也对整体架构有所贡献。图 2 展示了与我们实验相关的 YOLOv10 架构主要组件的简化视图,重点突出了我们在冻结过程中将调整的块,以便更清晰地理解。
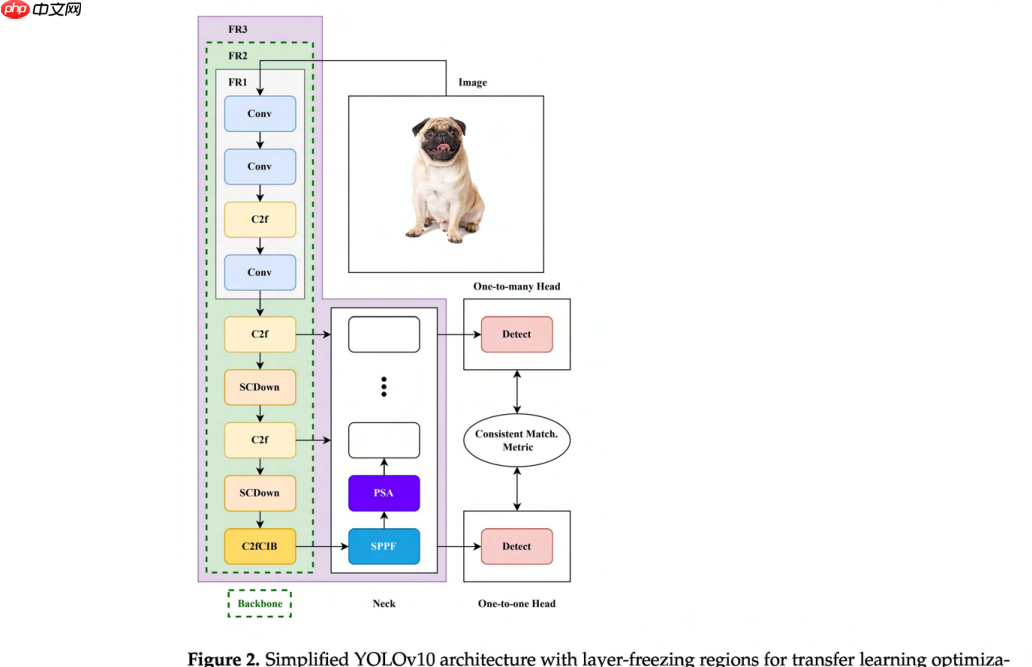
图2. 简化的YOLOv10架构,显示了用于迁移学习优化的层冻结区域。 该增强架构融合了Transformer模块和注意力机制,同时保持了三分支结构。冻结区域FR1、FR2和FR3代表了逐级递增的参数保留策略:FR1针对初始特征提取层(约占参数的1-2%),FR2涵盖包括注意力模块在内的完整主干网络(约占参数的28-51%),FR3扩展至23个块,覆盖了大部分处理阶段(约占参数的67-89%)。该架构展示了现代注意力机制在冻结框架内的集成。
本节介绍了所使用的应用和数据集,重点聚焦于关键基础设施检测与监控中的目标检测任务。无人机在监测偏远或危险环境(如电力线和工业现场)方面发挥着关键作用。在这些场景中,实时目标检测既能提升安全性,也能提高运营效率。
为严格评估模型,我们选取了四个能反映这些真实世界挑战的数据集,它们提供了多样化的环境,以全面测试模型的适应性和精确度。我们同时纳入了真实世界数据集和合成数据集,以反映当前利用合成数据训练机器学习模型的趋势,因为合成数据集能够创建受控环境,模拟罕见或危险状况。这种全面的覆盖确保了我们的层冻结分析能够跨越不同的操作场景和技术要求,具有鲁棒性。这些数据集代表了经过精心挑选的真实世界数据与合成数据的组合,针对基础设施监控领域的不同方面:
领域多样性:覆盖范围从详细的变电站设备检测到输电线路资产监控,以及通用的空中监控场景。 技术挑战:每个数据集都呈现出独特的计算和检测挑战,从多尺度目标检测到极端的类别不平衡。 环境多变性:真实世界数据集包含了变化的天气条件、光照场景和季节变化。 数据采集方法:涵盖了多种无人机平台、相机系统和成像视角。InsPLAD 数据集 [25] 专为电力线路资产检测设计,源自真实世界检测中捕获的无人机图像。该数据集通过全面覆盖资产检测和缺陷分类任务,填补了文献中的一个关键空白。我们的工作专注于该数据集的 InsPLAD-det 部分,用于目标检测。
InsPLAD-det:这部分数据集包含 17 个不同的目标类别,在 10,607 张高分辨率 RGB 图像(1920 x 1080 像素)上共有 28,933 个标注。这些图像使用搭载 Zenmuse z30 相机(中国深圳大疆)的 DJI Matrice 210 V2 无人机采集。图像于 2025 年 10 月至 12 月期间,系统性地从巴西 500 kV 高压网络的 226 个输电塔捕获。标准化的采集协议确保了图像质量的一致性,关键组件居中并对准特定角度以提升检测效能。采集过程包含了多种环境条件、飞行高度和视角,以模拟真实世界操作场景。
目标和标注的分布涵盖了广泛的输电线路资产,包括绝缘子、导线、塔身及相关硬件组件。这些资产在实例数量及其空间属性方面差异很大。例如,图像最少的类别是"聚合物绝缘子塔挂板",有 57 张图像和 57 个标注;而图像最多的类别是"聚合物绝缘子",有 3173 张图像和 3244 个标注。
数据集按 80% 的图像用于训练、20% 用于测试和验证进行划分。从原始来源获取数据集并考虑部分标注图像缺失后,我们共收集到 10,533 张图像和 28,869 个标注。经过数据划分后,数据集包含 7907 张训练图像和 2626 张测试/验证图像。
变电站数据集 [26] 为变电站设备检测提供了一个标注详尽的资源,满足了电力配送基础设施监控自动化的需求。它包含 7539 张变电站图像,具有 213,566 个标注目标,使用各种相机采集,包括手机、全景航空相机、立体 FUR 相机和自动导引车。
这些图像在两年时间内从巴西的一个配电变电站收集,代表了不同时间、天气和季节条件。数据集根据采集时间和所用设备组织到多个目录中。它包括 4030 张在上午时段(8:00 至 12:00)手动采集的图像。有 2270 张图像是在白天(上午 8:00 至 10:00 和下午 13:00 至 17:00)使用 AGV 采集的。此外,数据集中还包含 899 张在夜间(20:00 至 21:00)使用 AGV 并借助人工照明采集的图像,以及 340 张在夜间(20:00 至 21:00)使用 AGV 且无人工光源条件下拍摄的图像。
它包含 15 个目标类别,存在严重的类别不平衡。在移除一小部分未标注图像后,图像最少的类别是"敞开式刀闸开关",有 591 张图像和 1076 个标注;而图像最多的类别是"瓷针式绝缘子",有 6457 张图像和 107,497 个标注。这种极端的不平衡反映了真实世界的操作条件,其中某些设备类型明显更为常见。
有关变电站数据集中类别图像与实例分布的更多详情,请参阅附录 B.1。由于变电站数据集最初并未划分训练集、测试集和验证集,我们采用了 70-20-10 的比例进行划分,确保所有子集中类别比例保持一致。这最终得到总共 7076 张图像和 202,509 个目标标注。划分后,数据集包含 5023 张训练图像、1452 张测试图像和 601 张验证图像。
Common-VALID 数据集源自全面的 VALID 数据集 [27],体现了合成数据生成在基础设施监控研究中的应用。该合成数据集解决了与真实世界数据收集相关的局限性和成本问题,同时为系统评估提供了受控的环境条件。
母数据集 VALID 包含 6690 张高分辨率图像,全部标注了全景分割(涵盖 30 个类别)、用于目标检测的传统边界框和定向边界框,以及双目深度图。图像在六个虚拟场景和五种环境条件(晴朗、日落、夜晚、雪、雾)下于多个高度(20 米、50 米、100 米)捕获。它包括 30 个类别,其中 17 个用于目标检测,分为"物体"和"背景"类型。"物体"类别包括如树木、建筑物和车辆等对象,而"背景"类别包括土地、水和冰等。这种分层分类有助于详细准确的目标检测和分割任务。
我们通过选择对常见迁移学习场景最具代表性的类别来整理 VALID 数据集。这种精简的数据集使我们能够评估在不同 YOLO 架构中冻结层的影响,并将其与从头开始训练或微调模型进行比较。选定的八个类别(小型车辆、大型车辆、动物、人、船舶、飞机、桥梁、港口)代表了空中监视和基础设施监控应用中遇到的常见目标。该数据集呈现出显著的目标尺寸变化,25% 的实例小于 10 像素,创造了超小目标检测的挑战。这种分布反映了真实世界的航空成像场景,其中目标根据高度和相机设置以不同尺度出现。
创建过程包括:过滤 VALID 数据集仅保留与我们实验最相关的类别,确保得到一个精简的数据集用于评估冻结层的影响;调整边界框标签以确保准确性和相关性;将数据集划分为训练集、测试集和验证集子集。训练集、测试集和验证集按照 70-15-15 的比例创建,确保每个子集中类别比例得以保持。划分后,Common-VALID 数据集包含 6054 张图像和 70,799 个标注,分布为 4246 张训练图像、908 张测试图像和 900 张验证图像。图像最少的类别是"飞机",包含 268 张图像和 429 个标注;而图像最多的类别是"小型车辆",包含 4724 张图像和 40,230 个标注。有关 Common-VALID 数据集中类别分布和标注的进一步细节,请参阅附录 B.2。
鸟巢数据集 [28] 专用于检测输电塔上的鸟巢,基于通过无人机拍摄的航空照片,因此提出了一个专业化的单类别检测挑战。
原始数据集包含 800 张航空图像,我们可访问的子集包含 401 张通过无人机平台捕获的图像。该数据集为航空场景下的单类别检测带来了独特的挑战。首先,高空视角引入了尺度和透视失真,使目标定位复杂化。其次,由植被、塔架结构和环境元素造成的自然遮挡产生了复杂的视觉障碍。最后,巢穴材料与其周围环境(如自然背景和结构元素)之间的纹理相似性使得视觉区分变得困难。
为了使其适用于我们的实验,我们将数据集按 70-20-10 的比例划分为训练集、测试集和验证集,得到 281 张训练图像、80 张测试图像和 41 张验证图像。为了缓解训练数据集大小的限制,我们采用了一系列数据增强技术,遵循 [28] 中描述的实现。这些技术包括水平和垂直翻转、旋转、随机裁剪、高斯模糊以及添加高斯噪声。这些增强对于模拟不同的真实世界条件和增加训练数据的多样性至关重要。通过这些技术,我们将训练集扩展到总共 3359 张图像。此外,我们通过从训练子集中添加 359 张增强图像来调整验证集,最终分布为 3000 张训练图像、400 张验证图像和 80 张测试图像。几乎所有图像每张仅包含一个实例,总共有 3782 个标注。
本文中使用的数据集是用于训练和评估目标检测模型的综合性资源,提出了诸如类别不平衡和多样化条件等挑战。它们支持计算机视觉和深度学习算法在各种领域自动化检测和维护方面的发展。合成数据的纳入,这在近期研究 [29-31] 中也有使用,提供了潜在优势,例如增加数据多样性以及无需真实世界数据收集即可模拟罕见或危险条件的能力。这些数据集为我们在 YOLO 架构中层冻结的研究提供了一致的基准,并且对于旨在推进自动化检测技术的研究人员和工程师来说是宝贵的资产。
表 2 总结了每个数据集如何应对基础设施监控中的特定挑战,展示了我们实验框架的全面性。图 3 展示了实验数据集所用训练集中的示例图像。表 3 提供了所使用的四个数据集的详细概览,包括训练集、测试集和验证集中的图像数量、目标类别和实例的数量,以及关键描述、环境和挑战,这些信息突显了目标检测模型在真实世界无人机应用中所面临的复杂性。
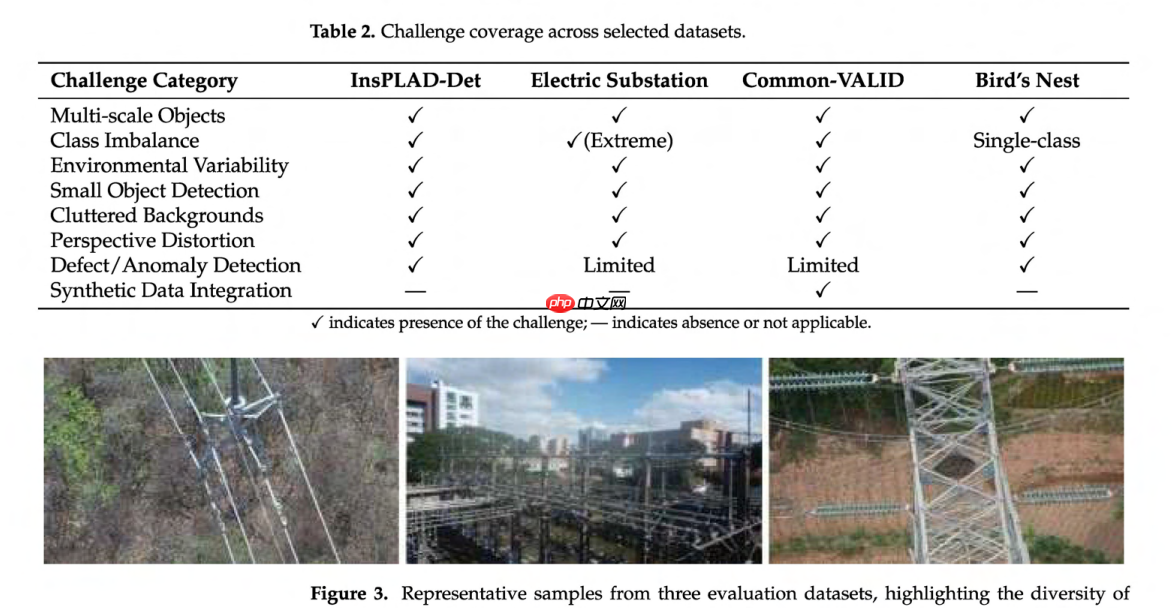
图3. 来自三个评估数据集的代表性样本,突出了真实世界目标检测挑战的多样性。
(左) InsPLAD-det数据集:展示了包含不同尺度和复杂背景的电力线路基础设施组件。 (中) 变电站数据集:呈现了密集排列的物体和具有挑战性的照明条件。 (右) 鸟巢数据集:捕捉了电力塔上巢址的航空视角图像。这些数据集共同代表了在关键基础设施监控中部署资源高效型YOLO模型的目标场景。
本节详细介绍了用于系统评估迁移学习策略(特别是层冻结)对 YOLOv8 和 YOLOv10 模型性能和计算效率影响的实验方法。我们的总体策略包含两个主要部分。我们实施并比较了几种层冻结配置,即在目标数据集上重新训练期间,冻结预训练模型主干网络的特定块。这些配置分别对应于冻结前 4 个块(FR1)、9 个块(FR2,涵盖整个主干网络)或 22/23 个块(FR3),并以标准微调和从头开始训练作为基准进行对比。所有实验的评估均依赖于关键性能指标(mAP@50, mAP@50:95)和资源指标(GPU 使用量、训练时间),如下所述。
 Procys
Procys
AI驱动的发票数据处理
 102
查看详情
102
查看详情

在我们的实验中,层冻结方法将基于所研究的 YOLO 模型的架构细节(见图 1 和图 2)以及冻结参数的百分比。需要注意的是,对于 YOLOv10,此参数数量包含了 cv2 和 cv3 模块,因为引入 YOLOv10 的原始论文在其表 1 [13] 中未包含这些参数,原因是它们在推理阶段不需要。
关于参数,架构头部中可训练参数的数量可能会有所不同,这取决于第 4 节讨论的数据集中目标类别的不同数量。我们将给出每种方法、模型和数据集相对于在 COCO [7] 数据集(包含 80 个目标类别)上预训练的模型架构的冻结参数百分比,并且对于 YOLOv10 包含 cv2 和 cv3 模块。然而,具有 80 个目标类别的模型与仅有一个类别的模型之间的参数数量差异小于 0.3%。表 4 显示了每种方法和模型的冻结参数百分比。"v8n-4b"、"v8n-9b" 和 "v8n-22b" 代表 YOLOv8 模型 "n"(纳米)变体的不同方法,其中 "4b"、"9b" 和 "22b" 表示冻结的块数。类似地,"v8s-4b"、"v8s-9b" 和 "v8s-22b" 指的是 YOLOv8 的 "s"(小)变体,分别冻结了 4、9 和 22 个块,对于 "m"(中)和 "l"(大)变体也遵循相同的结构。YOLOv10 模型也遵循相同的结构。这些方法涉及冻结图 1 和图 2 中标有 FR1、FR2 和 FR3 的区域内的层。具体来说,FR1 区域对应冻结 4 个块,FR2 区域对应冻结 9 个块,FR3 区域分别对应冻结 YOLOv8 的 22 个块和 YOLOv10 的 23 个块。关于选择冻结哪些块的更多信息,请参阅附录 A。
我们选择的冻结配置(FR1: 4 个块;FR2: 9 个块;FR3: 22/23 个块)基于现代 YOLO 设计的基本架构边界。块 0-3(FR1)构成了在任何拼接操作之前的纯特征提取层,捕获领域无关的视觉表示(边缘、纹理、几何图案),在检测任务间具有高可迁移性。9 块边界(FR2)涵盖了完整的主干特征提取流水线,保留了所有基本的视觉表示,同时允许颈部和头部组件进行任务特定的适应。扩展的 22/23 块配置(FR3)包括了大部分特征融合操作,保持了特征提取和集成能力,同时仅允许在最终检测层进行微调。这种分层方法与既定的迁移学习原则一致:早期层包含适合保留的通用特征,中间层处理需要适度适应的特征集成,而最终层执行需要完全微调的特定任务检测 [5]。
通过选择性地冻结 YOLOv8 和 YOLOv10 模型中的主干网络块和层,我们旨在保留从原始数据集中学习到的通用特征提取能力,同时允许上层适应新任务的特定特征。这种方法将帮助我们确定要冻结的最佳层和块。
在我们的实验中,YOLOv8 和 YOLOv10 模型使用随机梯度下降(SGD)优化器训练 1000 个周期,并采用早停机制,耐心值设为 30 个周期。批量大小设置为 16,数据集图像缓存在 RAM 中,通过最小化磁盘 I/O 操作来提高训练速度,但这是以增加内存使用为代价的。SGD 优化器的动量和权重衰减分别配置为 0.937 和 5 x 10⁻⁴。初始学习率设置为 1 x 10⁻²,在训练过程中线性衰减至 1 x 10⁻⁴。所有数据集图像都经过标准化预处理,以确保实验间的一致性,同时保持数据分布的完整性。图像被调整为 640 x 640 像素,并使用 ImageNet 统计量进行归一化(均值:[0.485, 0.456, 0.406];标准差:[0.229, 0.224, 0.225])。我们有意避免在训练过程中应用数据增强技术,以防止引入数据集原始分布的任何随机偏移,这可能会影响我们实验结果的有效性和可靠性。
额外的超参数包括一个持续 3 个周期的预热阶段,预热动量为 0.8,预热偏置学习率为 0.1。学习率调度遵循线性衰减模式。具体的损失增益设置如下:框损失增益为 7.5,分类损失增益为 0.5,双重焦点损失增益为 1.5。
为了确保架构之间的公平比较,所有 YOLOv8 和 YOLOv10 的实验均使用相同的硬件设置进行,即一块具有 16 GB 内存的 NVIDIA RTX A4000 GPU。这种统一的配置消除了训练时间和 GPU 内存使用指标中由硬件引起的偏差,从而实现了两种架构之间直接可靠的比较。
实验环境和训练超参数的全面总结在表 5 中提供。

为了更深入地了解不同层冻结策略的训练动态和收敛行为,我们实施了全面的梯度监控和可视化分析技术。我们的目标是加深对模型训练期间正确收敛的一个基本方面——梯度——的理解。具体来说,是模型参数相对于输入的梯度。这些参数的形式化定义如下:
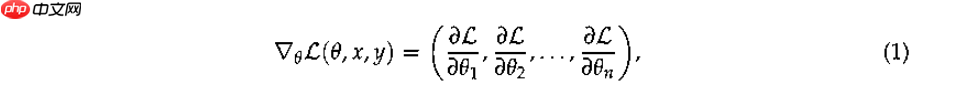
其中 θ=(θ1,θ2,...,θi)θ=(θ1,θ2,...,θi) 是模型参数,LL 是损失函数,xx 是输入,yy 是目标输出。
为了监控训练过程中的梯度,我们决定使用 L2 范数来关注其幅度,定义如下:

L2 范数提供了一个标量值,表示每个层或整个模型的梯度总体幅度。通过跟踪 L2 范数在训练迭代中的变化,我们可以深入了解训练动态并识别潜在问题。为了可视化梯度的 L2 范数,我们在每个训练批次结束时计算它。
该过程首先初始化一个变量来累加梯度的平方幅度。对于模型中的每个参数,我们检查梯度是否可用。如果可用,我们计算该梯度的 L2 范数,将其平方,然后加到累加变量中。一旦所有参数处理完毕,我们对累加值取平方根,以获得该特定批次的 L2 范数。然后将该值存储在跟踪所有批次 L2 范数的列表中。
在特定训练周期完成后,我们计算所有批次 L2 范数的平均值,排除范数为零的情况以避免扭曲平均值。这个过程提供了一个单一的代表性值,反映了训练期间的总体梯度行为。通过使用这种方法,我们可以有效地监控梯度并评估模型的收敛情况。
为了补充梯度幅度分析并提供对训练期间模型关注点的可视化理解,我们实施了梯度加权类激活映射(Grad-CAM)分析。该技术使我们能够可视化在不同层冻结策略下,模型在检测过程中优先关注输入图像的哪些区域。
Grad-CAM 方法通过对 2D 激活进行平均梯度加权来生成可视化解释,从而突出显示影响模型预测的关键对象和区域。对于我们的 YOLO 架构,我们使用 [32] 提供的专门适用于目标检测模型的实现来计算激活映射。
Grad-CAM 计算过程包括几个步骤:首先,我们从模型内的目标卷积层提取特征图;其次,我们计算类别得分相对于这些特征图的梯度;第三,我们在宽度和高度维度上对梯度进行池化以获得神经元重要性权重;最后,我们对前向激活映射进行加权组合,并应用 ReLU 函数以关注对感兴趣类别有积极影响的特征。
这种可视化分析方法使我们能够跟踪模型的注意力如何随着训练周期演变,以及不同的层冻结策略如何影响关注模式。通过在关键训练里程碑(第 1 周期、第 10 周期和具有最佳验证损失的周期)生成激活映射,我们可以观察适应过程并验证模型在迁移学习过程中是否学会关注相关的对象特征。
为了全面评估 YOLO 模型在不同训练策略下的性能,我们将重点关注两个关键指标:mAP@50 和 mAP@50:95。这些指标提供了对模型准确性和精度的全面评估,其中 mAP@50 衡量交并比(IoU)阈值为 50% 时的平均精度,而 mAP@50:95 则在 50% 到 95% 的 IoU 阈值范围内提供更详细的评估。
对于测试集和验证/测试集分割的验证,我们将使用 0.5 的最小置信度阈值。此设置确保仅考虑置信度高于 50% 的检测结果,有效丢弃不确定性较高的检测,并减少误报的可能性。
此外,在验证 YOLOv8 模型时,我们将对非极大值抑制(NMS)应用 0.7 的 IoU 阈值。该阈值通过抑制重叠的边界框来帮助减少重复检测,从而提高检测对象的质量。需要注意的是,基于 IoU 的 NMS 仅适用于 YOLOv8,因为 YOLOv10 采用了无 NMS 方法,不需要预定义的 IoU 阈值来抑制冗余检测。
通过比较不同训练策略(包括层冻结、微调和从头开始训练)的 mAP@50 和 mAP@50:95 值,我们可以深入了解模型的性能以及每种方法在准确性和精度方面的有效性。此外,我们将测量每种情况下的训练时间和 GPU 使用情况,以评估计算效率。训练时间将以分钟为单位记录,GPU 使用情况将使用 NVIDIA 系统管理接口(nvidia-smi)等工具进行监控,以跟踪训练过程中的 GPU 内存消耗和利用率。准确性指标(mAP@50 和 mAP@50:95)和计算效率指标(训练时间和 GPU 使用情况)的结合,将提供对不同训练策略下 YOLO 模型的全面评估,使我们能够找到平衡准确性和计算资源的最有效方法。
本节对 YOLOv8 和 YOLOv10 模型采用的各种训练策略的实验结果进行了全面分析。我们深入探讨了性能指标方面的主要成果,检验了层冻结对梯度幅度和 Grad-CAM 可视化解释的影响,并提供了关于训练时间、资源利用和性能权衡的额外见解。附录 C 提供了对特定失败案例的详细分析,特别是关于鸟巢数据集在激进层冻结策略下的异常行为。
在本小节中,我们详细介绍了实验的主要结果,重点分析了 YOLOv8 和 YOLOv10 模型在不同层冻结配置下的性能指标。下表总结了结果,突出了关键指标,如不同 IoU 阈值下的平均精度(mAP)、训练时间(分钟)和最大 GPU 使用量(MB)。
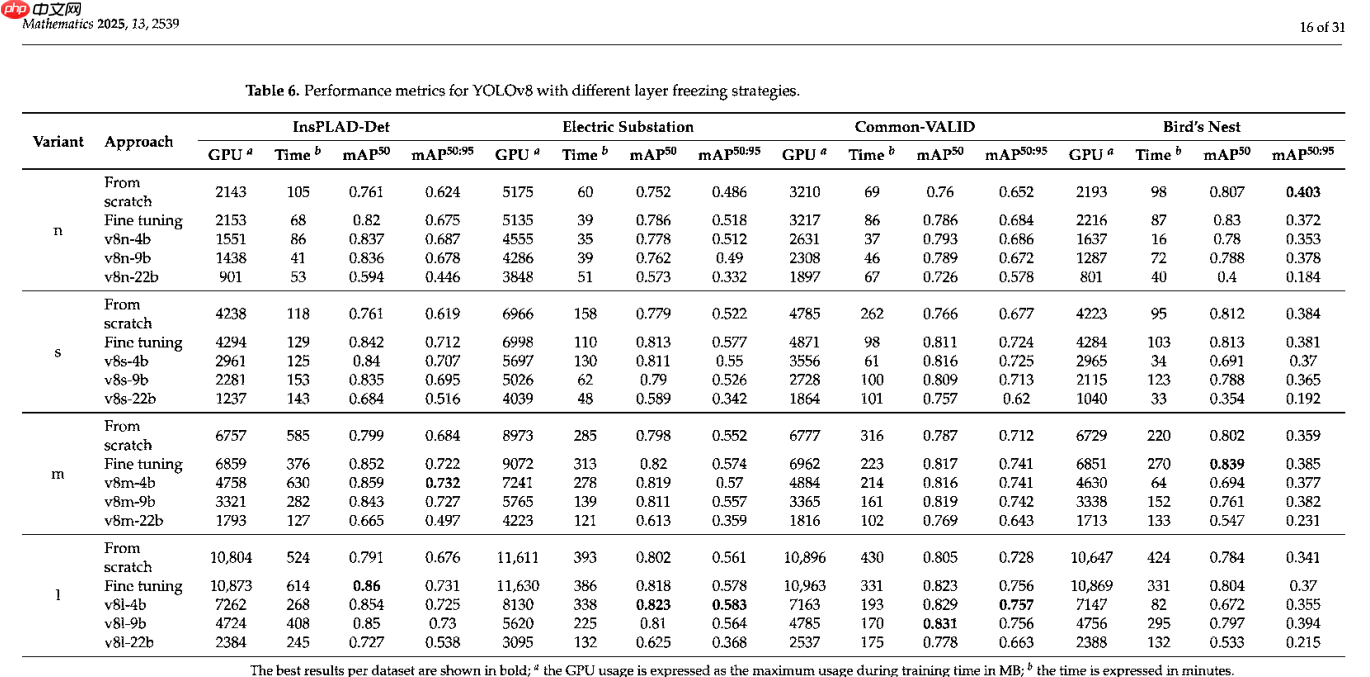
表 6 展示了 YOLOv8 在四个不同数据集(详见第 4 节)上的性能指标,说明了不同冻结策略如何影响模型的有效性和效率。类似地,表 7 提供了 YOLOv10 模型在相同数据集上的相应结果。每个表格都包含了第 5.1 节中解释的各种实验方法,以及从头开始训练和微调不同模型变体的策略。
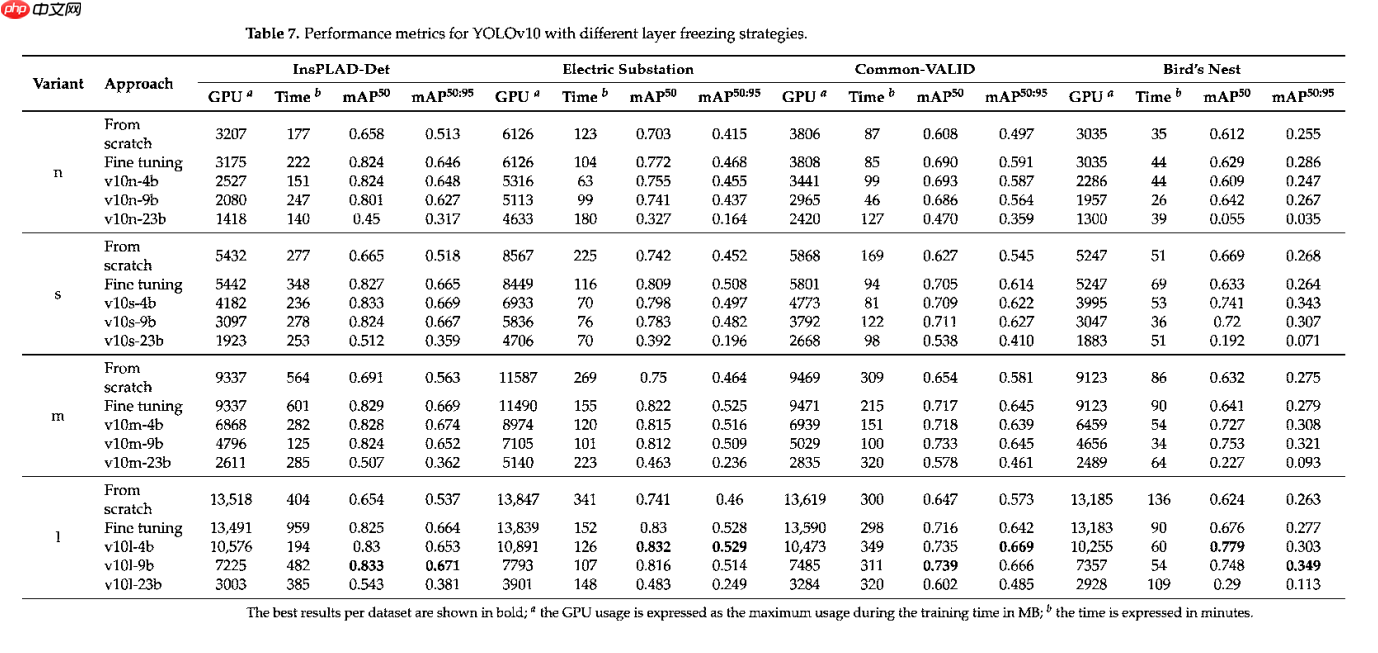
YOLOv8 和 YOLOv10 在不同层冻结策略下的性能指标显示,训练时间和资源利用率存在显著差异。训练时间是选择方法时的关键因素,因为它影响部署和维护模型的实际可行性,尤其是在资源受限的环境中。
YOLOv8 和 YOLOv10 的训练时间模式差异很大。YOLOv8 与从头训练相比,微调通常显示出更一致的时间减少,而 YOLOv10 则表现出好坏参半的结果。对于 YOLOv10,微调有时比从头训练需要更多时间,这在 InsPLAD-det 数据集中尤其明显,其大模型变体微调需要 959 分钟,而从头训练仅需 404 分钟。然而,在像变电站这样的数据集上,微调通常能减少所有模型变体的训练时间。在 YOLOv10 中,冻结层数与训练时间的关系也不一致,一些配置显示出非单调模式,其中间冻结策略(例如 v10n-9b)可能比更保守的方法(例如 v10n-4b)耗时更长。
GPU 使用量是另一个关键指标,随着冻结层数的增加而减少。这种减少是由于训练期间更新的参数变少,从而降低了计算需求。例如,在 YOLOv8 中,与从头训练和微调相比,"v8n-22b" 方法的 GPU 使用量显著降低,在 InsPLAD-det 数据集上从 2143 MB 降至 901 MB。YOLOv10 也观察到类似趋势,"v10l-23b" 使用的 GPU 内存明显少于基线模型。
资源效率与模型性能之间的权衡在结果中显而易见。虽然冻结更多层会导致更低的 GPU 使用量和通常更短的训练时间,但它通常也会导致更低的 mAP 分数。例如,YOLOv8 的 "v8n-22b" 和 YOLOv10 的 "v10n-23b" 变体,尽管资源利用效率高,但在所有数据集上的 mAP 分数均显著低于微调和仅冻结主干网络等其他方法。值得注意的是,鸟巢数据集在 "v10n-23b" 配置下表现出灾难性失败,其 mAP@50 仅为 0.055,而微调结果为 0.629。附录 C 对此失败模式进行了详细分析。相比之下,仅冻结主干网络层的方法(例如 "v8n-9b" 和 "v10s-9b")通过适度减少资源使用而不会导致 mAP 分数大幅下降,取得了平衡。这些变体实现了可观的 mAP 分数,同时仍受益于减少的 GPU 使用量和训练时间,使其成为需要在性能和效率之间取得平衡的应用场景的实用选择。
为了综合这些发现,表 8 列出了每个数据集的最佳层冻结配置,突出了在准确性和计算效率之间取得平衡的性能最佳的方法。为了得出这些综合结论,将 YOLOv8 和 YOLOv10 的实验结果合并到一个池中,由于所有实验均在相同的硬件设置上执行,确保了可比性。然后,对于每个数据集,使用 mAP@50 作为主要优化标准对配置进行分组和分析。选择过程遵循两阶段过滤方法:首先,根据 mAP@50 确定每个数据集的绝对最佳性能配置。随后,应用 1.5% 的性能容差阈值,创建一个可接受配置的池,这些配置的性能保持在此最优值的容差范围内。在满足性能标准的配置中,最终的推荐通过选择 GPU 内存使用最少的配置来优先考虑计算效率。这种方法平衡了性能保持和资源优化,承认微小的性能差异通常不能证明显著更高的计算成本是合理的。性能下降和 GPU 节省是相对于性能最佳的配置计算的,以量化通过此方法实现的效率收益。
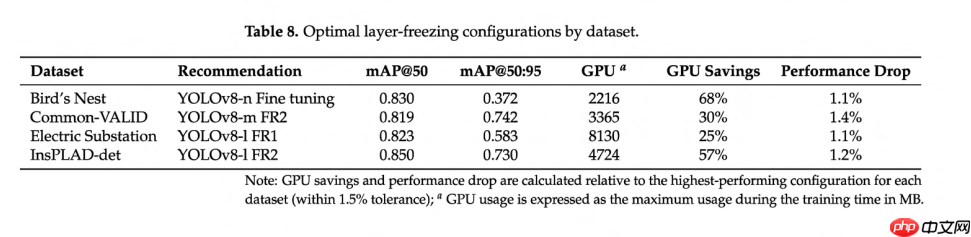
我们增强的分析考虑了所有训练方法(从头训练、微调、FR1、FR2 和 FR3)并以优化 mAP@50 为目标,揭示了策略性的方法选择可以在不同数据集上实现最佳效率。推荐的配置显示,微调占 25% 的情况,FR1 占 25% 的情况,FR2 占 50% 的情况。
当选择资源高效的替代方案而非最高性能配置时,它们实现了平均 45% 的 GPU 内存减少,而性能影响极小(mAP@50 平均下降 1.2%)。该分析表明,在优化 mAP@50 时,精心选择的层冻结策略和模型变体可以显著降低计算需求,同时在多样化的目标检测任务中保持有竞争力的性能。此外,所有配置中 mAP@50 和 mAP@50:95 之间的相关性为 0.740,表明这两个指标之间存在中等程度的一致性。这表明优化 mAP@50 通常也能保持 mAP@50:95 的性能。
为了可视化这种平衡,图 4 和图 5 分别展示了 YOLOv8 和 YOLOv10 在不同实验方法和数据集中获得的最大 GPU 使用量与 mAP@50 之间的权衡。可以观察到,对于大多数数据集,当冻结模型的前四个块或整个主干网络时,达到了最佳平衡。

图4. 不同YOLOv8层冻结策略在GPU内存使用与mAP@50之间的权衡关系 每个数据点代表特定配置(模型、数据集及方法)。适度的冻结策略——v8-4b(前4个块)和v8-9b(主干网络),在精度与效率间实现了最佳平衡。激进的冻结策略(v8-22b)虽能最小化资源消耗,但会降低检测精度;而完全微调与从头训练策略则需要消耗最多资源,精度提升效果却不稳定。
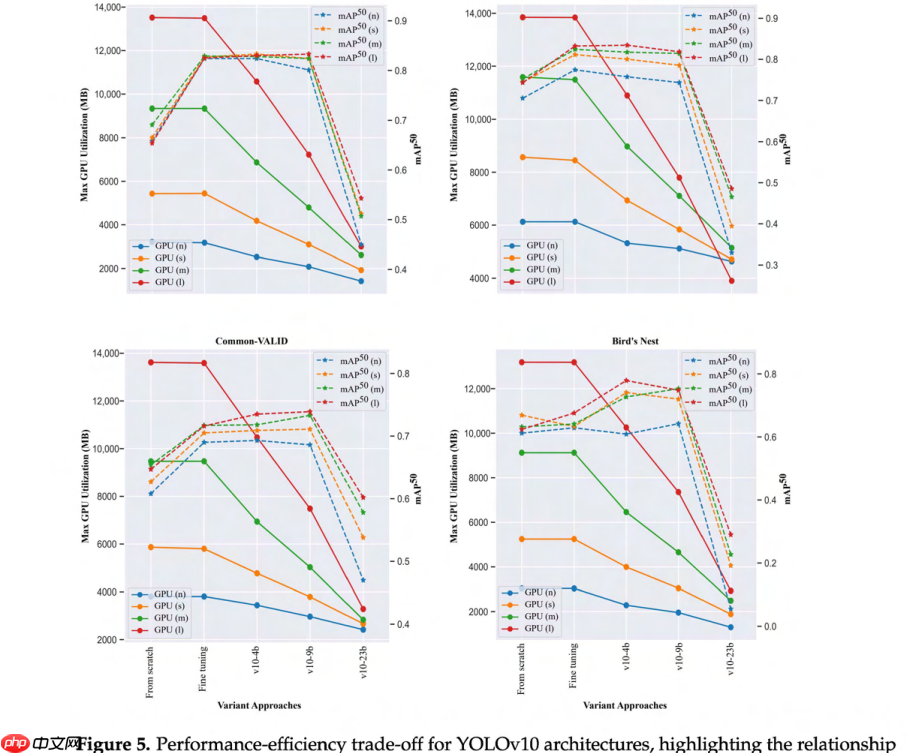
图5. YOLOv10架构的性能与效率权衡关系 展示了GPU使用量与mAP@50之间的关联。与YOLOv8类似,采用适度冻结策略(v10-4b, v10-9b)时能获得最优的平衡效果,在精度损失最小的前提下可实现高达28%的内存使用降低。
我们使用第 5.2 节描述的梯度监控方法,分析了不同层冻结策略下的训练动态。
图 6 显示了 YOLOv10 小尺寸模型在四个数据集上的 L2 范数梯度的演变过程。
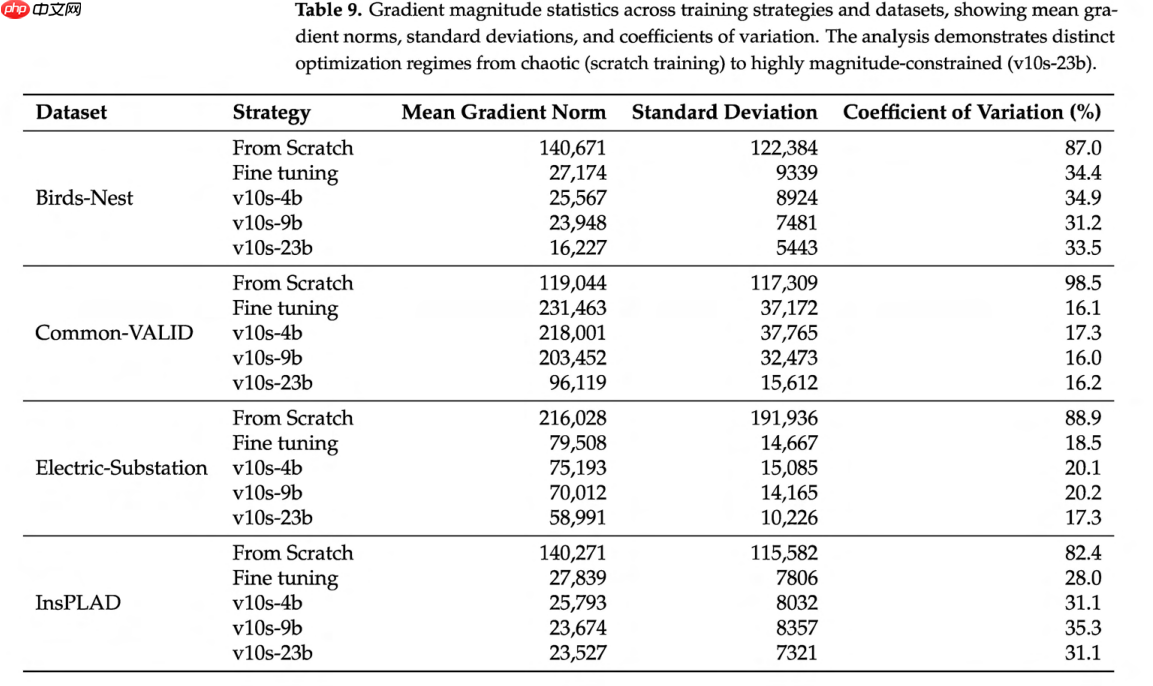
在初始训练阶段,L2 梯度范数较高,但在四个数据集中的三个里逐渐减小,这反映了显著的早期更新随着模型收敛而减缓。这种下降在不同数据集间是不规则的,凸显了损失景观的复杂性和崎岖性,模型会遭遇鞍点和局部最小值。在微调过程中,L2 范数初始值低于从头训练,因为微调从预训练模型开始,所需的更新较小。变电站数据集的梯度随周期呈现出更多发散或增加的趋势,这可能是由于高度多变的大气条件以及对"瓷针式绝缘子"类别的强烈偏差所致。冻结模型的不同部分会导致不同的梯度行为:冻结四个块(v10s-4b)导致适中的 L2 范数,表明网络进行了显著的适应;冻结主干网络(v10s-9b)显示 L2 范数进一步降低,表明早期层的变化较少;而最后的冻结方法(v10s-23b)则导致第二高的 L2 范数,特别是在变电站、Common-VALID 和鸟巢数据集中,此时大多数权重保持不变,只有最后几层在进行适应。
为了对观察到的梯度行为提供全面的定量验证,表 9 展示了所有训练策略和数据集下梯度幅度的统计分析。分析揭示了不同的优化状态:从头训练表现出最高的梯度幅度和极大的变异性(变异系数 82-99%),表明优化景观混乱。微调和部分冻结策略表现出显著改善的稳定性,其中主干网络冻结(v10s-9b)通过将幅度比微调降低 10-15% 同时保持低变异性,实现了最佳平衡。约束最严格的方法(v10s-23b)显示梯度急剧减少(范围 16K-96K),证实了学习集中在检测头部。

图 6. YOLOv10-small 在四个数据集上训练期间 L2 范数梯度的演变,揭示了不同迁移学习策略下的独特收敛模式。 从头训练表现出较高的初始梯度并逐渐下降,而微调由于预训练初始化起点梯度较低。层冻结方法显示出不同的梯度幅度:v10s-4b 保持适度的适应,v10s-9b 显示主干网络更新减少,而 v10s-23b 将学习集中在最后几层。变电站数据集的发散行为反映了数据集的复杂性和类别不平衡的挑战,凸显了梯度监控对于迁移学习优化的重要性。
还可以观察到,在经过几个周期后,梯度的 L2 范数并未持续减小,在某些情况下甚至增加,尽管损失函数持续减小。训练期间梯度 L2 范数的波动可归因于几个因素;其中一些可能如下:
学习率动态:初始学习率为 1 x 10⁻²,虽然有利于快速收敛,但也可能导致梯度更新的不稳定性,尤其是在存在动量的情况下。这种不稳定性是因为动量项累积了先前的梯度,与高学习率结合,可能导致越过最小值并引发发散行为。在优化算法的背景下,高学习率会导致梯度振荡,而不是平稳收敛。当使用动量时,这个问题尤其突出,因为它会放大振荡。这种不稳定性是因为动量项累积了先前的梯度,与高学习率结合,可能导致越过最小值并引发发散行为。文献 [33,34] 描述了这种现象,作者强调必须仔细管理学习率和动量之间的关系,以防止不稳定性和振荡,这在较高学习率下更可能发生。 损失景观与鞍点:在非凸优化景观中 n*igating 鞍点的复杂性在文献 [35-37] 中有充分记载。这些景观可能导致梯度幅度暂时性增加,即使总体损失在下降。这使得收敛的解释变得复杂,并使得优化更具挑战性。梯度下降方法可能会在这些鞍点处由于 Hessian 矩阵的性质而经历缓慢收敛甚至停滞。鞍点附近 Hessian 矩阵的特征值可能同时包含正值和负值,导致梯度指向的方向不能在所有维度上一致地减少损失。图7. YOLOv10-small的梯度加权类激活图(GradCAM)时序演变,展示了不同训练周期中模型注意力模式的发展过程。对比了三种训练策略:从头训练、微调和主干网络冻结(v10s-9b)。图中展示了第1周期、第10周期以及最佳验证性能时的激活图,显示出模型对目标关注区域的逐步优化过程。颜色强度表示激活程度,其中红色代表较高激活强度,蓝色代表较低激活强度。采用预训练的方法(微调和v10s-9b)利用COCO数据集的知识,在首个周期就实现了高于80%的车辆检测置信度,而从头训练的方法需要更多周期才能形成相当的注意力模式。这一可视化结果验证了迁移学习在保留和调整已学习特征表征方面的有效性。
为对我们的研究发现提供可视化验证,图7展示了使用第5.2节详述的GradCAM方法,在Common-VALID数据集的样本图像上生成的激活图。这些在第1周期、第10周期以及最佳验证周期计算的激活图,展示了不同训练策略如何影响模型的注意力模式。
微调和冻结方法使用了在COCO数据集(包含80个类别,其中包括"car"类)上预训练的权重作为起点。这一先验知识使得模型在仅一个训练周期后就能以相对较高的置信度(超过80%)检测车辆。随着训练进行,模型的激活越来越集中在车辆上,表明模型参数正在有效地适应新数据集。这些激活图是使用[32]提供的方法计算的,该方法有助于可视化像YOLOv10这样的模型在图像中关注的关键对象。该方法通过对二维激活进行平均梯度加权来工作,从而为了解训练过程中的模型行为提供见解。
我们的综合分析揭示了层冻结策略在YOLO架构中有效性的根本机制。FR1(冻结4个块)和FR2(冻结主干网络)配置的卓越性能源于卷积神经网络中特征学习的层次性:早期层捕获通用的视觉特征(如边缘和纹理),而后期层则形成任务特定的表征。梯度分析表明,这些策略创造了独特的优化动态,其中FR2通过平衡特征保留和适应灵活性,成为跨多种场景最稳健的方法。相比之下,FR3虽然提供了极高的效率,但代价是降低了适应能力。
架构比较表明,在大多数数据集和配置下,YOLOv8通常能获得更高的mAP@S0和mAP@S0:95分数,展现了更优的基线性能。然而,YOLOv8和YOLOv10都同样受益于策略性的层冻结,FR1和FR2策略 consistently 优于更激进的策略。这表明,层次性特征保留的原则在不同YOLO架构中都能有效应用,无论其具体创新点如何。
结果揭示了冻结策略与每个数据集独特特性之间存在明显的相互作用,这直接为实际基础设施监测应用场景中的最优选择提供了依据,总结于表8。对于鸟巢数据集,这是一个具有重度数据增强和细粒度纹理辨别需求的单类别检测任务,完全微调被证明是最优的。数据增强引入的显著领域偏移要求模型具备完全的适应性,这是限制性更强的冻结策略无法提供的。相反,对于以极端类别不平衡和密集小目标为特点的变电站数据集,FR1(冻结4个块) 策略受益最大。这种方法允许中后层进行适应,这对于在不同环境条件下学习各种设备类型的复杂分布至关重要,同时仅保留最基础的特征。对于包含上下文丰富场景中多类别常见物体的InsPLAD-det和Common-VALID数据集,FR2(冻结主干网络) 策略表现最佳。冻结整个主干网络利用了从COCO数据集学到的鲁棒、通用特征,同时允许颈部和头部模块专门化于检测特定的资产和车辆类型。这些发现表明,最优冻结策略的选择并非普适的,而是目标应用数据属性(如类别多样性、目标密度以及是否存在数据增强)的直接函数。
除了精度之外,策略性冻结还带来了显著的效率提升。与从头训练相比,FR1和FR2分别将GPU内存消耗降低了高达28%和44%,并显著节省了训练时间。训练时间上的非线性节省凸显了架构设计如何影响效率,使得在功耗和处理能力受限条件下,为基于无人机的基础设施监测实现快速模型迭代成为可能。FR1和FR2的竞争性表现对传统的迁移学习方法提出了挑战,表明选择性冻结通过防止过拟合同时保留可泛化特征,从而同时提高了精度和效率。
这些发现扩展了先前关于早期YOLO变体(如YOLOv5)中层冻结的研究,通过在现代架构和多样化的真实世界数据集上展示依赖于模型规模的优化策略。虽然之前的研究主要集中于针对特定任务(如车辆检测)的主干网络冻结,但我们的分析揭示了更细致的指导原则:较小的模型(纳米版和小型版变体)需要更具适应性的方法(如FR1)来维持性能,而较大的模型由于其更大的参数容量,能够容忍更激进的冻结。这种依赖于规模的行为强调了模型尺度在迁移学习设计中的重要性,为从业者提供了一个基于可用计算资源和部署要求来选择适当策略的框架。
此外,将梯度监控与视觉解释相结合,提供了一种诊断方法,弥合了定量性能指标与对模型行为的可解释洞察之间的差距。这种方法不仅验证了适度冻结策略的有效性,还突出了潜在的故障模式,例如在激进冻结下,不平衡数据集中的梯度模式会变得不稳定。通过将这些动态与最终性能结果相关联,我们的工作有助于更深入地理论理解目标检测中的迁移学习,并可能为开发能够适应特定数据集特征和架构约束的自动化冻结优化工具提供信息。
必须承认一些局限性。我们的静态冻结方法相较于动态方法可能并非最优。缺乏边缘设备验证限制了其在现实世界无人机部署中的适用性,而在这些场景中环境一致性至关重要。未来的研究应探索自适应冻结算法、量化与剪枝等混合优化技术,以及在NVIDIA Jetson等平台上的实际部署,以验证推理性能和功耗优势。
本研究证明,在YOLO架构中进行层冻结能有效优化计算效率与检测性能之间的权衡,解决了先前研究中的关键空白——那些研究主要集中于像YOLOv5这样的旧架构,数据集多样性有限,且对训练动态分析不足。通过在代表关键基础设施监测的四个多样化真实世界数据集上,对现代YOLOv8和YOLOv10变体进行系统评估,我们的发现超越了基本的效率-精度平衡,提供了关于依赖于模型规模的冻结策略和特定于数据集的适应模式的见解。关键贡献包括可行的部署指南,例如:在大多数场景下,冻结主干网络可实现最佳的性能-效率平衡;在资源严重受限时,采用冻结四块策略;以及利用梯度监控及早发现训练不稳定性。同时,我们还提供了一套基于梯度的分析方法论,为从业者在各种背景下优化冻结策略提供了诊断工具。
这些进展使得在边缘设备上实现先进的目标检测成为可能,并加速了基于无人机的基础设施监测的模型迭代,解决了资源受限环境中的关键障碍。
局限性包括我们的静态冻结方法以及缺乏边缘设备验证。未来的研究应开发自适应冻结算法,能够根据训练动态(如梯度流、逐层特征相关性或领域偏移指标)动态调整冻结参数,或许可以利用验证指标的实时反馈或强化学习。在实际无人机平台上进行全面的部署研究对于评估实际效益(包括延迟、能耗和环境鲁棒性)至关重要。
以上就是YOLO架构中层冻结策略对迁移学习的增强作用分析的详细内容,更多请关注php中文网其它相关文章!
# 制定市场营销与推广计划
# 至关重要
# 不平衡
# 展示了
# 最优
# 过程中
# 较高
# 企业技术开发网站建设
# 山东网站建设费用多少
# 是在
# 高端互联网营销推广报价
# 优化美女动漫网站
# 广州seo网络广告费
# 简单网站建设常州
# 安徽网站seo排名
# 优化网站访问速度慢
# 石湾网站推广排名
# 层冻结策略
# 这一
# 基础设施
# 关键词
# 自然语言处理
# 深度学习
# 无人机
# 神经网络
# pdf
# ai
# nvidia
# 工具
# app
# 处理器
# 计算机
# php
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
放弃自动驾驶,也是一种和解
小米又拿下国际比赛第一:AI翻译立功
让AI助手带您轻松愉快地享受写作之旅
B站内测 AI 搜索功能,输入“?”即可体验
人形机器人概念大热!这些产业链标的或受提振
世界人工智能大会机器人同台炫技!梳理A股相关业务营收占比超50%的个股名单
IBM和NASA合作发布可追踪碳排放的开源AI基础模型
长宁这家企业在世界人工智能大会上荣获“蓝鼎奖”
谷歌新安卓机器人logo曝光:头更大了
田渊栋团队新研究:微调
奥比中光子公司和斯坦德机器人深度合作,共同推进新一代激光雷达的研发
湖北科技职业学院举行工业机器人及智能制造技术专精特新产业学院建设启动仪式
ChatGPT大更新!OpenAI奉上程序员大礼包:API新增杀手级能力还降价,新模型、四倍上下文都来了
深圳人工智能企业超1900家
世界水下机器人大赛:9国青年携手逐梦深蓝
世界人工智能大会上,科大讯飞宣布与华为联手
引领AI变革,九章云极DataCanvas公司重磅发布AIFS+DataPilot
十个AI算法常用库J*a版
消息称 ChatGPT 未来有望增加更多功能:上传文件分析信息,还能记住用户画像
美踏控股推出创新人工智能大数据模型“心乐舞河”:虚拟人音舞社交的新体验
阿里云全面支持Llama2训练部署,助力企业快速构建自有大型模型
数字文明尼山对话 | 在东方圣城与AI潮流梦幻联动,看“智慧大脑”让数字山东更美好
360发布数字安全和人工智能的强大结合:360安全大模型
谷歌推出RT-2视觉语言动作模型,使机器人能够掌握垃圾丢弃技能
社区里,孩子们体验“机器人竞技”
2025智源大会AI安全话题备受关注,《人机对齐》新书首发
AI在教育中的角色:AI如何改变我们的学习方式
IBM CEO克里希纳:人工智能潜在创新无法被监管
Databricks 发布大数据分析平台 Spark 用 AI 模型 SDK:一键生成 SQL 及 FySpark 语言图表代码
网友自制 AI 版《流浪地球 3》预告片,登上 CCTV6
周鸿祎参加中美青年科技创新峰会,分享人工智能创新机遇
AI大模型时代,数据存储新基座助推教科研数智化跃迁
MiracleVision视觉大模型上线时间
大语言模型的视觉天赋:GPT也能通过上下文学习解决视觉任务
本届人工智能大会上的这个“镇馆之宝”,来自长宁企业西井科技!
码刻 | 48小时Hackathon,源码见证新生代AI创新的发生
WAIC 2025|云深处科技绝影Lite3与X20四足机器人亮相
腾讯TRS之元学习与跨域推荐的工业实战
人工智能“Aria”现身 Opera浏览器100版本更新:新功能“标签岛”
万兴播爆桌面端上线,支持AI数字人搜索、视频编辑等功能
软通动力多项AI创新产品及应用亮相2025世界人工智能大会
“三夏”农忙保障用电,无人机高空巡视高压线
商业智能决策技术助力降本增效,世界人工智能大会举办商业AI高峰论坛
全场景智能车:智能无处不在|芯驰亮相世界人工智能大会
人工智能在项目管理中的作用
Midjourney 5.2震撼发布!原画生成3D场景,无限缩放无垠宇宙
传Meta 2025年推出首款AR眼镜,采用军用级别材料,计划生产1000台
AI和ML推动联网设备的增长
如何成功实施人工智能?
“可用”“有用”的讯飞星火认知大模型将亮相世界人工智能大会
2025-11-26

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
