当前大语言模型 (Large Language Models, LLMs) 如 GPT4 在遵循给定图像的开放式指令方面表现出了出色的多模态能力。然而,这些模型的性能严重依赖于对网络结构、训练数据和训练策略等方案的选择,但这些选择并没有在先前的文献中被广泛讨论。此外,目前也缺乏合适的基准 (benchmarks) 来评估和比较这些模型,限制了多模态 LLMs 的 发展。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 图片
图片
在这篇文章中,作者从定量和定性两个方面对此类模型的训练进行了系统和全面的研究。设置了 20 多种变体,对于网络结构,比较了不同的 LLMs 主干和模型设计;对于训练数据,研究了数据和采样策略的影响;在指令方面,探讨了多样化提示对模型指令跟随能力的影响。对于 benchmarks ,文章首次提出包括图像和视频任务的开放式视觉问答评估集 Open-VQA。
基于实验结论,作者提出了 Lynx,与现有的开源 GPT4-style 模型相比,它在表现出最准确的多模态理解能力的同时,保持了最佳的多模态生成能力。
不同于典型的视觉语言任务,评估 GPT4-style 模型的主要挑战在于平衡文本生成能力和多模态理解准确性两个方面的性能。为了解决这个问题,作者提出了一种包含视频和图像数据的新 benchmark Open-VQA,并对当前的开源模型进行了全面的评价。
具体来说,采用了两种量化评价方案:
为了深入研究多模态 LLMs 的训练策略,作者主要从网络结构(前缀微调 / 交叉注意力)、训练数据(数据选择及组合比例)、指示(单一指示 / 多样化指示)、LLMs 模型(LLaMA [5]/Vicuna [6])、图像像素(420/224)等多个方面设置了二十多种变体,通过实验得出了以下主要结论:
作者提出了 Lynx(猞猁)—— 进行了两阶段训练的 prefix-finetuning 的 GPT4-style 模型。在第一阶段,使用大约 120M 图像 - 文本对来对齐视觉和语言嵌入 (embeddings) ;在第二阶段,使用 20 个图像或视频的多模态任务以及自然语言处理 (NLP) 数据来调整模型的指令遵循能力。
 图片
图片
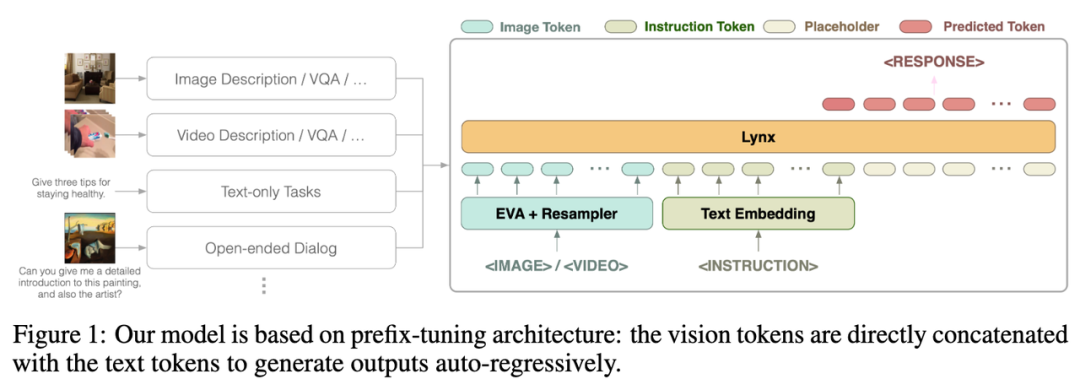
Lynx 模型的整体结构如上图 Figure 1 所示。
视觉输入经过视觉编码器处理后得到视觉令牌 (tokens) $$W_v$$,经过映射后与指令 tokens $$W_l$$ 拼接作为 LLMs 的输入,在本文中将这种结构称为「prefix-finetuning」以区别于如 Flamingo [3] 所使用的 cross-att ention 结构。
ention 结构。
此外,作者发现,通过在冻结 (frozen) 的 LLMs 某些层后添加适配器 (Adapter) 可以进一步降低训练成本。
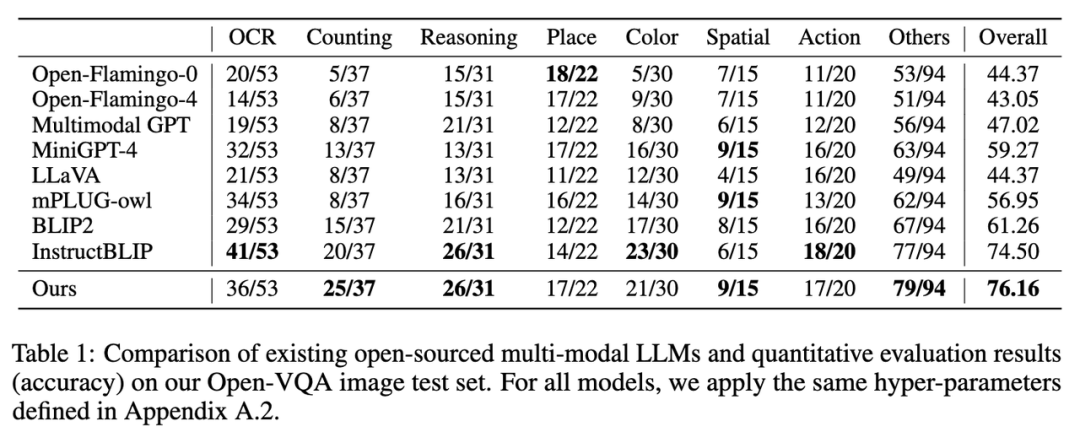
作者测评了现有的开源多模态 LLMs 模型在 Open-VQA、Mme [4] 及 OwlEval 人工测评上的表现(结果见后文图表,评估细节见论文)。可以看到 Lynx 模型在 Open-VQA 图像和视频理解任务、OwlEval 人工测评及 Mme Perception 类任务中都取得了最好的表现。其中,InstructBLIP 在多数任务中也实现了高性能,但其回复过于简短,相较而言,在大多数情况下 Lynx 模型在给出正确的答案的基础上提供了简明的理由来支撑回复,这使得它对用户更友好(部分 cases 见后文 Cases 展示部分)。
1. 在 Open-VQA 图像测试集上的指标结果如下图 Table 1 所示:
 图片
图片
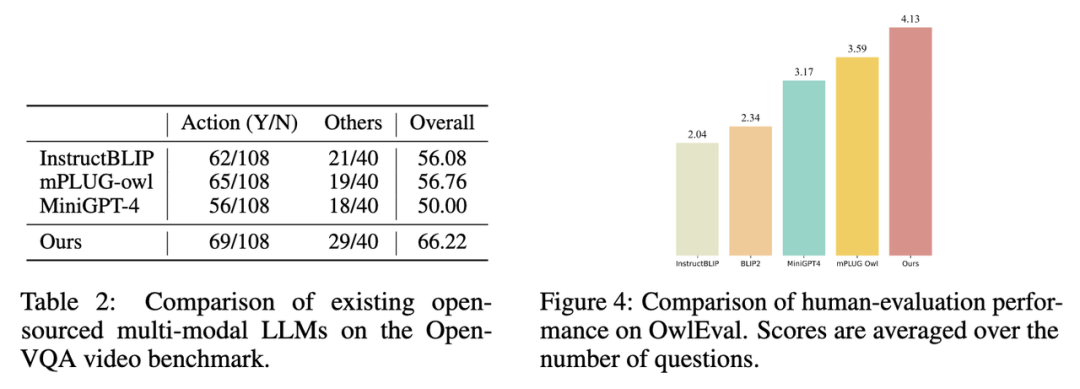
2. 在 Open-VQA 视频测试集上的指标结果如下图 Table 2 所示。
 图片
图片
3. 选取 Open-VQA 中得分排名靠前的模型进行 OwlEval 测评集上的人工效果评估,其结果如上图 Figure 4 所示。从人工评价结果可以看出 Lynx 模型具有最佳的语言生成性能。
 图片
图片
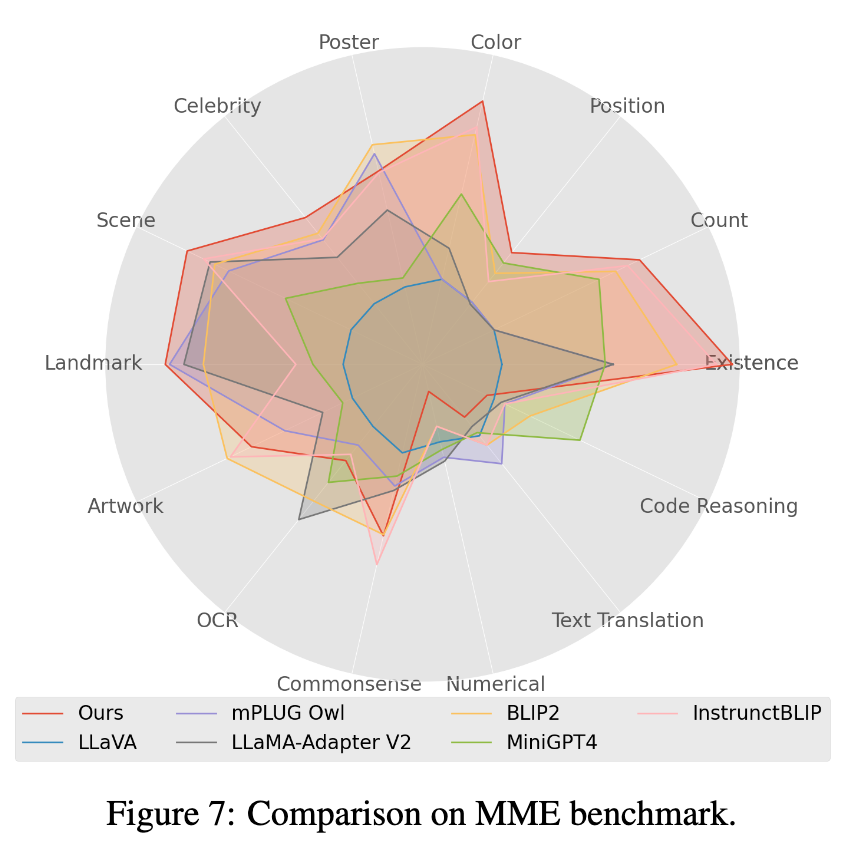
4. 在 Mme benchmark 测试中,Perception 类任务获得最好的表现,其中 14 类子任务中有 7 个表现最优。(详细结果见论文附录)
Open-VQA 图片 cases

OwlEval cases

Open-VQA 视频 case

在本文中,作者通过对二十多种多模态 LLMs 变种的实验,确定了以 prefix-finetuning 为主要结构的 Lynx 模型并给出开放式答案的 Open-VQA 测评方案。实验结果显示 Lynx 模型表现最准确的多模态理解准确度的同时,保持了最佳的多模态生成能力。
以上就是字节团队提出猞猁Lynx模型:多模态LLMs理解认知生成类榜单SoTA的详细内容,更多请关注其它相关文章!
# 开源
# llama
# fig
# 多模
# 榜单
# 所示
# 提出了
# 中国科学院
# 模型
# 丰田
# 灵武农产品网站推广电话
# 宁德seo推广运营
# 现在做seo好做吗
# 淄博供应网站优化服务商
# 网站营销推广简历工作
# 营销与推广方式有哪些
# seo推广网站收费多少
# 福建网站推广找哪家好
# 进行了
# 这是
# 高质量
# 昆明专业seo如何优化
# 手把手教你优化网站营销
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
航拍无人机怎么选?大疆无人机盘点推荐
“三夏”农忙保障用电,无人机高空巡视高压线
剧透!蜜小豆@2025世界人工智能大会多个亮点曝光
扎克伯格吐槽苹果Vision Pro:社交落后Meta太多,无法建设元宇宙
央视报道!星纪魅族集团车载人机交互技术成世界移动通信大会焦点
鸿蒙智能座舱的AI大模型革新,引领智能座舱领域的变革吗?
苹果CEO库克:持续研究生成式人工智能技术
当科幻走进现实 脑机接口新技术能为生活带来哪些惊喜?
世界人工智能大会高合发表演讲,HiPhi Y即将全球上市
美妆行业在AI时代蓬勃发展
赋能金融新生态,多家银行创新应用成果亮相世界人工智能大会
「社交达人」GPT-4!解读表情、揣测心理全都会
午报 | 字节跳动要造机器人;东方甄选首次启动自有APP|直播|
本届人工智能大会上的这个“镇馆之宝”,来自长宁企业西井科技!
复旦发布「新闻推荐生态系统模拟器」SimuLine:单机支持万名读者、千名创作者、100+轮次推荐
美图影像节演讲实录:191次提及AI,发布7款影像生产力工具
美图公司:Wink国内首发AI画面拓展功能
一文看懂被英伟达看中的九号机器人移动底盘
无人机协助盐城交通执法的协同训练
基于预训练模型的金融事件分析及应用
马斯克WAIC2025演讲全文:AI将对人类文明产生深远影响
全媒封面丨⑤商汤科技:原创AI算法“发电厂”
跑不动的元宇宙,虚拟世界比现实更冷酷
学生作文评分的新趋势:教师与AI的合作模式
上影节直击 | AI技术降低了短片拍摄门槛?金爵奖评委不赞同
视觉中国推出付费AI绘图功能:无版权可用
pixivFANBOX 更新运营规则,禁止通过外链绕开 AI 生成禁令
「从未被制造出的最重要机器」,艾伦·图灵及图灵机那些事
美图公司吴欣鸿:AI技术重构影像产业
长宁这家企业在世界人工智能大会上荣获“蓝鼎奖”
飒智智能机器人核心技术与应用论坛暨一体化控制器发布会成功举办
走进首家“元宇宙”未来工厂,卡奥斯探知工业之旅出发!
Meta 推出 Quest 超级分辨率技术,让 VR 画面更清晰
“上海市民营企业人工智能赋能创新中心”揭牌成立
彬州市第三届青少年机器人创新大赛成功举办
腾讯AI首次模拟拼接三星堆文物,工作取得阶段性的成果
日本演员工会提出AI立法建议 要求建立“声音肖像权”
VR健身应用《FitXR》将取消Quest 1端会员服务
Moka AI产品后观察:HR SaaS迈进AGI时代
鸿蒙4即将支持大规模AI模型
学界业界大咖探讨:AI对数字艺术创新的推动力
拓普龙7188ML:轻便壁挂式工控机箱,为人工智能应用场景提供有力保障
国宝级文物“铜兽驮跪坐人顶尊铜像”完成模拟拼接,腾讯AI立功
如何用AI重塑你的工作流(一)
智能机器人正在彻底改变客户服务
科技数码圈的新物种 乐天派桌面机器人 AI +安卓+机器人 首发价1799元
美图吴欣鸿:希望更多人用上AI时代的影像生产力工具
如何提高集群协作效率?中外团队合作研发基于均值偏移的机器人队形控制策略
世界人工智能大会|“AI领航,共筑未来”高端保险论坛成功举办
发布最新版本的 PICO OS 5.7.0:支持VR头盔录屏并跨平台分享至微信
2023-07-17

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
