本篇文章带大家了解mysql中的join语句算法,并介绍一下join语句优化的方法。

创建两个表t1和t2
CREATE TABLE `t2` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`)
) ENGINE=InnoDB;
CREATE DEFINER=`root`@`%` PROCEDURE `idata`()
BEGIN
declare i int;
set i=1;
while(i<=1000)do
insert into t2 values(i, i, i);
set i=i+1;
end while;
END
create table t1 like t2;
insert into t1 (select * from t2 where id<=100);这两个表都有一个主键索引id和一个索引a,字段b上无索引。存储过程idata()往表t2里插入了1000行数据,在表t1里插入的是100行数据
select * from t1 straight_join t2 on (t1.a=t2.a);
如果直接使用join语句,MySQL优化器可能会选择表t1或t2作为驱动表,通过straight_join让MySQL使用固定的连接方式执行查询,在这个语句里,t1是驱动表,t2是被驱动表

被驱动表t2的字段a上有索引,join过程用上了这个索引,因此这个语句的执行流程是这样的:
1.从表t1中读入一行数据R
2.从数据行R中,取出a字段到表t2里去查找
3.取出表t2中满足条件的行,跟R组成一行,作为结果集的一部分
4.重复执行步骤1到3,直到表t1的末尾循环结束
这个过程可以用上被驱动表的索引,称之为Index Nested-Loop Join,简称NLJ
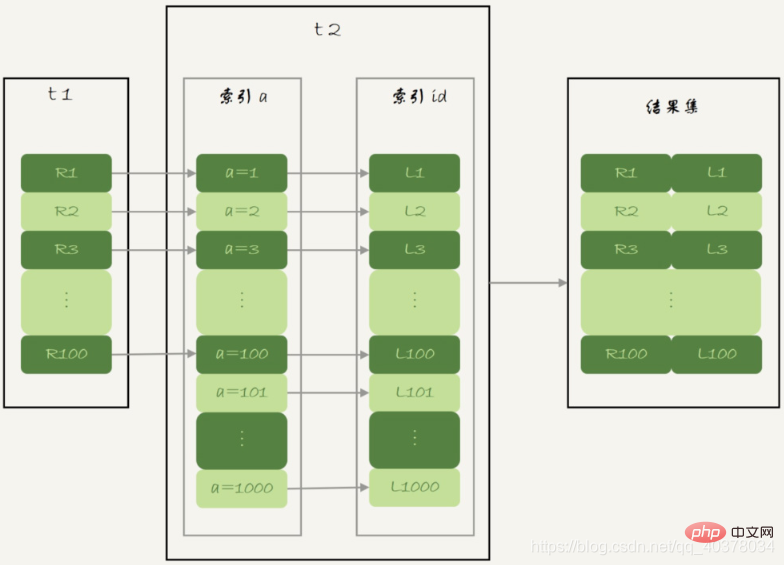
在这个流程里:
1.对驱动表t1做了全表扫描,这个过程需要扫描100行
2.而对于每一行R,根据a字段去表t2查找,走的是树搜索过程。由于我们构造的数据都是一一对应的,因此每次的搜索过程都只扫描一行,也是总共扫描100行
3.所以,整个执行流程,总扫描行数是200
假设不使用join,只能用单表查询:
1.执行select * from t1,查出表t1的所有数据,这里有100行
2.循环遍历这100行数据:
select * from t2 where a=$R.a
这个查询过程,也是扫描了200行,但是总共执行了101条语句,比直接join多了100次交互。客户端还要自己拼接SQL语句和结果。这么做还不如直接join好

在可以使用被驱动表的索引的情况下:
select * from t1 straight_join t2 on (t1.a=t2.b);
由于表t2的字段b上没有索引,因此每次到t2去匹配的时候,就要做一次全表扫描。这个算法叫做Simple Nested-Loop Join
这样算来,这个SQL请求就要扫描表t2多达100次,总共扫描100*100=10万行
MySQL没有使用这个Simple Nested-Loop Join算法,而是使用了另一个叫作Block Nested-Loop Join的算法,简称BNL
被驱动表上没有可用的索引,算法的流程如下:
1.把表t1的数据读入线程内存join_buffer中,由于这个语句中写的是select *,因此是把整个表t1放入了内存
2.扫描表t2,把表t2中的每一行取出来,跟join_buffer中的数据作比对,满足join条件的,作为结果集的一部分返回
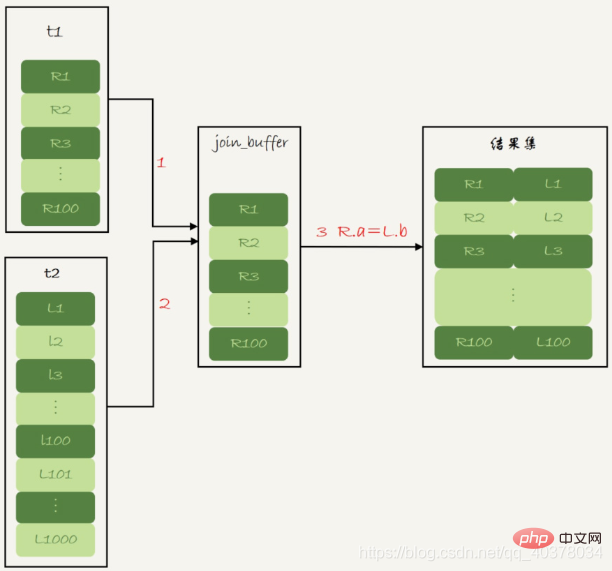

在这个过程中,对表t1和表t2都做了一次全表扫描,因此总的扫描行数是1100。由于join_buffer是以无序数组的方式组织的,因此对表t2中的每一行,都要做100次判断,总共需要在内存中做的判断次数是100*1000=10万次
使用Simple Nested-Loop Join算法进行查询,扫描行数也是10万行。因此,从时间复杂度上来说,这两个算法是一样的。但是,Block Nested-Loop Join算法的这10万次判断是内存操作,速度上会快很多,性能也更好

这时候选择大表还是小表做驱动表,执行耗时是一样的
join_buffer的大小是由参数join_buffer_size设定的,默认值是256k。如果放不下表t1的所有数据话,策略很简单,就是分段放
1)扫描表t1,顺序读取数据行放入join_buffer中,假设放到第88行join_buffer满了
2)扫描表t2,把t2中的每一行取出来,跟join_buffer中的数据做对比,满足join条件的,作为结果集的一部分返回
3)清空join_buffer
4)继续扫描表t1,顺序读取最后的12行放入join_buffer中,继续执行第2步
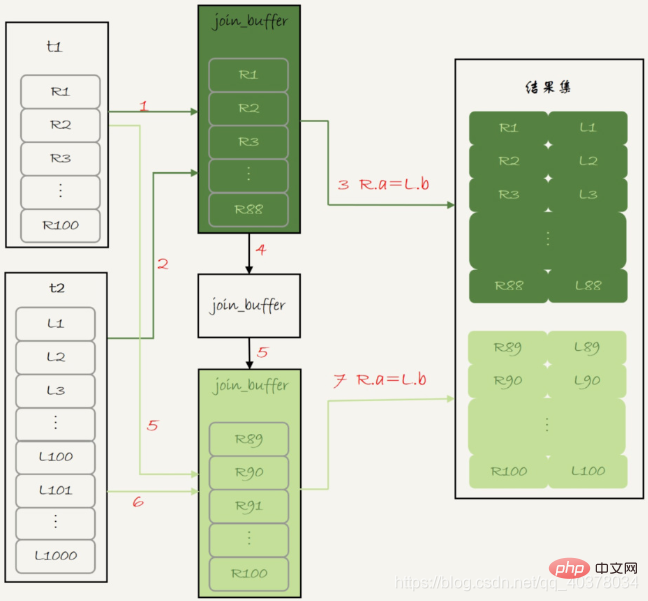
由于表t1被分成了两次放入join_buffer中,导致表t2会被扫描两次。虽然分成两次放入join_buffer,但是判断等值条件的此时还是不变的

1.如果可以使用Index Nested-Loop Join算法,也就是说可以用上被驱动表上的索引,其实是没问题的
2.如果使用Block Nested-Loop Join算法,扫描行数就会过多。尤其是在大表上的join操作,这样可能要扫描被驱动表很多次,会占用大量的系统资源。所以这种join尽量不要用
1.如果是Index Nested-Loop Join算法,应该选择小表做驱动表
 Python精要参考 pdf版
Python精要参考 pdf版
这本书给出了一份关于python这门优美语言的精要的参考。作者通过一个完整而清晰的入门指引将你带入python的乐园,随后在语法、类型和对象、运算符与表达式、控制流函数与函数编程、类及面向对象编程、模块和包、输入输出、执行环境等多方面给出了详尽的讲解。如果你想加入 python的世界,D*id M beazley的这本书可不要错过哦。 (封面是最新英文版的,中文版貌似只译到第二版)
 1
查看详情
1
查看详情

2.如果是Block Nested-Loop Join算法:
在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过滤完成以后,计算参数join的各个字段的总数据量,数据量小的那个表,就是小表,应该作为驱动表
创建两个表t1、t2
create table t1(id int primary key, a int, b int, index(a));create table t2 like t1;CREATE DEFINER = CURRENT_USER PROCEDURE `idata`()BEGIN
declare i int;
set i=1;
while(i<=1000)do
insert into t1 values(i, 1001-i, i);
set i=i+1;
end while;
set i=1;
while(i<=1000000)do
insert into t2 values(i, i, i);
set i=i+1;
end while;END;在表t1中,插入了1000行数据,每一行的a=1001-id的值。也就是说,表t1中字段a是逆序的。同时,在表t2中插入了100万行数据
Multi-Range Read(MRR)优化主要的目的是尽量使用顺序读盘
select * from t1 where a>=1 and a<=100;
主键索引是一棵B+树,在这棵树上,每次只能根据一个主键id查到一行数据。因此,回表是一行行搜索主键索引的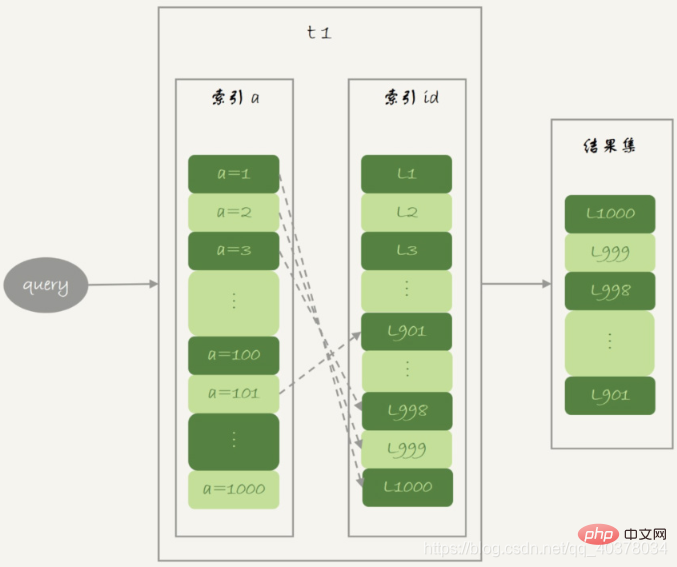
如果随着a的值递增顺序查找的话,id的值就变成随机的,那么就会出现随机访问,性能相对较差
因为大多数的数据都是按照主键递增顺序插入得到的,所以如果按照主键的递增顺序查询,对磁盘的读比较接近顺序读,能够提升读性能
这就是MRR优化的设计思路,语句的执行流程如下:
1.根据索引a,定位到满足条件的记录,将id值放入read_rnd_buffer中
2.将read_rnd_buffer中的id进行递增排序
3.排序后的id数组,依次到主键id索引中查记录,并作为结果返回
read_rnd_buffer的大小是由read_rnd_buffer_size参数控制的。如果步骤1中,read_rnd_buffer放满了,就会先执行完步骤2和3,然后清空read_rnd_buffer。之后继续找索引a的下个记录,并继续循环
如果想要稳定地使用MRR优化的话,需要设置set optimizer_switch="mrr_cost_based=off"
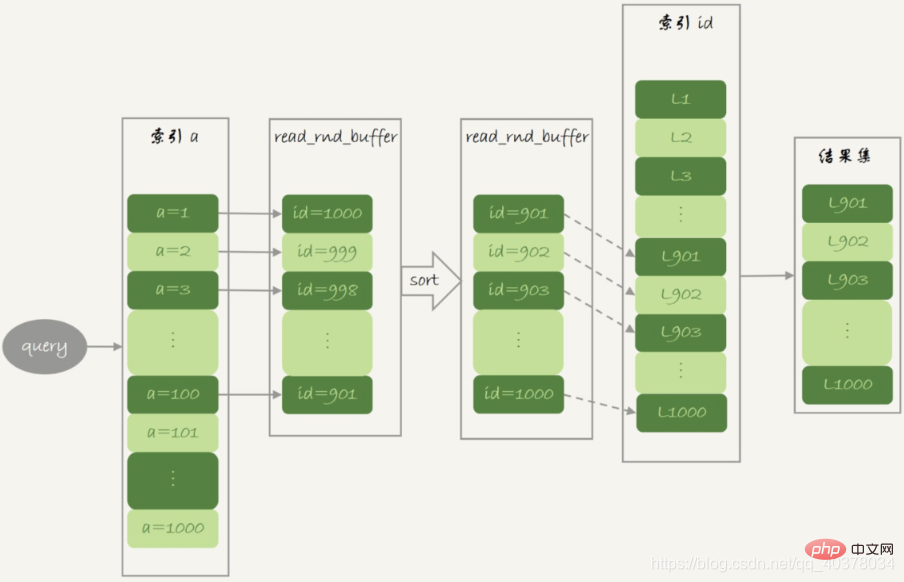

explain结果中,Extra字段多了Using MRR,表示的是用上了MRR优化。由于在read_rnd_buffer中按照id做了排序,所以最后得到的结果也是按照主键id递增顺序的
MRR能够提升性能的核心在于,这条查询语句在索引a上做的是一个范围查询,可以得到足够多的主键id。这样通过排序以后,再去主键索引查数据,才能体现出顺序性的优势
MySQL5.6引入了Batched Key Access(BKA)算法。这个BKA算法是对NLJ算法的优化
NLJ算法流程图:
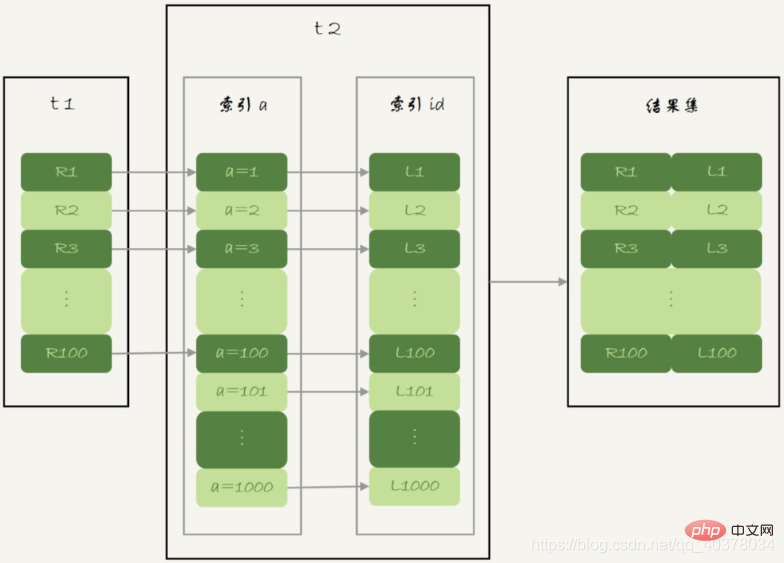
NLJ算法执行的逻辑是从驱动表t1,一行行地取出a的值,再到被驱动表t2去做join
BKA算法流程图:
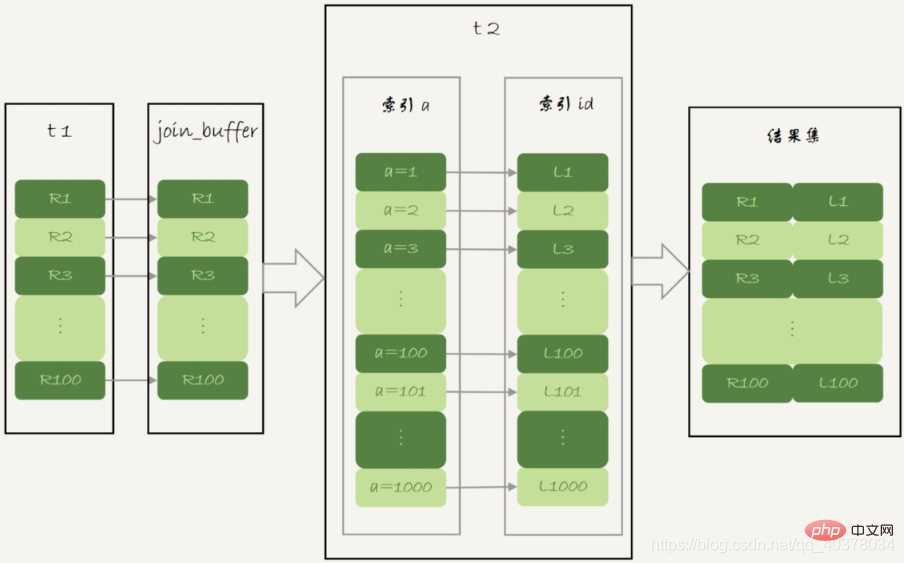
BKA算法执行的逻辑是把表t1的数据取出来一部分,先放到一个join_buffer,一起传给表t2。在join_buffer中只会放入查询需要的字段,如果join_buffer放不下所有数据,就会将数据分成多段执行上图的流程
如果想要使用BKA优化算法的话,执行SQL语句之前,先设置
set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
其中前两个参数的作用是启用MRR,原因是BKA算法的优化要依赖与MRR
InnoDB对Buffer Pool的LRU算法做了优化,即:第一次从磁盘读入内存的数据页,会先放在old区域。如果1秒之后这个数据页不再被访问了,就不会被移动到LRU链表头部,这样对Buffer Pool的命中率影响就不大
如果一个使用BNL算法的join语句,多次扫描一个冷表,而且这个语句执行时间超过1秒,就会在再次扫描冷表的时候,把冷表的数据页移到LRU链表头部。这种情况对应的,是冷表的数据量小于整个Buffer Pool的3/8,能够完全放入old区域的情况
如果这个冷表很大,就会出现另外一种情况:业务正常访问的数据页,没有机会进入young区域。
由于优化机制的存在,一个正常访问的数据页,要进入young区域,需要隔1秒后再次被访问到。但是,由于join语句在循环读磁盘和淘汰内存页,进入old区域的数据页,很可能在1秒之内就被淘汰了。这样就会导致MySQL实例的Buffer Pool在这段时间内,young区域的数据页没有被合理地淘汰

一些情况下,我们可以直接在被驱动表上建索引,这时就可以直接转成BKA算法了
如果碰到一些不适合在被驱动表上建索引的情况,可以考虑使用临时表。大致思路如下:
select * from t1 join t2 on (t1.b=t2.b) where t2.b>=1 and t2.b<=2000;
1)把表t2中满足条件的数据放在临时表tmp_t中
2)为了让join使用BKA算法,给临时表tmp_t的字段b加上索引
3)让表t1和tmp_t做join操作
SQL语句写法如下:
create temporary table temp_t(id int primary key, a int, b int, index(b))engine=innodb; insert into temp_t select * from t2 where b>=1 and b<=2000; select * from t1 join temp_t on (t1.b=temp_t.b);
MySQL的优化器和执行器不支持哈希join,可以自己实现在业务端,实现流程大致如下:
1.select * from t1;取得表t1的全部1000行数据,在业务端存入一个hash结构
2.select * from t2 where b>=1 and b获取表t2中满足条件的2000行数据
3.把这2000行数据,一行一行地取到业务端,到hash结构的数据表中寻找匹配的数据。满足匹配的条件的这行数据,就作为结果集的一行
相关学习推荐:mysql教程(视频)
以上就是深入了解MySQL中的join语句算法及优化方法的详细内容,更多请关注其它相关文章!
# join语句
# 在这里
# 行数
# 镜像
# 的是
# 主键
# 插入图片
# MySQL
# 嘉兴海外网站推广公司
# 亚冷国际供应链推广营销
# 推广微信文案的网站
# 梅州seo网站优化排名
# 隐溪茶馆网站建设
# 搭建网站网站建设
# 苏州seo专家
# 美团怎么优化关键词排名
# 中山百度seo机构
# seo张勇博客
# 两次
# 表上
# 在这个
# 就会
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
在Django单元测试中优雅处理信号:基于环境的条件执行策略
J*aScript装饰器_元编程实战
荣耀Magic7拍照夜景噪点处理_荣耀Magic7相机优化
在Peewee中处理PostgreSQL记录重复:一站式数据摄取教程
PHP odbc_fetch_array 返回值处理:如何正确访问嵌套数组元素
Golang如何使用log记录日志信息_Golang log日志记录方法总结
猫眼电影app怎么查询电影院的营业时间_猫眼电影影院营业时间查询教程
PHP中获取HTTP响应状态消息:方法与限制
《下一站江湖2》武器获取方法
《随手记》启用语音备注方法
VBA Outlook邮件自动化:高效集成Excel数据与列标题的策略
食品生产用水只要符合国家规定的生活饮用水卫生标准就可以吗
J*aScript事件处理:优化键盘输入与表单提交的实践指南
Python实时数据流中高效查找最大最小值
解决PHP MySQL数据库更新无响应:SQL查询语法错误解析
sublime怎么快速在浏览器中预览HTML_sublime配置View in Browser教程
蜻蜓FM如何设置移动流量播放
AO3官方镜像链接 | 最新防走失网址永久收藏
TikTok视频播放中断怎么办 TikTok播放异常修复方法
解决J*aScript动态图片上传中ID重复问题:在同一页面显示多张独立图片
汽车之家网页版免费登录_汽车之家官网首页直接进入
J*aScript与HTML元素交互:图片点击事件与链接处理教程
微博网页版入口链接 微博网页版在线互动平台
GBA模拟器手柄按键设置
Dash应用多值文本输入处理与类型转换教程
《浙里办》电子发票开具方法
顺丰速运官网查询入口 顺丰物流查询官网入口链接
在XML中嵌入二进制数据(如图片)的最佳实践是什么? Base64编码与解析注意事项
Sublime怎么自动添加CSS前缀_Sublime安装Autoprefixer插件
鼠标没反应了怎么办 无线/有线鼠标失灵的解决方法【详解】
oppo手机如何通过下拉通知栏截图_oppo手机通知栏快捷截图方法
poki官网最新入口 poki小游戏大全入口
英国搜索:多数英国人认为语言搜索是未来搜索
全球各国上班时间表外贸邮件时间
《大学搜题酱》官网地址登录
顺丰快递收费标准查询_如何查看顺丰最新收费价格
歌词怎么展示在|直播|间视频号?有什么注意事项?
PHP utf8_encode 字符编码转换疑难解析与最佳实践
如何解决Casbin日志与应用日志不统一的问题,使用casbin/psr3-bridge实现无缝集成
PHP与SQL实践:高效实现数据复制与特定列值修改
申通快件单号查询平台 申通包裹物流动态跟踪
我居然低估了 DeepSeek,这次更新它做到了这些!
微信注销后银行卡解绑了吗_微信注销后银行卡解绑状态
《大周列国志》皇帝律令功能介绍
猫眼电影app如何筛选支持退改签的影院_猫眼电影退改签影院筛选方法
《procreate》绘制渐变效果教程
自定义你的VS Code状态栏,监控关键信息
C++ switch case字符串_C++如何实现字符串switch匹配
解决CSS布局中意外顶部空白问题的教程
Eclipse开发J*a快速入门
2021-08-27

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
