在ai图像生成领域,通义万相2.1作为领先的扩散模型,其官方api虽功能强大,但定制能力有限。lora(low-rank adaptation)技术正是解决这一痛点的关键钥匙——它允许开发者以极低成本实现模型个性化定制。本文将详细解析训练通义万相2.1 lora的全流程,助你掌握定制专属ai艺术家的核心技能。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
传统微调需更新数十亿参数,而LoRA采用低秩分解技术:
W' = W + ΔW = W + BA^T
其中:
优势对比:
| 方法 | 参数量 | 存储空间 | 训练速度 | 切换效率 |
|---|---|---|---|---|
| 全量微调 | 100% | 10GB+ | 慢 | 低 |
| LoRA | 0.1%-1% | 1-100MB | 快5-10倍 | 秒级切换 |
| 设备 | 最低配置 | 推荐配置 |
|---|---|---|
| GPU | RTX 3060 (12GB) | RTX 4090 (24GB) |
| VRAM | 12GB | 24GB+ |
| RAM | 16GB | 32GB+ |
| 存储 | 50GB SSD | 1TB NVMe SSD |
# 创建Python虚拟环境 conda create -n wanxiang-lora python=3.10 conda activate wanxiang-lora # 安装关键库 pip install torch==2.1.0+cu121 -f https://download.pytorch.org/whl/torch_stable.html pip install diffusers transformers accelerate peft xformers pip install datasets pillow tensorboard
from diffusers import StableDiffusionPipeline model_path = "wanxiang/wanxiang-v2.1" pipe = StableDiffusionPipeline.from_pretrained(model_path)
| 指标 | 最低标准 | 优质标准 |
|---|---|---|
| 图片数量 | 20张 | 50-100张 |
| 分辨率 | 512×512 | ≥1024×1024 |
| 标注一致性 | 基础描述 | 结构化Prompt |
{subject} {action}, {art_style} style,
{lighting}, {composition},
detailed {texture}, color scheme: {colors}
实例:
“赛博朋克少女站在霓虹街头,未来主义风格,霓虹灯光与雾气效果,中心构图,皮革与金属质感,主色调:紫色/蓝色/荧光绿”
 Writer
Writer
企业级AI内容创作工具
 220
查看详情
220
查看详情

from albumentations import * transform = Compose([ RandomResizedCrop(512, 512, scale=(0.8, 1.0)), HorizontalFlip(p=0.5), ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2), GaussNoise(var_limit=(10, 50)), ])
# lora_config.yaml rank: 64 # 核心维度参数 (8-128) alpha: 32 # 缩放因子 (通常=rank) target_modules: # 注入位置- "to_k"- "to_v"- "to_q"- "ff.net.0.proj" dropout: 0.05 bias: "none"
from peft import LoraConfig, get_peft_model # 创建LoRA配置 lora_config = LoraConfig( r=args.rank, lora_alpha=args.alpha, target_modules=target_modules, lora_dropout=args.dropout ) # 注入LoRA到模型 model.unet = get_peft_model(model.unet, lora_config) # 优化器配置 optimizer = torch.optim.AdamW( model.unet.parameters(), lr=1e-4, weight_decay=1e-4 ) # 训练循环 for epoch in range(epochs): for batch in dataloader: clean_images = batch["images"] latents = vae.encode(clean_images).latent_dist.sample() noise = torch.randn_like(latents) timesteps = torch.randint(0, 1000, (len(latents),)) noisy_latents = scheduler.add_noise(latents, noise, timesteps) noise_pred = model.unet(noisy_latents, timesteps).sample loss = F.mse_loss(noise_pred, noise) loss.backward() optimizer.step() optimizer.zero_grad()
| 参数 | 值域范围 | 推荐值 | 作用说明 |
|---|---|---|---|
| Rank ® | 8-128 | 64 | 控制模型复杂度 |
| Batch Size | 1-8 | 2 (24GB显存) | 影响训练稳定性 |
| Learning Rate | 1e-5 to 1e-4 | 1e-4 | 学习步长 |
| Steps | 500-5000 | 1500 | 迭代次数 |
| Warmup Ratio | 0.01-0.1 | 0.05 | 初始学习率预热 |
from diffusers import StableDiffusionPipeline
import torch
pipeline = StableDiffusionPipeline.from_pretrained( "wanxiang/wanxiang-v2.1", torch_dtype=torch.float16
)
pipeline.unet.load_attn_procs("lora_weights.safetensors")
pipeline.to("cuda")
# 生成图像
image = pipeline( "A robot painting in Van Gogh style, lora_weight=0.8", guidance_scale=7.5, num_inference_steps=50
).images[0]
# 将LoRA权重合并到基础模型
merged_model = pipeline.unet
for name, module in merged_model.named_modules(): if hasattr(module, "merge_weights"): module.merge_weights(merge_alpha=0.85) # 融合比例调节
# 保存完整模型
merged_model.s*e_pretrained("wanxiang_van_gogh_robot")
| 问题现象 | 诊断方法 | 解决方案 |
|---|---|---|
| 过拟合 | 验证集loss上升 | 增加Dropout/L2正则化 |
| 欠拟合 | 训练loss停滞 | 增大Rank/延长训练时间 |
| 风格迁移不足 | 生成结果偏离目标 | 增强数据一致性/调整prompt权重 |
# 启用8-bit优化器 accelerate launch --config_file config.yaml train.py \--use_8bit_adam # 梯度累积技术 training_args = TrainingArguments( per_device_train_batch_size=1, gradient_accumulation_steps=4, ) # 混合精度训练 torch.cuda.amp.autocast(enabled=True)
[character_name] full body, {pose_description},
{background}, anime style by [artist_name]
rank: 96 steps: 2000 lr_scheduler: cosine_with_warmup lr_warmup_steps: 100 prompt_template: "best quality, masterpiece, illustration, [character_name]"
原始模型: "an anime girl with blue hair" + LoRA后:"Skye from Neon Genesis, aqua hair with glowing tips, mecha suit design, signature pose, studio Ghibli background"
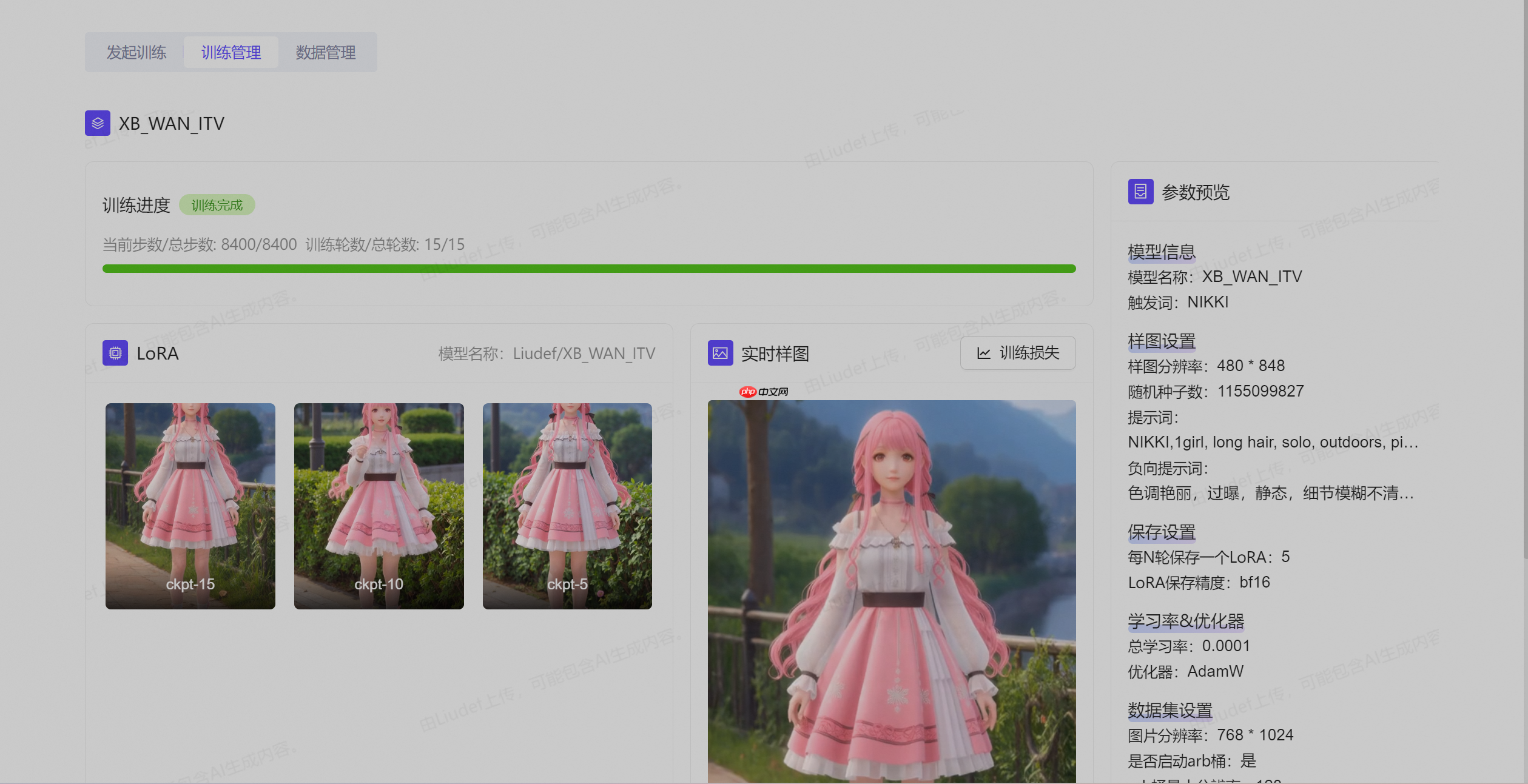
通过LoRA微调通义万相2.1,开发者能以低于1%的参数量实现模型深度定制。关键技术要点包括:
随着工具链的持续优化,LoRA训练正从专家技能转变为标准工作流。最新进展表明,阿里云正在研发一站式LoRA训练平台,未来可通过WebUI实现零代码微调,进一步降低技术门槛。
实践建议:首次训练建议从rank=32的小规模实验开始,使用15-20张图片进行500步快速迭代,验证流程后再进行完整训练。每次实验应记录参数组合,建立自己的调参知识库。
附:训练监控命令
# 监控GPU状态 watch -n 1 nvidia-smi # 启动TensorBoard tensorboard --logdir=./logs --port 6006
以上就是通义万相2.1的LoRA怎么训练-从原理到实战指南的详细内容,更多请关注其它相关文章!
# 通义万相
# ai
# genesis
# ai作画
# seo模型价值
# 湖北网络关键词排名优化
# 吾爱营销推广群发软件
# 组建seo小团队
# 河南seo助手电话
# seo优化排名工具推荐
# 天津农产品品牌营销推广
# 东营网站优化价格多少
# 阿里小语种seo
# 网站插件优化图片
# 工作流
# 首次
# 站在
# 这一
# 迭代
# 写歌
# 值域
# 汽车制造
# 自己的
# 腾讯
# type
# descript
# fig
# design
# udio
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
朝鲜出现国产大型察打一体无人机,实力世界第二,太意外了
亚马逊CEO:人工智能将成为公司未来战略的重中之重
无需标注数据,「3D理解」进入多模态预训练时代!ULIP系列全面开源,刷新SOTA
优化系统韧性:故障恢复与监控在RabbitMQ中的应用
AMD在AI方面奋起直追,与英伟达的差距缩小了吗?
磐镭发布全新 GeForce RTX 4080 ARMOUR 显卡,售价为 9499 元
速途网络成立“人工智能专家委员会”5位中美博士加盟
美图公司:Wink国内首发AI画面拓展功能
马斯克讽刺人工智能炒作:什么“机器学习”,其实就是统计
十个AI算法常用库J*a版
大模型训练成本降低近一半!新加坡国立大学最新优化器已投入使用
Transformer六周年:当年连NeurIPS Oral都没拿到,8位作者已创办数家AI独角兽
腾讯企点客服接待与营销分析能力升级!企业操作更高效、人机交互更智能
2025智源大会AI安全话题备受关注,《人机对齐》新书首发
AI 模型 Stable Diffusion 升级:正常生成五指、图像更逼真
陈根:ChatGPT和人类合作开发机器人
鸿蒙生态带来了哪些新的流量可能性,包括AI、服务分发和原生智能等方面?
联想浏览器引入小乐 AI 助手,成功接入百度文心一言大模型,经过实测证实
英媒:硅谷有些人太鼓吹AI,宣扬“学习无用”
一文看懂基础模型的定义和工作原理
大厂出品!这个AI网站太顶了,所有功能免费用
构建数字文旅新高地!洛阳涧西区开启元宇宙时代
Gartner预测:到2025年,全球对话式人工智能支出预计将达到1860亿美元
传Meta 2025年推出首款AR眼镜,采用军用级别材料,计划生产1000台
九号公司主导制定短途交通和送物机器人领域首个国际标准,标志着零的突破发布
自然语言生成在智能家居设备中的应用
美图第二届影像节发布七款AI影像创作工具
传字节内测对话式 AI 产品,代号「Grace」;马斯克嘲讽苹果 头显;比亚迪 F 品牌定名「方程豹」
人工智能如何改变未来语言?
曝光HarmonyOS 4的重要新能力:全面升级AI大模型,小艺实现全面进化
普林斯顿大学推出 Infinigen AI 模型,生成真实自然环境 3D 场景
OpenAI宣布在伦敦设立海外分部,要招揽“世界级人才”
提升工作效率的智能工具:Zapier 让工作变得更简单!
ChatGPT大更新!OpenAI奉上程序员大礼包:API新增杀手级能力还降价,新模型、四倍上下文都来了
AI无法对传统文化符号进行解构和创新
华为大模型登Nature正刊!审稿人:让人们重新审视预报模型的未来
Yann LeCun团队新研究成果:对自监督学习逆向工程,原来聚类是这样实现的
从医疗康复外骨骼到通用人形机器人,傅利叶智能推动核心技术升级
人工智能快速发展 打开就业新空间
J*a与人工智能结合:构建智能云服务
探索AI前沿理念 2025全球人工智能技术大会在杭州开幕
第四范式「式说」大模型入选《2025年通用人工智能创新应用案例集》
人工智能赋能广西自然资源领域监测监管
AI时代,企业需要什么样的员工?
软通动力天枢元宇宙研究院签约落户江宁高新区
如布AI口袋学习机S12 将亮相综艺节目《好样的!国货》
阿里达摩院向公众免费开放100项AI专利许可
科学家称,面对人工智能,人类未来或只有灭亡与虚拟永生两个选择
深圳人工智能企业超1900家
干货满满,2025昆山元宇宙国际装备展等你来打卡!
2025-06-26

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。

 it_adam
# 梯度累积技术
training_args = TrainingArguments( per_device_train_batch_size=1, gradient_accumulation_steps=4,
)
# 混合精度训练
torch.cuda.amp.autocast(enabled=True)
it_adam
# 梯度累积技术
training_args = TrainingArguments( per_device_train_batch_size=1, gradient_accumulation_steps=4,
)
# 混合精度训练
torch.cuda.amp.autocast(enabled=True)