70年AI研究得出了《苦涩的教训》:为什么说AI创业也在重复其中的错误?
Scaling Laws 是否失灵,这个话题从 2025 年年尾一直讨论至今,也没有定论。Ilya Sutskever 在 NeurIPS 会上直言:大模型预训练这条路可能已经走到头了。上周的 CES 2025,黄仁勋有提到,在英伟达看来,Scaling Laws 仍在继续,所有新 RTX 显卡都在遵循三个新的扩展维度:预训练、后训练和测试时间(推理),提供了更佳的实时视觉效果。而这一切的思考,都可以追溯到「RL 之父」 Rich Sutton 在 2019 年发表的经典短文 The Bitter Lesson 《苦涩的教训》。Y Combinator 校友日上,Andon Labs 的 CEO 兼联合创始人 Lukas Petersson 听完 100 多个项目路演后写下了一个有趣的观察:《苦涩的教训》中所写的 AI 研究历史似乎正在 AI 创业界重演。研究人员曾一次又一次试图通过精巧的工程设计来提升性能,但最终都败给了简单粗暴的「加大算力」方案。而今天,AI 产品的开发者们,似乎正在重走这条老路。
- 当下 AI 应用领域的创业者正在重蹈 AI 研究者过去的覆辙;
- 更强大的 AI 模型将催生通用型 AI 应用,同时也会削弱 AI 模型「套壳」软件的附加价值。
AI 技术的飞速发展带来了一波又一波新产品。在 YC 校友演示日上,我见证了 100 多个创业项目的路演。这些项目都有一个共同点:它们瞄准的都是施加了各种限制和约束的 AI 解决的简单问题。AI 真正的价值在于它能灵活处理各类问题。给 AI 更多自由度通常能带来更好的效果,但现阶段的 AI 模型还不够稳定可靠,所以还无法大规模开发这样的产品。这种情况在 AI 发展史上反复出现过,每次技术突破的路径都惊人地相似。如果创业者们不了解这段历史教训,恐怕要为这些经验「交些学费」。2019 年,AI 研究泰斗 Richard Sutton 在他那篇著名的《苦涩的教训》开篇提到:「70 年的 AI 研究历史告诉我们一个最重要的道理:依靠纯粹算力的通用方法,最终总能以压倒性优势胜出。」这篇文章标题里的「苦涩」二字,正是来自那些精心设计的「专家系统」最终都被纯靠算力支撑的系统打得落花流水。这个剧情在 AI 圈一演再演 —— 从语音识别到计算机象棋,再到计算机视觉,无一例外。如果 Sutton 今天重写《苦涩的教训》,他一定会把最近大火的生成式 AI 也加入这份「打脸清单」,提醒我们:这条铁律还未失效。同在 AI 领域,我们似乎还没有真正吸取教训,因为我们仍在重复同样的错误......我们必须接受这个残酷的现实:在 AI 系统中,强行植入我们认为的思维方式,从长远来看注定失败。这个「苦涩的教训」源于以下观察:4. 真正的突破往往出人意料 —— 就是简单地加大计算规模
站在 AI 研究者的角度,得到了《苦涩的教训》,意味着在总结教训的过程中明确了什么是「更好」的。对于 AI 任务,这很好量化 —— 下象棋就看赢棋概率,语音识别就看准确率。对于本文讨论的 AI 应用产品,「更好」不仅要看技术表现,还要考虑产品性能和市场认可度。从产品性能维度来看,即产品能在多大程度上取代人类的工作。性能越强,就能处理越复杂的任务,创造的价值自然也就越大。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 图 1. 展示了不同类型的 AI 产品,本文主要讨论应用层AI 产品通常是给 AI 模型加一层软件包装。因此,要提升产品性能,有两条路径:2. 模型升级:等待 AI 实验室发布更强大的模型这两条路看似都可行,但在此有个重要洞察:随着模型性能提升,优化工程的价值在不断下降。现阶段,软件端的设计确实能提升产品表现,但这只是因为当前模型还不够完善。随着模型变得更可靠,只需要将模型接入软件就能解决大多数问题了 —— 不需要复杂的的工程。 图 2. 投入工程的价值会随着投入增加和更强大模型的出现而递减。上图展示了一个趋势:随着 AI 模型的进步,工程带来的价值将逐渐减少。虽然当前的模型还有明显不足,企业仍能通过工程投入获得可观回报。这一点在 YC 校友演示日上表现得很明显。创业公司主要分为两类:第一类是已经实现规模化的产品,专注解决简单问题,但数量还不多;第二类则瞄准了相对复杂的问题。后者目前发展势头不错,因为他们的概念验证证明:只要在工程上下足功夫,就能达到预期目标。但这些公司面临一个关键问题:下一个模型发布会不会让所有工程上的都成为无用功,摧毁他们的竞争优势?OpenAI 的 o1 模型发布就很好地说明了这个风险。我和很多 AI 应用层的创业者聊过,他们都很担心,因为他们投入了大量精力来完善提示词。有了 o1 后,提示词工程的重要性就大大降低了。从本质上讲,这种工程的目的是为了约束 AI 少犯错误。通过观察众多产品,可以概括为两类约束:
图 1. 展示了不同类型的 AI 产品,本文主要讨论应用层AI 产品通常是给 AI 模型加一层软件包装。因此,要提升产品性能,有两条路径:2. 模型升级:等待 AI 实验室发布更强大的模型这两条路看似都可行,但在此有个重要洞察:随着模型性能提升,优化工程的价值在不断下降。现阶段,软件端的设计确实能提升产品表现,但这只是因为当前模型还不够完善。随着模型变得更可靠,只需要将模型接入软件就能解决大多数问题了 —— 不需要复杂的的工程。 图 2. 投入工程的价值会随着投入增加和更强大模型的出现而递减。上图展示了一个趋势:随着 AI 模型的进步,工程带来的价值将逐渐减少。虽然当前的模型还有明显不足,企业仍能通过工程投入获得可观回报。这一点在 YC 校友演示日上表现得很明显。创业公司主要分为两类:第一类是已经实现规模化的产品,专注解决简单问题,但数量还不多;第二类则瞄准了相对复杂的问题。后者目前发展势头不错,因为他们的概念验证证明:只要在工程上下足功夫,就能达到预期目标。但这些公司面临一个关键问题:下一个模型发布会不会让所有工程上的都成为无用功,摧毁他们的竞争优势?OpenAI 的 o1 模型发布就很好地说明了这个风险。我和很多 AI 应用层的创业者聊过,他们都很担心,因为他们投入了大量精力来完善提示词。有了 o1 后,提示词工程的重要性就大大降低了。从本质上讲,这种工程的目的是为了约束 AI 少犯错误。通过观察众多产品,可以概括为两类约束:- 专业性:衡量产品的聚焦程度。垂直型产品专注于解决特定领域的问题,配备了专门的软件包装;而水平型产品则更通用,能处理多种不同类型的任务。
- 自主性:衡量 AI 的独立决策能力。在此借鉴一下 Anthropic 的分类:
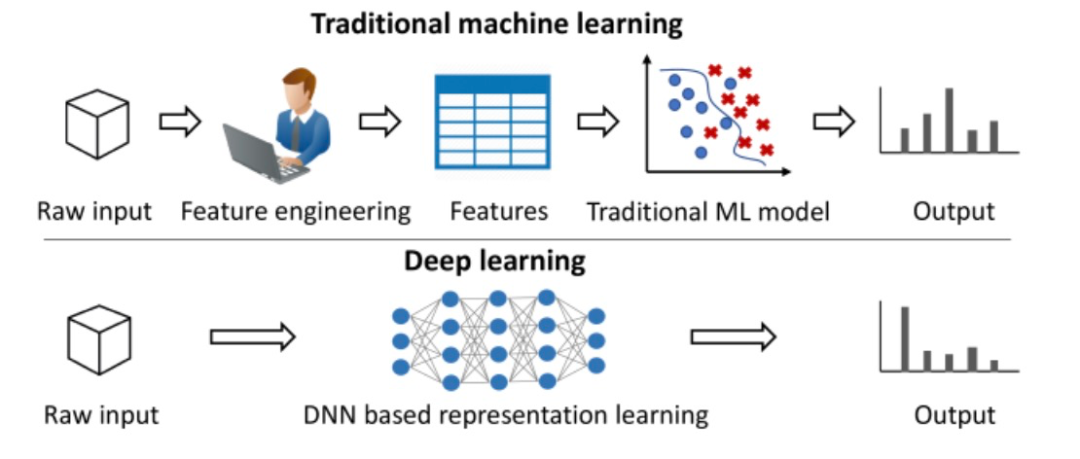
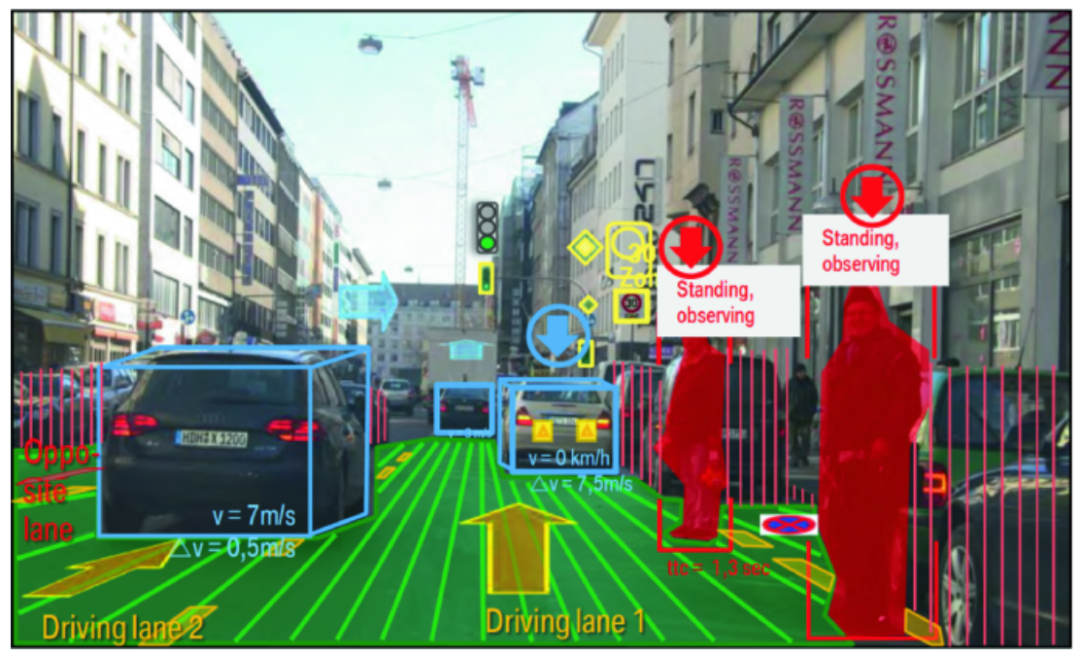
1. 工作流:AI 按预设路径运行,使用固定的工具和流程2. 智能体:AI 可以自主选择工具和方法,灵活决策如何完成任务 表 1. 对知名 AI 产品的分类。需要注意的是,ChatGPT 可能每次对话都会遵循预先设定的代码路径,因此更像工作流而非智能体。以商业分析师制作路演 PPT 为例,看看每类产品如何实现这个任务:
- 垂类工作流:它按固定步骤执行任务,比如,先用 RAG 查询公司数据库,小型 LLM 做总结,大型 LLM 提取关键数据并计算,检查数据合理性后写入幻
 灯片,最后生成演示文稿。每次都严格遵循这个流程。
灯片,最后生成演示文稿。每次都严格遵循这个流程。
- 垂类智能体:LLM 能自主决策,循环工作:用上一步的结果指导下一步行动,虽然可用工具相同,但由 AI 自己决定何时使用。直到达到质量标准才停止。
- 通用工作流:像 ChatGPT 这样的通用工具只能完成部分任务,既不够专业也不够自主,无法完整处理整个工作流程。
- 水平智能体:如 Claude computer-use,能像人一样操作常规办公软件。分析师只需用自然语言下达指令,它就能根据实际情况灵活调整工作方法。
这很好理解 —— 当前的 AI 模型还不够成熟,只能用这种方式才能达到可用水平。结果就是,即使是过于复杂的问题,创业者们也不得不硬塞进这个框架,因为这是目前唯一能让产品勉强可用的方法。虽然通过工程优化可以提升这些产品,但提升空间有限。对于当前模型难以处理的问题,与其投入大量工程资源,不如等待更强大的模型出现 —— 到时只需很少的工程就能解决问题。正如 Leopold Aschenbrenner 在《Situational Awareness》中所指出的:「完善这些繁琐的工程,可能比等待更强大的模型还要耗时。」这不禁让人联想起《苦涩的教训》:AI 研究者反复尝试用工程手段提升性能,最终却总是被简单堆砌算力的通用方案超越。今天的 AI 产品开发似乎正在重蹈覆辙。把表 1 的内容和《苦涩的教训》联系起来之后,这样能更清楚地看到其中的关联:总而言之,我的观点是:试图用软件工程来弥补当前 AI 模型的不足,似乎是一场注定失败的战斗,尤其是考虑到模型进步的惊人速度。正如 YC 合伙人 Jarred 在 Lightcone 播客中所说:「第一波基于固定流程的 AI 应用,大多被新一代 GPT 模型淹没了。」Sam Altman 常说,要打造那种期待而不是害怕新模型发布的创业公司。我遇到的很多 AI 创业者对新模型都很兴奋,但从他们公司的利益看,这种兴奋可能不太合适。让我们用简单的统计学来理解这个道理。在做模型时,通常要面临一个选择:要么做一个规则很死板的模型(高偏差),要么做一个灵活但不太稳定的模型(高方差)。《苦涩的教训》告诉我们:选灵活的。究其原因,因为只要有足够的算力和数据,灵活的模型最终也能变得很稳定。就像打篮球,就算姿势不标准,练得多了也能投准。但反过来就不行了,太死板的方法会被自己的规则限制住。这跟 AI 产品是一个道理。做垂直领域的工具,加各种限制,就像给 AI 加规则,现在看起来更稳定,但限制了它的潜力。相反,让 AI 更自由一点虽然现在看着不太靠谱,但随着模型越来越强,它反而能找到更好的办法。历史一再证明,跟灵活性对着干是不明智的。 图 1:对比了两种方法。传统机器学习需要人工来告诉机器「什么是重要的」,深度学习则能自己学会。传统机器学习需要人来决定什么信息重要。比如给一张图片,你得手动找出有用的特征,数一数有多少个圆形,测量一下各种尺寸等等。但深度学习不同,它能自己学会找重要的东西。 图 2:比如自动驾驶。系统要识别和跟踪车辆、行人、车道线等具体物体。这就是分解复杂问题的传统方法。1. 老方法:把车看到的东西分解:前面的车在哪,车道线在哪,那个人跑多快?2. 新方法:直接把视频扔给 AI,让它自己学会开车。老方法看着更靠谱,更有把握。所以早期的 AI 都这么干。但正如 George Hotz 所说:「AI 的历史告诉我们,老方法最后总会被新方法打败。」 图 3:DeepMind 研究员 Sholto Douglas:就像其他所有深度学习系统一样,押注端到端就对了博客作者为 Lukas Petersson。今年 26 岁的他于去年从隆德大学毕业,拿下了工程物理和数学双硕士学位。现在他是 Andon Labs 的 CEO 兼联合创始人,专注 AI 安全评估和大语言模型研究。此前,他曾在 Google 实习,曾在 Disney Research 开发病毒式机器人,还曾参与探空火箭发射项目,担任项目主要负责人。https://x.com/dotey/status/1878595515924820420https://lukaspetersson.com/blog/2025/bitter-vertical/以上就是70年AI研究得出了《苦涩的教训》:为什么说AI创业也在重复其中的错误?的详细内容,更多请关注其它相关文章!
# qq
# 两种
# 不太
# 就像
# 很好
# 更强大
# 工作流
# 一言
# 就能
# 2025
# red
# 为什么
# claude
# chatgpt
# ai
# 产业
# type
# 平潭平台推广营销咋样啊
# 吉林seo网络推广招聘
# 武汉seo推广和营销
# 江门抖音seo服务
# 为网站建设提供帮助
# 厦门网站建设美丽中国
# 福建seo专员
# 内容营销推广有哪些网站
# 景德镇网络营销推广优化
# 如何制作网站内部优化
# 告诉我们
# 软件工程
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
山东机器人编程:Scratch编程基础,认识舞台!~济南机器人编程
自己动手使用AI技术实现数字内容生产
RoboNeo什么时候上线
谷歌AudioPaLM实现「文本+音频」双模态解决,说听两用大模型
Bing 聊天机器人现支持在桌面端用语音提问
12页线性代数笔记登GitHub热榜,还获得了Gilbert Strang大神亲笔题词
当人工智能开始写高考作文?作家陈崇正、朱山坡谈文学与未来
陈丹琦ACL学术报告来了!详解大模型「*」数据库7大方向3大挑战,3小时干货满满
马斯克发推讽刺人工智能,机器学习本质是统计?
遵义市首次引入手术机器人,成功实施全膝关节置换术
人工智能领域,突破难题:国产大模型“无源之水”问题得到解决。
“三夏”农忙保障用电,无人机高空巡视高压线
张朝阳与陆川谈AI:ChatGPT是鹦鹉学舌思维,不可能取代人类 | 把脉AI大模型
微软宣布为 Azure AI 添加男性声线,增强文本转语音功能
苹果AIGC专利:可通过语音指令生成AR/VR虚拟场景
人工智能时代 数字文明对话向“尼”走来
AI成政客博弈工具,美国大选真假难辨,律师们的生意来了
1.6亿美元收购Singularity AI,昆仑万维布局通用人工智能
美图秀秀发布7款AI产品:支持用户创作、商业创作
大模型训练成本降低近一半!新加坡国立大学最新优化器已投入使用
利用AI探索抗体“钥匙”、加速药物研发——访百图生科团队
统信深度deepin成立 AI SIG 社区,共同提升 Linux 下 AI 体验
有 ARM 和 X86 两个版本,香橙派游戏掌机细节曝光
13 个提高生产力的 AI 工具
云深处与昇腾CANN携手合作:开设ROS四足机器狗开发训练营
最大助力35公斤 外骨骼机器人或在养老、医疗领域“大展身手”
学而思推出AI第一课:基于自研大模型的AIGC课程
650亿参数,8块GPU就能全参数微调:邱锡鹏团队把大模型门槛打下来了
6月14日《星空下的对话》 张朝阳陆川将畅聊人生、电影、心理学与AI
湖北科技职业学院举行工业机器人及智能制造技术专精特新产业学院建设启动仪式
实现人工智能和物联网的协同运作
厂商陆续公布AI进展 完美世界游戏展示复合应用AI in GamePlay
谷歌在人工智能领域没有“护城河”?
用AI升级会议体验!思必驰多款会议产品亮相全球智博会!
PHP和OpenCV库:如何实现人脸识别
三个全球首创,青岛西海岸新区“海元宇宙”亮相世界人工智能大会
生成式AI爆发,亚马逊云科技持续专注创新,助力企业数字化转型
AI进军债券交易,BondGPT来了!
Win11 的画图应用将包含 Windows Copilot 的 AI 工具整合
学生作文评分的新趋势:教师与AI的合作模式
Snow Kylin登陆中国列车,打造全球首条元宇宙专列
官宣!爱康AI未来之夜三大亮点提前剧透!
周鸿祎:360智脑开放API接口 AI大模型将赋能百行千业
无人机在电力巡检中的应用:全面解析高效巡检流程
视觉中国推出AI灵感绘图功能,付费后可在“合法合规前提下使用”
建立元宇宙产业联盟:移动、咪咕、华为、小米等加入
智能电网技术:提高能源效率和可靠性
OpenAI大神Karpathy最新分享:为什么OpenAI内部对AI Agents最感兴趣
人工智能加速走进百姓生活:从2025全球人工智能技术大会看行业新趋势
陈根:ChatGPT和人类合作开发机器人
2025-02-06



 灯片,最后生成演示文稿。每次都严格遵循这个流程。
灯片,最后生成演示文稿。每次都严格遵循这个流程。