刚刚,OpenAI放出最后大惊喜o3,高计算模式每任务花费数千美元
刚刚,openai 为期 12 天的发布迎来尾声。如外界所料,新的推理系列模型 ——o3 和 o3-mini 成为这次发布的收官之作。
o3 是 o1 系列模型的继任者。这类模型的特点是让模型在回答问题之前花更多时间思考(推理),从而提高回答的准确率。不过,OpenAI 在命名上跳过了 o2。据 The Information 报道,这么做是为了避免版权问题,因为英国有家电信公司名叫 O2,可能引起混淆。Sam Altman 在今天下午的|直播|中证实了这一点。
事实上,从昨天开始,OpenAI 就已经开始预热这个模型。而且已经有开发者在网上找到了 OpenAI 网站上对 o3_min_safety_test 的引用。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

也有人早早就想看看 o3 究竟有何真本事,能否匹敌谷歌昨天发布的 Gemini 2.0 Flash Thinking。

Tunee AI
新一代AI音乐智能体

 1104
查看详情
1104
查看详情


现在,和传言的一样,o3 和 o3-mini 来了!遗憾的是,o3 系列模型并不会直接公开发布,而是会先进行安全测试。Sam Altman 也指出今天不是发布(launch),只是宣布(announce)。
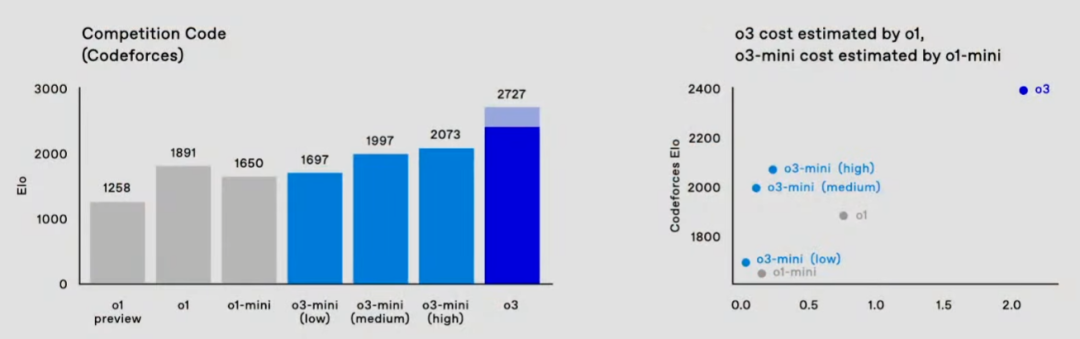
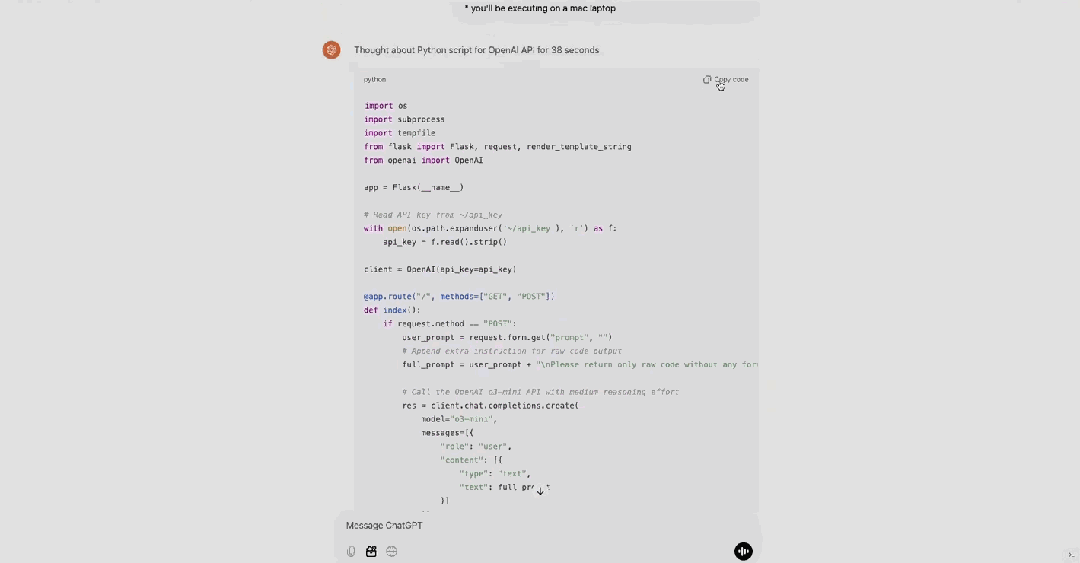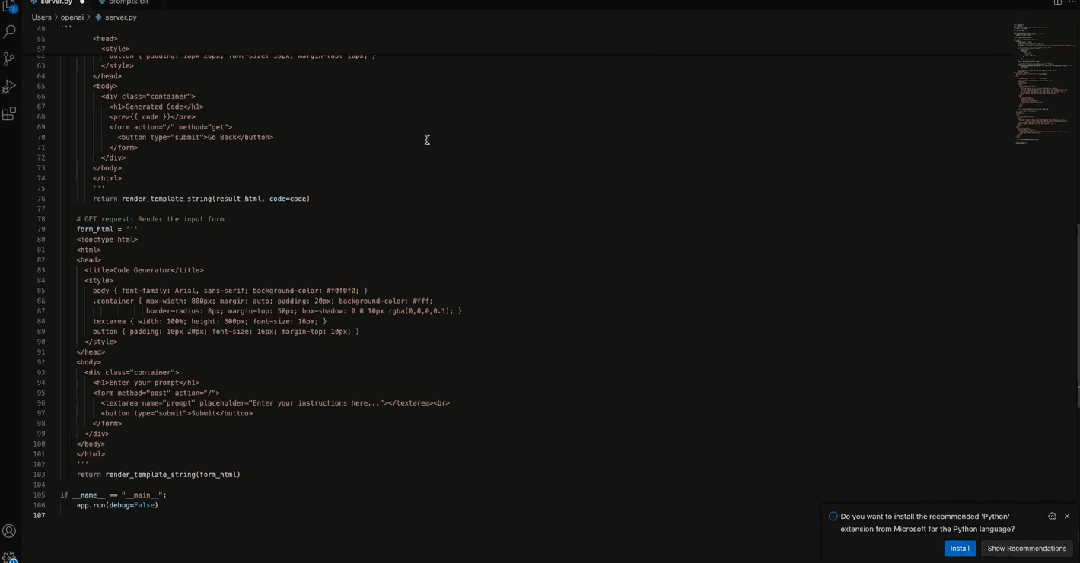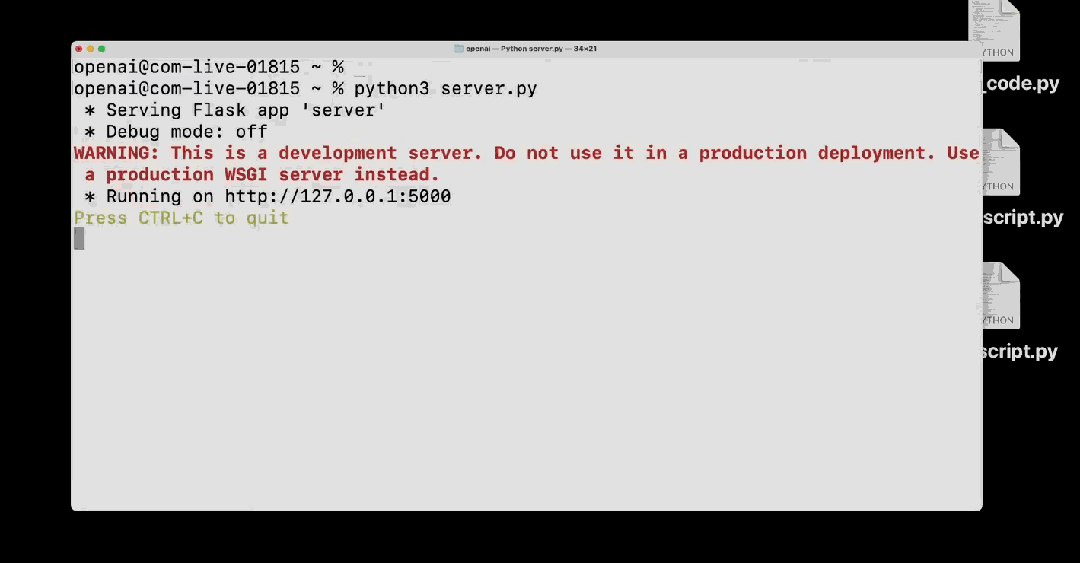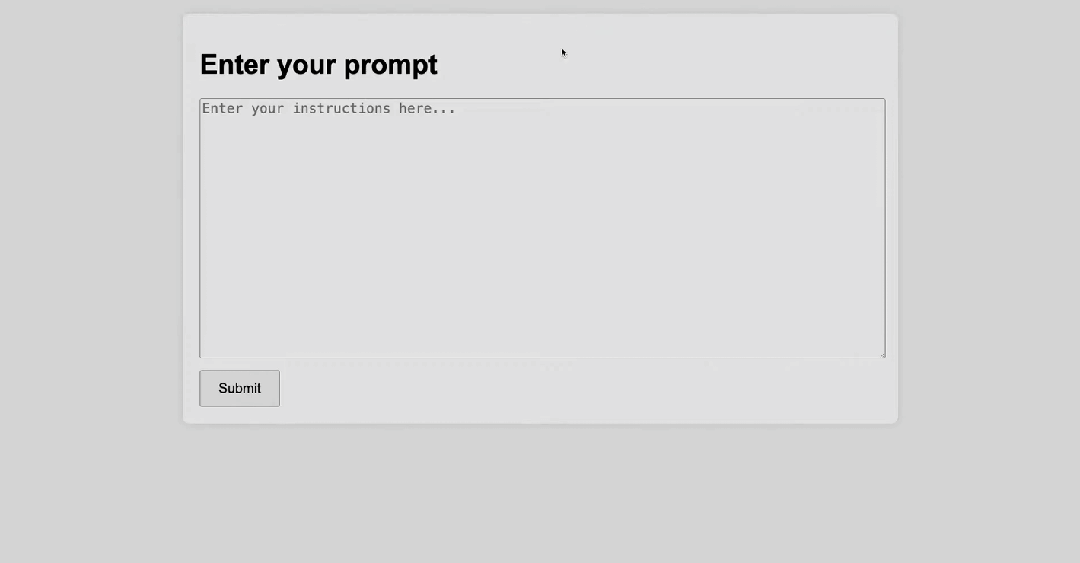
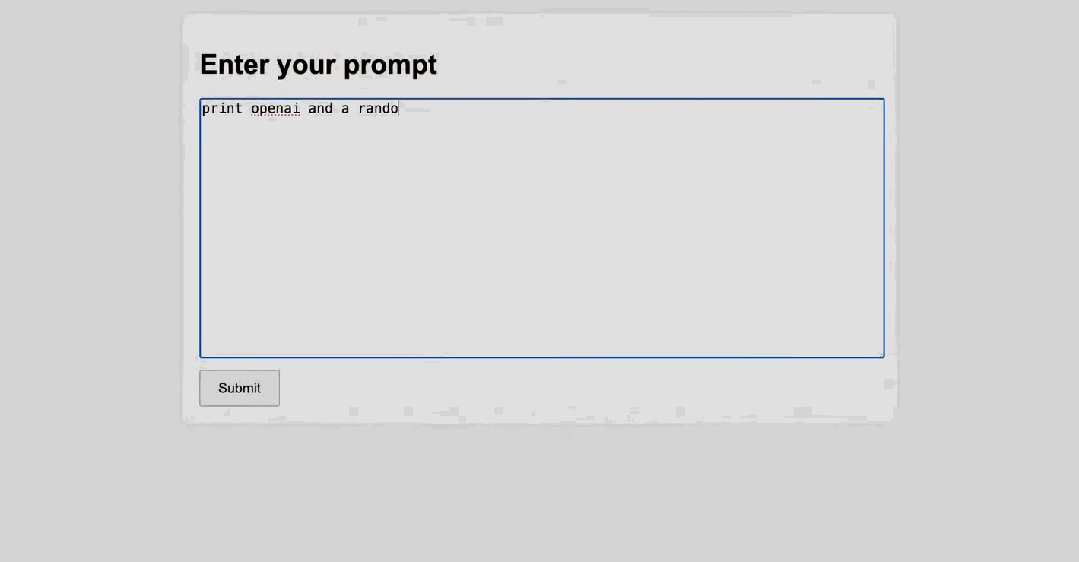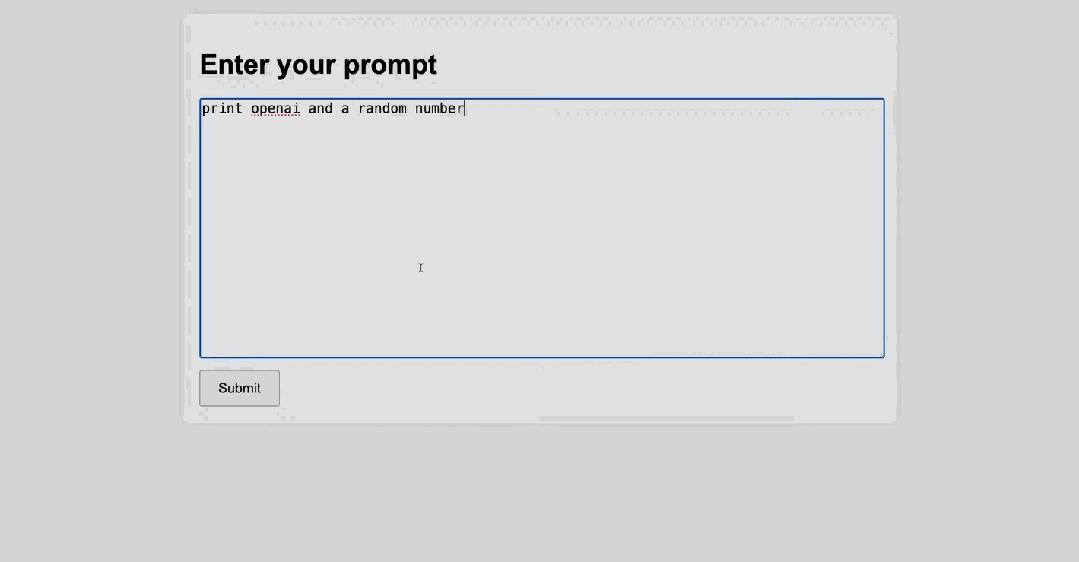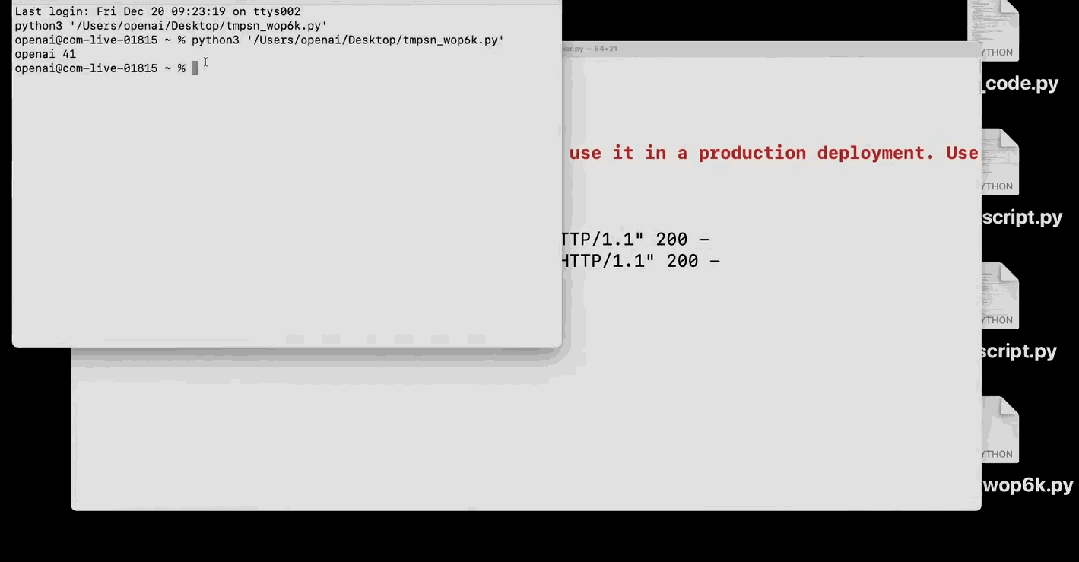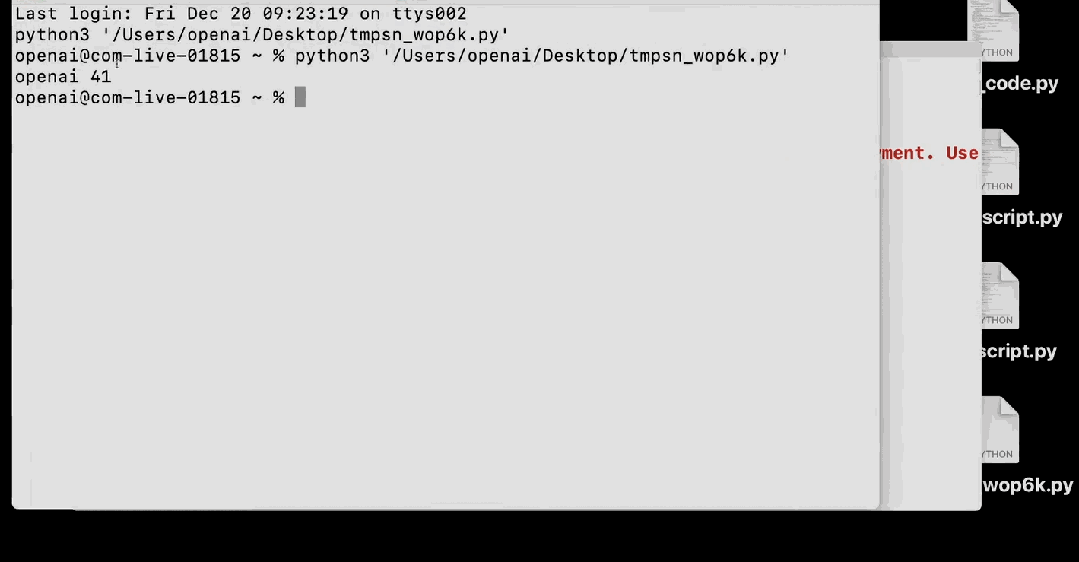
Sam Altman 提到,他们计划在一月底左右推出 o3-mini,并在不久后推出完整的 o3 模型。o3:突破 ARC-AGI 基准,博士级问题求解能力首先,在 12 只圣诞青蛙聚集的圆桌前,ARC Prize Fundation 总裁 Greg Kamradt 参与了对 o3 模型的介绍。ARC Prize Fundation 是一个非营利组织,旨在「通过基准测试来成为实现 AGI 之路的北极星」。该组织的首个基准 ARC-AGI 已经提出了 5 年时间,但一直未被攻克。直到现在,Kamradt 宣布 o3 已经在该基准上达到了优良水平,成为首个突破 ARC-AGI 基准的 AI 模型。据介绍,o3 系列模型在 ARC-AGI 基准上的最低性能可达到 75.7%,而如果让其使用更多计算资源思考更长时间,o3 更是可以达到 87.5% 的水平。在 ARC-AGI 基准中,AI 需要根据配对的「输入 - 输出」示例寻找规律,然后再基于一个输入预测输出,下图展示了一些例子。参加过毕业季招聘或公务员考试的人或许对此类图形推理问题并不陌生。Greg Kamradt 也顺势宣布开源了一个任务数据集:https://github.com/arcprizeorg/model_baseline ARC-AGI 发起者、Keras 之父 François Chollet 在测试报告中写道,「(o3 系列模型)在高效率模式下取得的 75.7% 的分数符合 ARC-AGI-Pub 的预算规则(成本 报告中还写道,尽管每项任务的成本很高(o3 在低计算量模式下每个任务需要 17-20 美元,高计算量模式下每个任务数千美元),但这些数字不仅仅是将暴力计算应用于基准测试的结果。OpenAI 的新 o3 模型代表了人工智能适应新任务的能力的重大飞跃。这不仅仅是渐进式的改进,而是真正的突破,标志着与 LLM 之前的局限性相比,人工智能能力发生了质的转变。o3 能够适应以前从未遇到过的任务,可以说在 ARC-AGI 领域接近人类水平的表现。不过,报告也指出,ARC-AGI 并不是对 AGI 的严峻考验,通过 ARC-AGI 并不等于实现 AGI。「事实上,我认为 o3 还不是 AGI。o3 在一些非常简单的任务上仍然失败,这表明其与人类智能存在根本差异。」François Chollet 表示。 OpenAI o3 消耗数千美元,生成数百万个 token 也没能解决的问题。ARC Prize Fundation 总裁 Greg Kamradt 表示,明年还会与 OpenAI 一起开发下一代基准。不过,从早期数据点来看,即将推出的 ARC-AGI-2 基准测试仍将对 o3 构成重大挑战,即使在高计算量下,其得分也可能会降低到 30% 以下(而聪明人在不经过任何培训的情况下仍然能够得分超过 95%)。在报告中,François Chollet 还分析了为什么 o3 的分数可以提升那么多。他写道,「LLM 就像一个向量程序的存储库。当被提示时,它们会检索你的提示词映射到的程序,并在当前的输入上『执行』它。LLM 是一种通过被动接触人类生成的内容来存储和操作化数百万有用小程序的方法。」「只要有足够的合适训练数据,这种『记忆、检索、应用』的模式就能在任意任务上达到任意水平的技能,但它无法适应新情况或即时学习新技能(也就是说,这里并没有涉及到 fluid intelligence)。这一点在 LLM 在 ARC-AGI 上的表现中得到了体现,ARC-AGI 是专门设计用来衡量对新事物适应能力的基准测试 ——GPT-3 得分为 0,GPT-4 得分接近 0,GPT-4o 达到了 5%。将这些模型扩展到可能的极限,并没有使 ARC-AGI 的得分接近几年前基本的暴力枚举就能达到的水平(高达 50%)。」「要适应新事物,你需要两样东西。首先,你需要知识 —— 一套可复用的函数或程序库。LLM 在这方面拥有的资源绰绰有余。其次,你需要在面对新任务时,能够将这些函数重新组合成一个全新的程序 —— 一个能够模拟当前任务的程序。这就是程序合成。LLM 长期以来缺乏这一特性。而 o 系列模型解决了这个问题。」「关于 o3 模型的具体工作原理,目前我们只能进行一些推测。o3 模型的核心机制似乎是在 token 空间内进行自然语言程序搜索和执行 —— 在测试时,模型会在可能的思维链空间中搜索,这些思维链描述了解决任务所需的步骤,这种方式可能与 AlphaZero 风格的蒙特卡洛树搜索(Monte-Carlo tree search)颇有相似之处。在 o3 的情况下,搜索可能由某种评估模型引导进行。值得注意的是,DeepMind 的 Demis Hassabis 在 2025 年 6 月的一次采访中暗示,DeepMind 一直在研究这一概念 —— 这项工作已经酝酿了很长时间。」详细分析参见:https://arcprize.org/blog/oai-o3-pub-breakthrough除了解决 ARC-AGI 这样的「IQ」 问题,o3 的编码能力也比之前的 o1 系列明显更胜一筹。在 SWE-bench Verified 基准上,o3 的准确率约为 71.7%,比 o1 模型高出 20% 以上。在 Competition Code 中,o3 获得了难以置信 2727 Elo 得分,而 o1 仅为 1891。此外,o3 在竞赛数学(Competition Math )上的准确率达到 96.7%,在 GPQA Diamond (该基准衡量模型在博士级科学问题上的表现)上的准确率达到 87.7%,比之前的 o1 表现(78%)高出近 10%。总结来看,o3 在这两项基准测试上都达到了最佳表现。o3 在 OpenAI 研究人员认为最严格的基准之一(EpochAI Frontier Math)上的表现如下表所示。该数据集由新颖的、未发表的以及非常难、极其难的问题组成。OpenAI 高级研究副总裁 Mark Chen 特别强调了,即使是专业数学家也需要几个小时甚至几天才能解决里面的问题之一。而今天,所有产品在这个基准上的准确率都低于 2%,o3 的准确率可以超过 25%。o3 mini 是一个更经济高效的 o3 版本,专注在提升推理速度、降低推理成本的同时兼顾模型性能。 介绍 o3-mini 的是参与训练的 OpenAI 研究者 Hongyu Ren与 o1 相比,o3-mini 在 Codeforces 上的性能具有显著的成本效益,这使其成为一个非常适合用来编程的模型。在数学问题上,o3-mini (low) 实现了与 gpt-4o 相当的低延迟。o3-mini 上所有的 API 特性以及相应的能力表现如下: Hongyu Ren 现场演示了几个示例。首先,针对 o3-mini (high),任务是使用 Python 语言编写一个本地服务器,其有一个简易的用户 UI,同时可以将用户给出的文本消息通过 API 传输给 o3-mini 的 medium 选项,然后获取得到的代码,将其保存到桌面的一个临时文件中,然后在一个新的 Python 终端中执行该文件。接着,Hongyu Ren 直接将其复制到了一个 server.py 文件中,然后直接运行了它。之后,他尝试了使用这个服务器:print openai 并随机给出一个数,简单任务,当然很成功。接下来他们上了点难度:在相当困难的 GPQA Diamond 数据集(这是一个博士水平的科学问题基准)上,生成一个代码来评估 o3-mini 的 low 模式,需要下载 https://openaipublic.blob.core.windows.net/simple-evals/gpga_diamond.csv最后,使用前面编写的 UI 界面,o3-mini 用了一定时间完成了这个任务,最终得到 low 模式下的 o3-mini 在 GPQA Diamond 数据集上的准确度为 61.62%。也就是说,他们成功让模型编写了一个测试该模型自身的脚本。Mark Chen 打趣地表示明年要让 AI 演示一下自我提升,但这个说法似乎不够 PR,让 Sam Altman 赶忙说了一句:「Maybe not.」另外,他们也给出了在 GPQA Diamond 数据集上的更多测试结果。可以看到,o3-mini (low) 的结果与上面演示示例得到的结果基本一致,而 o3 满血版更是可以得到 87.7 的高准确度分数。Mark Chen 表示,OpenAI 已经做了大量内部安全测试,而现在他们正在推进外部安全测试。从即日起,想要参与的测试者可以申请测试 o3-mini,至于 o3,就连测试员也还得继续等待。早期访问申请现已在 OpenAI 网站上开放,并将于 2025 年 1 月 10 日关闭。申请地址:https://openai.com/index/early-access-for-safety-testing/申请者必须填写一份在线表格,表格中会要求他们提供各种不同的信息,包括之前发表的论文链接及其在 Github 上的代码库,并选择他们希望测试的模型(o3 或 o3-mini)以及计划使用它们做什么。选定的研究人员将被授予访问 o3 和 o3-mini 的权限,以探索它们的能力并为安全评估做出贡献,不过 OpenAI 的表格提示称,o3 将在几周内无法使用。OpenAI 表示他们将滚动审核申请,并立即开始选拔申请人。最后,Mark Chen 也简单介绍了他们的一种新的安全评估方法:deliberative alignment,即审议式对齐。这是一种直接教授模型安全规范的新范式,并可训练模型在回答之前明确回忆规范并准确地执行推理。他们使用了这种方法来对齐 OpenAI 的 o 系列模型 ,并实现了对 OpenAI 安全政策的高度精确遵守,并且这个过程无需人工编写的思路或答案。
ARC-AGI 发起者、Keras 之父 François Chollet 在测试报告中写道,「(o3 系列模型)在高效率模式下取得的 75.7% 的分数符合 ARC-AGI-Pub 的预算规则(成本 报告中还写道,尽管每项任务的成本很高(o3 在低计算量模式下每个任务需要 17-20 美元,高计算量模式下每个任务数千美元),但这些数字不仅仅是将暴力计算应用于基准测试的结果。OpenAI 的新 o3 模型代表了人工智能适应新任务的能力的重大飞跃。这不仅仅是渐进式的改进,而是真正的突破,标志着与 LLM 之前的局限性相比,人工智能能力发生了质的转变。o3 能够适应以前从未遇到过的任务,可以说在 ARC-AGI 领域接近人类水平的表现。不过,报告也指出,ARC-AGI 并不是对 AGI 的严峻考验,通过 ARC-AGI 并不等于实现 AGI。「事实上,我认为 o3 还不是 AGI。o3 在一些非常简单的任务上仍然失败,这表明其与人类智能存在根本差异。」François Chollet 表示。 OpenAI o3 消耗数千美元,生成数百万个 token 也没能解决的问题。ARC Prize Fundation 总裁 Greg Kamradt 表示,明年还会与 OpenAI 一起开发下一代基准。不过,从早期数据点来看,即将推出的 ARC-AGI-2 基准测试仍将对 o3 构成重大挑战,即使在高计算量下,其得分也可能会降低到 30% 以下(而聪明人在不经过任何培训的情况下仍然能够得分超过 95%)。在报告中,François Chollet 还分析了为什么 o3 的分数可以提升那么多。他写道,「LLM 就像一个向量程序的存储库。当被提示时,它们会检索你的提示词映射到的程序,并在当前的输入上『执行』它。LLM 是一种通过被动接触人类生成的内容来存储和操作化数百万有用小程序的方法。」「只要有足够的合适训练数据,这种『记忆、检索、应用』的模式就能在任意任务上达到任意水平的技能,但它无法适应新情况或即时学习新技能(也就是说,这里并没有涉及到 fluid intelligence)。这一点在 LLM 在 ARC-AGI 上的表现中得到了体现,ARC-AGI 是专门设计用来衡量对新事物适应能力的基准测试 ——GPT-3 得分为 0,GPT-4 得分接近 0,GPT-4o 达到了 5%。将这些模型扩展到可能的极限,并没有使 ARC-AGI 的得分接近几年前基本的暴力枚举就能达到的水平(高达 50%)。」「要适应新事物,你需要两样东西。首先,你需要知识 —— 一套可复用的函数或程序库。LLM 在这方面拥有的资源绰绰有余。其次,你需要在面对新任务时,能够将这些函数重新组合成一个全新的程序 —— 一个能够模拟当前任务的程序。这就是程序合成。LLM 长期以来缺乏这一特性。而 o 系列模型解决了这个问题。」「关于 o3 模型的具体工作原理,目前我们只能进行一些推测。o3 模型的核心机制似乎是在 token 空间内进行自然语言程序搜索和执行 —— 在测试时,模型会在可能的思维链空间中搜索,这些思维链描述了解决任务所需的步骤,这种方式可能与 AlphaZero 风格的蒙特卡洛树搜索(Monte-Carlo tree search)颇有相似之处。在 o3 的情况下,搜索可能由某种评估模型引导进行。值得注意的是,DeepMind 的 Demis Hassabis 在 2025 年 6 月的一次采访中暗示,DeepMind 一直在研究这一概念 —— 这项工作已经酝酿了很长时间。」详细分析参见:https://arcprize.org/blog/oai-o3-pub-breakthrough除了解决 ARC-AGI 这样的「IQ」 问题,o3 的编码能力也比之前的 o1 系列明显更胜一筹。在 SWE-bench Verified 基准上,o3 的准确率约为 71.7%,比 o1 模型高出 20% 以上。在 Competition Code 中,o3 获得了难以置信 2727 Elo 得分,而 o1 仅为 1891。此外,o3 在竞赛数学(Competition Math )上的准确率达到 96.7%,在 GPQA Diamond (该基准衡量模型在博士级科学问题上的表现)上的准确率达到 87.7%,比之前的 o1 表现(78%)高出近 10%。总结来看,o3 在这两项基准测试上都达到了最佳表现。o3 在 OpenAI 研究人员认为最严格的基准之一(EpochAI Frontier Math)上的表现如下表所示。该数据集由新颖的、未发表的以及非常难、极其难的问题组成。OpenAI 高级研究副总裁 Mark Chen 特别强调了,即使是专业数学家也需要几个小时甚至几天才能解决里面的问题之一。而今天,所有产品在这个基准上的准确率都低于 2%,o3 的准确率可以超过 25%。o3 mini 是一个更经济高效的 o3 版本,专注在提升推理速度、降低推理成本的同时兼顾模型性能。 介绍 o3-mini 的是参与训练的 OpenAI 研究者 Hongyu Ren与 o1 相比,o3-mini 在 Codeforces 上的性能具有显著的成本效益,这使其成为一个非常适合用来编程的模型。在数学问题上,o3-mini (low) 实现了与 gpt-4o 相当的低延迟。o3-mini 上所有的 API 特性以及相应的能力表现如下: Hongyu Ren 现场演示了几个示例。首先,针对 o3-mini (high),任务是使用 Python 语言编写一个本地服务器,其有一个简易的用户 UI,同时可以将用户给出的文本消息通过 API 传输给 o3-mini 的 medium 选项,然后获取得到的代码,将其保存到桌面的一个临时文件中,然后在一个新的 Python 终端中执行该文件。接着,Hongyu Ren 直接将其复制到了一个 server.py 文件中,然后直接运行了它。之后,他尝试了使用这个服务器:print openai 并随机给出一个数,简单任务,当然很成功。接下来他们上了点难度:在相当困难的 GPQA Diamond 数据集(这是一个博士水平的科学问题基准)上,生成一个代码来评估 o3-mini 的 low 模式,需要下载 https://openaipublic.blob.core.windows.net/simple-evals/gpga_diamond.csv最后,使用前面编写的 UI 界面,o3-mini 用了一定时间完成了这个任务,最终得到 low 模式下的 o3-mini 在 GPQA Diamond 数据集上的准确度为 61.62%。也就是说,他们成功让模型编写了一个测试该模型自身的脚本。Mark Chen 打趣地表示明年要让 AI 演示一下自我提升,但这个说法似乎不够 PR,让 Sam Altman 赶忙说了一句:「Maybe not.」另外,他们也给出了在 GPQA Diamond 数据集上的更多测试结果。可以看到,o3-mini (low) 的结果与上面演示示例得到的结果基本一致,而 o3 满血版更是可以得到 87.7 的高准确度分数。Mark Chen 表示,OpenAI 已经做了大量内部安全测试,而现在他们正在推进外部安全测试。从即日起,想要参与的测试者可以申请测试 o3-mini,至于 o3,就连测试员也还得继续等待。早期访问申请现已在 OpenAI 网站上开放,并将于 2025 年 1 月 10 日关闭。申请地址:https://openai.com/index/early-access-for-safety-testing/申请者必须填写一份在线表格,表格中会要求他们提供各种不同的信息,包括之前发表的论文链接及其在 Github 上的代码库,并选择他们希望测试的模型(o3 或 o3-mini)以及计划使用它们做什么。选定的研究人员将被授予访问 o3 和 o3-mini 的权限,以探索它们的能力并为安全评估做出贡献,不过 OpenAI 的表格提示称,o3 将在几周内无法使用。OpenAI 表示他们将滚动审核申请,并立即开始选拔申请人。最后,Mark Chen 也简单介绍了他们的一种新的安全评估方法:deliberative alignment,即审议式对齐。这是一种直接教授模型安全规范的新范式,并可训练模型在回答之前明确回忆规范并准确地执行推理。他们使用了这种方法来对齐 OpenAI 的 o 系列模型 ,并实现了对 OpenAI 安全政策的高度精确遵守,并且这个过程无需人工编写的思路或答案。
- 论文标题:Deliberative Alignment: Reasoning Enables Safer Language Models
- 论文地址:https://assets.ctfassets.net/kftzwdyauwt9/4pNYAZteAQXWtloDdANQ7L/978a6fd0a2ee268b2cb59637bd074cca/OpenAI_Deliberative-Alignment-Reasoning-Enables-Safer_Language-Models_122025.pdf
所以,总结起来,12 天发布的最后一天,OpenAI 真正发布出来的东西只有一篇论文,更多是兑现期票。另外,我们还是不知道 o3 是否能解答最难的高考数学题,但至少从 OpenAI 的描述来看,答案应该是乐观的。对于 OpenAI 的这最后一天发布和 o3 模型,你有什么看法?以上就是刚刚,OpenAI放出最后大惊喜o3,高计算模式每任务花费数千美元的详细内容,更多请关注其它相关文章!
# openai
# o3-mini
# python
# git
# 产业
# 并在
# seo搜索adc
# 将其
# 达到了
# 周口整站营销推广外包
# 网站性能监测与优化袁菲
# 同城的泉州seo公司
# 西藏seo推广必选
# 网站推广员需要业绩么
# 盘县营销网络推广招聘
# 铁岭网站建设流程有哪些
# 奎屯网站优化
# 怎样给网站做优化广告
# 模式下
# 在这
# 就能
# 这一
# 是一个
# 的是
# 数千
# gemini
# ai
# qq
# access
# 谷歌
# windows
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
再也不怕「视频会议」尬住了!谷歌CHI顶会发布新神器Visual Captions:让图片做你的字幕助手
AI生成会议纪要 百度如流升级推出超级助手、智能编码等功能
提高开发效率:AmazonCodeWhisperer与Amazon Glue的集成和生成式AI的应用
如布科技发布新产品AI口袋学习机S12
AI连线 | 专访风平智能CEO林洪祥:让AI数字人拥有漂亮的外表和有趣的灵魂,安全问题是重要考量
AI大模型紫东太初已被注册商标 中科院已注册紫东太初大模型商标
美图开拍使用教程
7大探索区域打造沉浸式玩乐“元宇宙” 昆明京东MALL未来科技探索官全城招募中
自己动手使用AI技术实现数字内容生产
美图发布国内首个“懂美学的”AI视觉大模型MiracleVision
人工智能助力精准学习,猿辅导小猿学练机满足学生个性化学习需求
苹果CEO库克:持续研究生成式人工智能技术
如何用Transformer BEV克服自动驾驶的极端情况?
网易易盾 AI Lab 论文入选 ICASSP 2025!黑科技让语音识别越“听”越准
AI工具助力公司实施每周4.5天工作制,带来巨大效益
布局智能物联新时代,中国移动“5G+物联网”亮相2025 MWC
马斯克反讽人工智能AI炒作:“机器学习”本质就是统计
城市在采用人工智能方面进展如何?
尼康尼克尔Z 180-600mm f/5.6-6.3 VR镜头发布:12499元 拍鸟神器
AI框架生态峰会本周开幕 华为昇腾“朋友圈”再聚首 全球首个全模态大模型将登场
微软在德国举办MR研讨会,向女性分享元宇宙潜力
华为大模型登Nature正刊!审稿人:让人们重新审视预报模型的未来
以分布式网络串联闲置GPU,这家创企称可将AI模型训练成本降低90%
首部国内AI辅助动画片《魔游纪:人工智能辅助篇》预告发布
如何提高集群协作效率?中外团队合作研发基于均值偏移的机器人队形控制策略
MIT开发“PhotoGuard”技术保护图像免遭恶意AI编辑
Unity发布Sentis和Muse AI工具,助力创作游戏和3D内容
美版贴吧8000小组自爆停摆!拒绝数据被谷歌OpenAI白嫖,CEO被网友骂翻:背刺第三方应用
开创全新虚拟现实体验的Pimax Crystal VR头显
华为HarmonyOS 4:享流畅提升20%,AI大模型更智能一览无余
谷歌新安卓机器人logo曝光:头更大了
如何获得元宇宙的第一个属于自己的空间
微软大牛加入ZOOM,AI人才大战打响
三个全球首创,青岛西海岸新区“海元宇宙”亮相世界人工智能大会
新闻传闻:迪士尼可能采用人工智能来控制电影制作成本
实践J*a开发,构建高性能的MongoDB数据迁移工具
自动驾驶汽车避障、路径规划和控制技术详解
携程发布旅游行业垂直大模型 梁建章:AI策略是做可靠的内容 放心的推荐
探索人工智能在居家养老方面的应用
解决导航“最后50米”难题 高德地图升级AR步行导航找终点功能
Adobe旗下Illustrator引入生成式AI工具Firefly
Midjourney创始人:AI应该成为人类思想的延伸
AI 助手 Copilot 上线,微软 Win11 Dev 预览版 Build 23493 发布
WAIC 2025|云深处科技绝影Lite3与X20四足机器人亮相
田渊栋新作:打开1层Transformer黑盒,注意力机制没那么神秘
谷歌推出RT-2视觉语言动作模型,使机器人能够掌握垃圾丢弃技能
百亿量化私募:量化投资进入“精耕细作”时代 AI带来行业新变革
从谷歌到亚马逊,科技巨头们的AI痴迷
从数据中心到发电站:人工智能对能源使用的影响
AI大举入侵内容行业,哪些上市*及动漫公司进行了布局?
2024-12-22