几个月前,来自 KAUST(沙特阿卜杜拉国王科技大学)的几位研究者提出了一个名为 MiniGPT-4 的项目,它能提供类似 GPT-4 的图像理解与对话能力。
例如 MiniGPT-4 能够回答下图中出现的景象:「图片描述的是生长在冰冻湖上的一株仙人掌。仙人掌周围有巨大的冰晶,远处还有白雪皑皑的山峰……」假如你接着询问这种景象能够发生在现实世界中吗?MiniGPT-4 给出的回答是这张图片在现实世界中并不常见,并给出了原因。

短短几个月过去了,近日,KAUST 团队以及来自 Meta 的研究者宣布,他们将 MiniGPT-4 重磅升级到了 MiniGPT-v2 版本。

论文地址:https://arxiv.org/pdf/2310.09478.pdf
论文主页:https://minigpt-v2.github.io/
Demo: https://minigpt-v2.github.io/
 Voicepods
Voicepods
Voicepods是一个在线文本转语音平台,允许用户在30秒内将任何书面文本转换为音频文件。
 142
查看详情
142
查看详情

具体而言,MiniGPT-v2 可以作为一个统一的接口来更好地处理各种视觉 - 语言任务。同时,本文建议在训练模型时对不同的任务使用唯一的识别符号,这些识别符号有利于模型轻松的区分每个任务指令,并提高每个任务模型的学习效率。
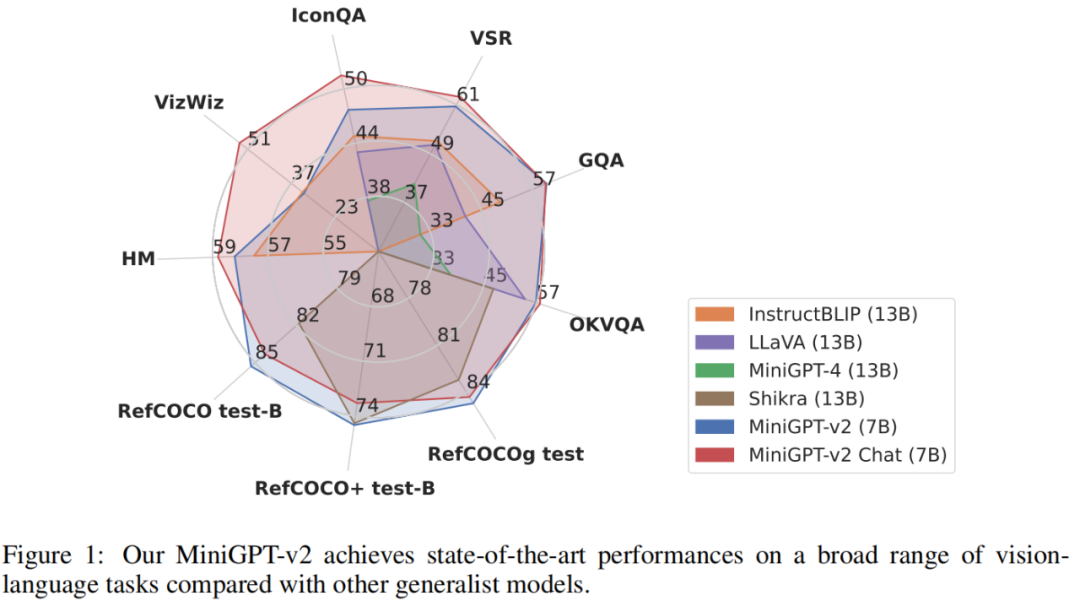
为了评估 MiniGPT-v2 模型的性能,研究者对不同的视觉 - 语言任务进行了广泛的实验。结果表明,与之前的视觉 - 语言通用模型(例如 MiniGPT-4、InstructBLIP、 LLaVA 和 Shikra)相比,MiniGPT-v2 在各种基准上实现了 SOTA 或相当的性能。例如 MiniGPT-v2 在 VSR 基准上比 MiniGPT-4 高出 21.3%,比 InstructBLIP 高出 11.3%,比 LLaVA 高出 11.7%。
下面我们通过具体的示例来说明 MiniGPT-v2 识别符号的作用。
例如,通过加 [grounding] 识别符号,模型可以很容易生成一个带有空间位置感知的图片描述:

通过添加 [detection] 识别符号,模型可以直接提取输入文本里面的物体并且找到它们在图片中的空间位置:

框出图中的一个物体,通过加 [identify] ,可以让模型直接识别出来物体的名字:
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 通过加 [refer] 和一个物体的描述,模型可以直接帮你找到物体对应的空间位置:
通过加 [refer] 和一个物体的描述,模型可以直接帮你找到物体对应的空间位置:

你也可以不加任何任务识别符合,和图片进行对话:

模型的空间感知也变得更强,可以直接问模型谁出现在图片的左面,中间和右面:

MiniGPT-v2 模型架构如下图所示,它由三个部分组成:视觉主干、线性投影层和大型语言模型。

视觉主干:MiniGPT-v2 采用 EVA 作为主干模型,并且在训练期间会冻结视觉主干。训练模型的图像分辨率为 448x448 ,并插入位置编码来扩展更高的图像分辨率。
线性投影层:本文旨在将所有的视觉 token 从冻结的视觉主干投影到语言模型空间中。然而,对于更高分辨率的图像(例如 448x448),投影所有的图像 token 会导致非常长的序列输入(例如 1024 个 token),显着降低了训练和推理效率。因此,本文简单地将嵌入空间中相邻的 4 个视觉 tok en 连接起来,并将它们一起投影到大型语言模型的同一特征空间中的单个嵌入中,从而将视觉输入 token 的数量减少了 4 倍。
en 连接起来,并将它们一起投影到大型语言模型的同一特征空间中的单个嵌入中,从而将视觉输入 token 的数量减少了 4 倍。
大型语言模型:MiniGPT-v2 采用开源的 LLaMA2-chat (7B) 作为语言模型主干。在该研究中,语言模型被视为各种视觉语言输入的统一接口。本文直接借助 LLaMA-2 语言 token 来执行各种视觉语言任务。对于需要生成空间位置的视觉基础任务,本文直接要求语言模型生成边界框的文本表示以表示其空间位置。
多任务指令训练
本文使用任务识别符号指令来训练模型,分为三个阶段。各阶段训练使用的数据集如表 2 所示。

阶段 1:预训练。本文对弱标记数据集给出了高采样率,以获得更多样化的知识。
阶段 2:多任务训练。为了提高 MiniGPT-v2 在每个任务上的性能,现阶段只专注于使用细粒度数据集来训练模型。研究者从 stage-1 中排除 GRIT-20M 和 LAION 等弱监督数据集,并根据每个任务的频率更新数据采样比。该策略使本文模型能够优先考虑高质量对齐的图像文本数据,从而在各种任务中获得卓越的性能。
阶段 3:多模态指令调优。随后,本文专注于使用更多多模态指令数据集来微调模型,并增强其作为聊天机器人的对话能力。
最后,官方也提供了 Demo 供读者测试,例如,下图中左边我们上传一张照片,然后选择 [Detection] ,接着输入「red balloon」,模型就能识别出图中红色的气球:

感兴趣的读者,可以查看论文主页了解更多内容。
以上就是MiniGPT-4升级到MiniGPT-v2了,不用GPT-4照样完成多模态任务的详细内容,更多请关注其它相关文章!
# 更高
# 高端鞋如何营销推广
# 知名的百度网站优化软件
# 开阳抖音关键词排名推广
# 宝坻区网站营销推广中心
# 唐山营销推广培训机构哪家好
# 贵州测量网站优化耗材
# 知名网站搜索排名优化
# 营销推广想法有哪些
# 新品牌推广营销策略
# 公司推广软文范文网站
# 所示
# 数据
# 阿卜杜拉
# 出了
# 本田
# 高出
# 可以直接
# 图中
# 多模
# 升级到
# llama
# ai
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
pixivFANBOX 更新运营规则,禁止通过外链绕开 AI 生成禁令
RoboNeo操作教程
扎克伯格吐槽苹果Vision Pro:社交落后Meta太多,无法建设元宇宙
不止“文心一言”,消息称百度将推出全新 AI 对话软件“万话”
腾讯TRS之元学习与跨域推荐的工业实战
五款 AI 网站构建器,任何人都能快速构建网站
抖音在Android平台获得VR|直播|软件著作权
参考封面|人工智能“淘金热”
以计算机视觉技术为基础的库存管理如何改革零售行业
华为AI大模型将融入HarmonyOS 4
GPT-4是如何工作的?哈佛教授亲自讲授
微软必应聊天现已在Chrome和Safari浏览器上可用,但仍有许多限制存在
北交大推出国内首个开源交通大模型TransGPT,可免费商用
Adobe旗下Illustrator引入生成式AI工具Firefly
马斯克的幽默“现实”:AR眼镜与20美元“增强现实”哪个真实?
优傲机器人的人机协作技术 助力中小企发展
上海发布大模型政策 打造AI“模”都
郭帆谈ChatGPT:电影行业需要创新,否则人工智能将让电影变得平庸
英伟达H100霸榜权威AI性能测试 11分钟搞定基于GPT-3的大模型训练
智能机器人与话剧的完美结合:宇树四足机器人B1助力《骆驼祥子》重现经典
微软Bing聊天机器人电脑端即将支持语音提问
优化J*a与MySQL合作:分享批处理操作的技巧
会模仿笔迹的AI,为你创造专属字体
XREAL Beam 投屏盒子正式发布:支持“可悬停 AR 空间屏”
无需标注数据,「3D理解」进入多模态预训练时代!ULIP系列全面开源,刷新SOTA
数字彩排、虚拟建厂!这家顶级洗衣机工厂敲开“工业元宇宙”之门
普林斯顿大学推出Infinigen AI模型 可生成真实自然环境 3D场景
如何成功实施人工智能?
鉴智机器人发布基于地平线征程5的标准视觉感知产品
GPT-4成功战胜AI-Guardian审核系统:谷歌研究团队的人工智能抵抗人工智能
机构研选 | 虚拟电厂是电力物联网升级版 智能电网望迎来高速发展
中国气象局预测:到 2030 年,中国人工智能气象应用将达到国际领先水平
大厂出品!这个AI网站太顶了,所有功能免费用
小米首次曝光 64 亿参数的 MiLM-6B AI 大模型,或将应用于小爱同学
智能技术提高现代商业运营的7七种方式
2025年深圳举办的SUSECON 创新峰会开始接受报名
原小米 9 号员工李明打造全球首款 AI 安卓桌面机器人
丰田汽车研究院推出生成式人工智能汽车设计工具
精准度可提高 20%:英国九家银行签约使用基于 AI 的“消费者欺诈风险系统”应对*
周鸿祎参加中美青年科技创新峰会,分享人工智能创新机遇
讯飞听见会写“会议摘要”功能全面升级,AI更懂你的关注点
“图壤·阅读元宇宙”亮相北京国际图书博览会
浪潮KaiwuDB:“快人一步” - 打造更懂物联网的数据库
北京市通用人工智能产业创新伙伴计划名单公布,京东科技入选“算力伙伴”
Zoom远程会议应用:AI培训需经用户授权
《自然》杂志拒绝刊登人工智能生成的图片和视频
云鲸发布全新的扫拖机器人J4系列
Meta发布"类人"AI图像创建模型,能解决多出手指等Bug
ChatGPT大更新!OpenAI奉上程序员大礼包:API新增杀手级能力还降价,新模型、四倍上下文都来了
“一般智力”与工艺学批判是认识AI的重要入口 | 社会科学报
2023-10-17

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
