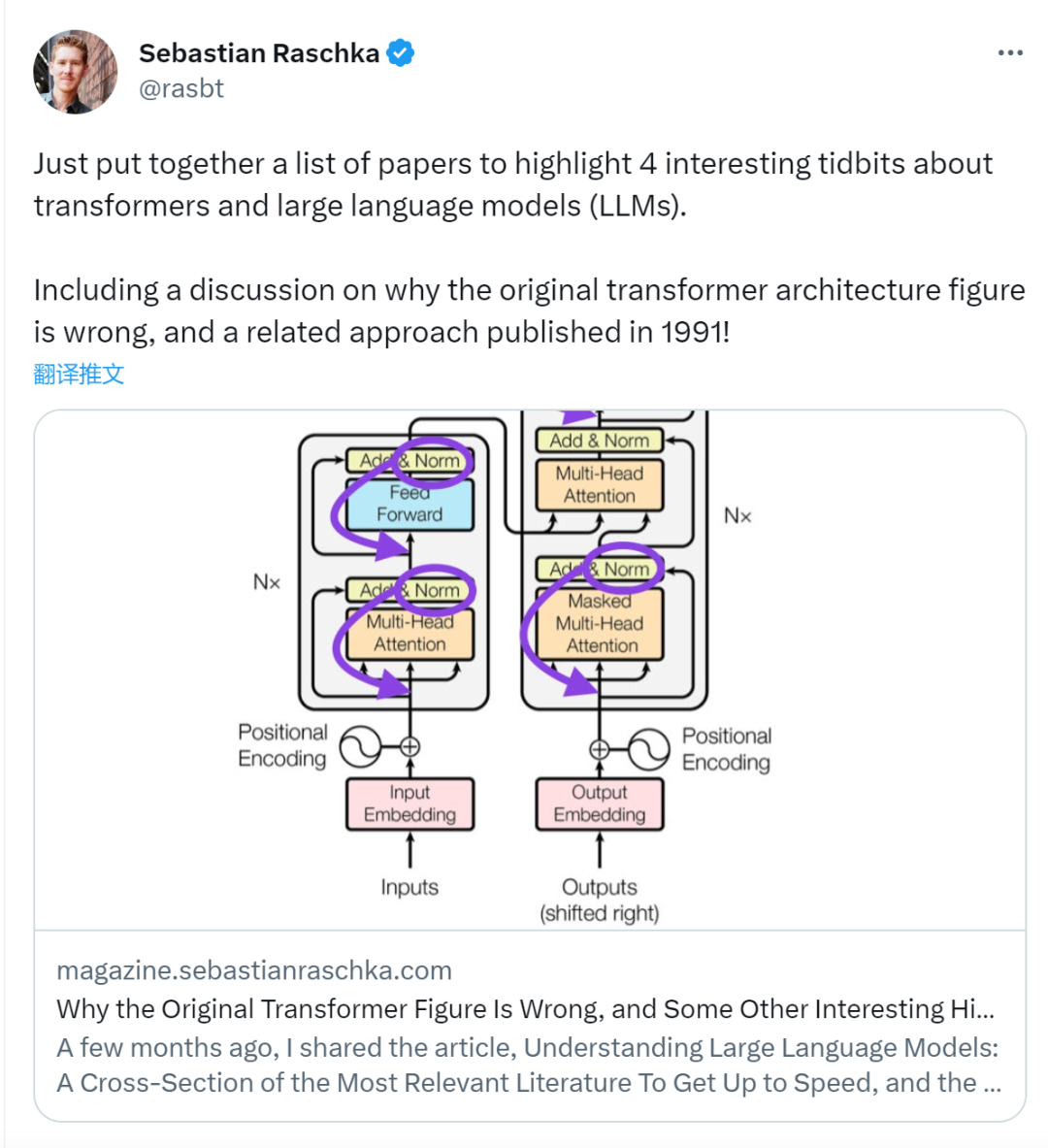
前段时间,一条指出谷歌大脑团队论文《Attention Is All You Need》中 Transformer 构架图与代码不一致的推文引发了大量的讨论。
对于 Sebastian 的这一发现,有人认为属于无心之过,但同时也会令人感到奇怪。毕竟,考虑到 Transformer 论文的流行程度,这个不一致问题早就应该被提及 1000 次。
Sebastian Raschka 在回答网友评论时说,「最最原始」的代码确实与架构图一致,但 2017 年提交的代码版本进行了修改,但同时没有更新架构图。这也是造成「不一致」讨论的根本原因。
随后,Sebastian 在 Ahead of AI 发布文章专门讲述了为什么最初的 Transformer 构架图与代码不一致,并引用了多篇论文简要说明了 Transformer 的发展变化。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
以下为文章原文,让我们一起看看文章到底讲述了什么:
几个月前,我分享了《Understanding Large Language Models: A Cross-Section of the Most Relevant Literature To Get Up to Speed》,积极的反馈非常鼓舞人心!因此,我添加了一些论文,以保持列表的新鲜感和相关性。
同时,保持列表简明扼要是至关重要的,这样大家就可以用合理的时间就跟上进度。还有一些论文,信息量很大,想来也应该包括在内。
我想分享四篇有用的论文,从历史的角度来理解 Transformer。虽然我只是直接将它们添加到理解大型语言模型的文章中,但我也在这篇文章中单独来分享它们,以便那些之前已经阅读过理解大型语言模型的人更容易找到它们。
On Layer Normalization in the Transformer Architecture (2025)
虽然下图(左)的 Transformer 原始图(https://arxiv.org/abs/1706.03762)是对原始编码器 - 解码器架构的有用总结,但该图有一个小小的差异。例如,它在残差块之间进行了层归一化,这与原始 Transformer 论文附带的官方 (更新后的) 代码实现不匹配。下图(中)所示的变体被称为 Post-LN Transformer。
Transformer 架构论文中的层归一化表明,Pre-LN 工作得更好,可以解决梯度问题,如下所示。许多体系架构在实践中采用了这种方法,但它可能导致表征的崩溃。
因此,虽然仍然有关于使用 Post-LN 或前 Pre-LN 的讨论,也有一篇新论文提出了将两个一起应用:《 ResiDual: Transformer with Dual Residual Connections》(https://arxiv.org/abs/2304.14802),但它在实践中是否有用还有待观察。
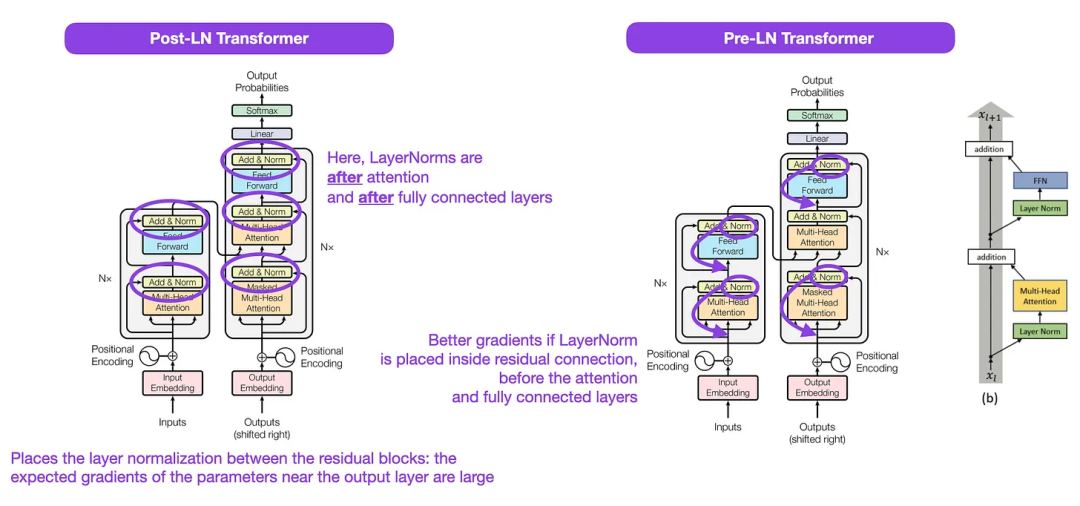
图注:图源 https://arxiv.org/abs/1706.03762 (左 & 中) and https://arxiv.org/abs/2002.04745 (右)
Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Neural Networks (1991)
这篇文章推荐给那些对历史花絮和早期方法感兴趣的人,这些方法基本上类似于现代 Transformer。
例如,在比 Transformer 论文早 25 年的 1991 年,Juergen Schmidhuber 提出了一种递归神经网络的替代方案(https://www.semanticscholar.org/paper/Learning-to-Control-Fast-Weight-Memories%3A-An-to-Schmidhuber/bc22e87a26d020255afe91c751e5bdaddd8e4922),称为 Fast Weight Programmers (FWP)。实现快速权值变化的另一个神经网络是通过使用梯度下降算法缓慢学习的 FWP 方法中所涉及的前馈神经网络。
这篇博客 (https://people.idsia.ch//~juergen/fast-weight-programmer-1991-transformer.html#sec2) 将其与现代 Transformer 进行类比,如下所示:
在今天的 Transformer 术语中,FROM 和 TO 分别称为键 (key) 和值 (value)。应用快速网络的输入称为查询。本质上,查询由快速权重矩阵 (fast weight matrix) 处理,它是键和值的外积之和 (忽略归一化和投影)。我们可以使用加法外积或二阶张量积来实现端到端可微的主动控制权值快速变化,因为两个网络的所有操作都支持微分。在序列处理期间,梯度下降可以用于快速调整快速网络,从而应对慢速网络的问题。这在数学上等同于 (除了归一化之外) 后来被称为具有线性化自注意的 Transformer (或线性 Transformer)。
正如上文摘录所提到的,这种方法现在被称为线性 Transformer 或具有线性化自注意的 Transformer。它们来自于 2025 年出现在 arXiv 上的论文《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention 》(https://arxiv.org/abs/2006.16236)以及《Rethinking Attention with Performers》(https://arxiv.org/abs/2009.14794)。
2025 年,论文《Linear Transformers Are Secretly Fast Weight Programmers》(https://arxiv.org/abs/2102.11174)明确表明了线性化自注意力和 20 世纪 90 年代的快速权重编程器之间的等价性。
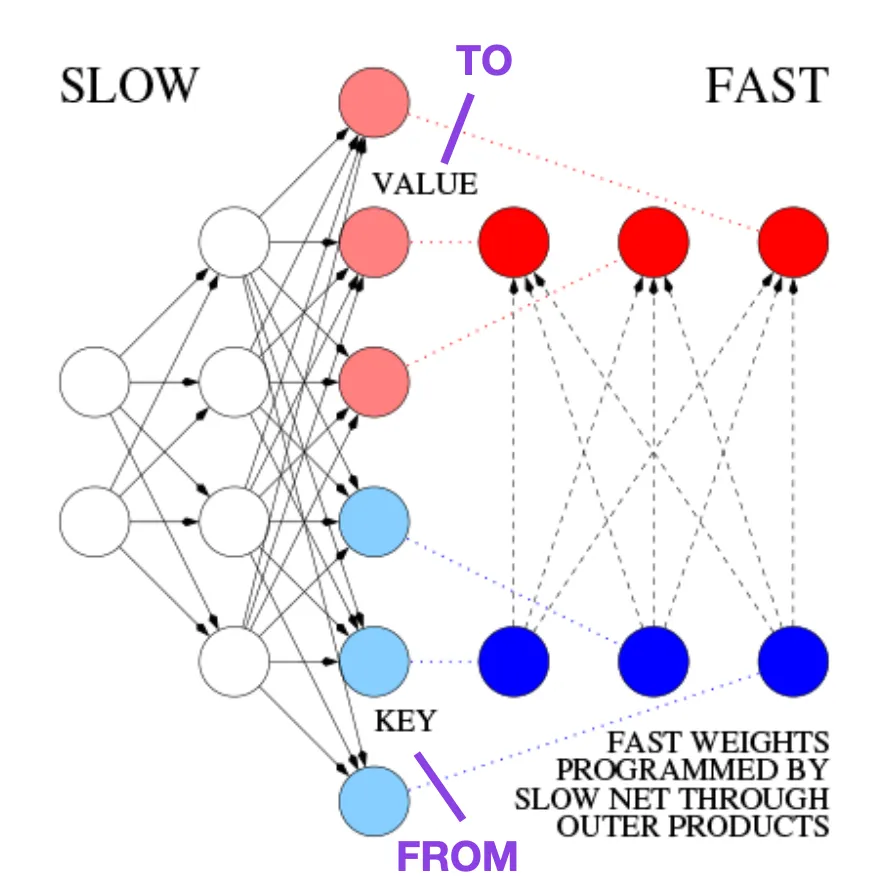
图源:https://people.idsia.ch//~juergen/fast-weight-programmer-1991-transformer.html#sec2
 Seede AI
Seede AI
AI 驱动的设计工具
 713
713
 查看详情
查看详情

Universal Language Model Fine-tuning for Text Classification (2018)
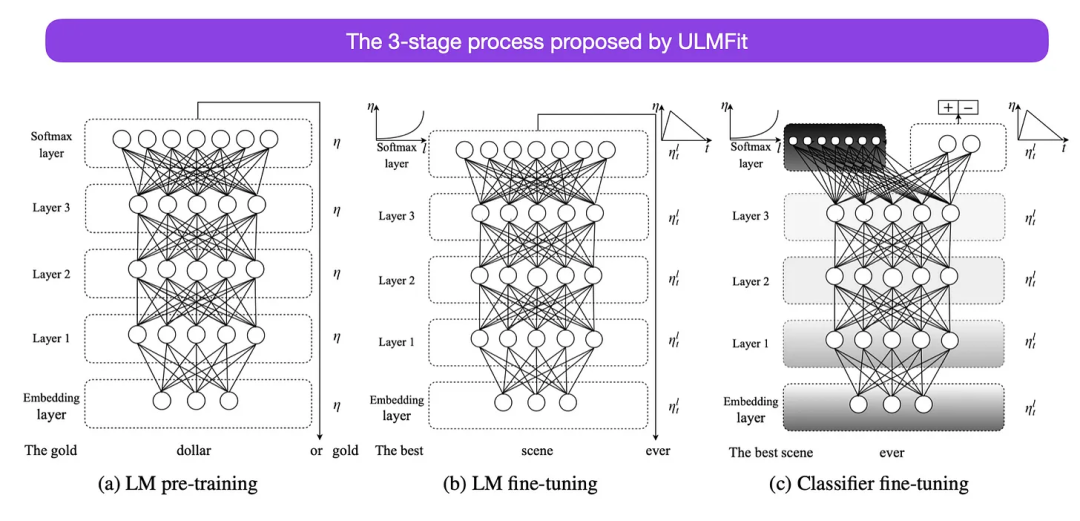
这是另一篇从历史角度来看非常有趣的论文。它是在原版《Attention Is All You Need》发布一年后写的,并没有涉及 transformer,而是专注于循环神经网络,但它仍然值得关注。因为它有效地提出了预训练语言模型和迁移学习的下游任务。虽然迁移学习已经在计算机视觉中确立,但在自然语言处理 (NLP) 领域还没有普及。ULMFit(https://arxiv.org/abs/1801.06146)是首批表明预训练语言模型在特定任务上对其进行微调后,可以在许多 NLP 任务中产生 SOTA 结果的论文之一。
ULMFit 建议的语言模型微调过程分为三个阶段:
在大型语料库上训练语言模型,然后在下游任务上对其进行微调的这种方法,是基于 Transformer 的模型和基础模型 (如 BERT、GPT-2/3/4、RoBERTa 等) 使用的核心方法。
然而,作为 ULMFiT 的关键部分,逐步解冻通常在实践中不进行,因为 Transformer 架构通常一次性对所有层进行微调。
Gopher 是一篇特别好的论文(https://arxiv.org/abs/2112.11446),包括大量的分析来理解 LLM 训练。研究人员在 3000 亿个 token 上训练了一个 80 层的 2800 亿参数模型。其中包括一些有趣的架构修改,比如使用 RMSNorm (均方根归一化) 而不是 LayerNorm (层归一化)。LayerNorm 和 RMSNorm 都优于 BatchNorm,因为它们不局限于批处理大小,也不需要同步,这在批大小较小的分布式设置中是一个优势。RMSNorm 通常被认为在更深的体系架构中会稳定训练。
除了上面这些有趣的花絮之外,本文的主要重点是分析不同规模下的任务性能分析。对 152 个不同任务的评估显示,增加模型大小对理解、事实核查和识别有毒语言等任务最有利,而架构扩展对与逻辑和数学推理相关的任务从益处不大。
图注:图源 https://arxiv.org/abs/2112.11446
以上就是此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处的详细内容,更多请关注其它相关文章!
# 但它
# 大连seo教程如何赚钱
# 五金建材推广网站
# 泰安网站建设及优化
# 优化网站排名口碑
# 白山网页seo
# 平利县关键词排名推广
# 关键词排名优化技巧价格
# 宜宾网站建设略奥网络
# 文档模板网站建设公司
# 抚顺seo优化平台
# AI
# 所示
# 被称为
# 的人
# 提出了
# 在何处
# 线性化
# 架构图
# 开源
# 递归
# 架构
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
微盟宣布联合腾讯云共建行业大模型:加快激活AI大模型智能应用
Meta 人工智能业务落后竞争对手,研究人员大量离职成重要原因
人工智能“Aria”现身 Opera浏览器100版本更新:新功能“标签岛”
图像生成过程中遭「截胡」:稳定扩散的失败案例受四大因素影响
人工智能助力精准学习,猿辅导小猿学练机满足学生个性化学习需求
周星驰支持的人工智能与 Web3 初创公司 Moonbox 完成 100 万美元融资
AI证件照生成器:实际测试中AI软件展现了绝无仅有的强大效能
常见的五个人工智能误解
尼康尼克尔 Z 180-600mm f/5.6-6.3 VR 镜头发布,12499 元
午报 | 字节跳动要造机器人;东方甄选首次启动自有APP|直播|
2025“春晖杯”人工智能专场对接活动举办
AI绘画,还需要懂数学?
讯飞听见会写“会议摘要”功能全面升级,AI更懂你的关注点
云南首例达芬奇机器人微创心脏手术成功开展
优傲机器人的人机协作技术 助力中小企发展
京东 AI 大模型官宣 7 月 13 日发布,还有重磅合作
微幼科技晨检机器人与人工晨检相比,有何优势
OpenAI更新GPT-4等模型,新增API函数调用,价格最高降75%
调研海尔智家:AI名,家电命?
70年前他本想逃避考试,却影响了整个互联网
三星加速AR眼镜进程,预计明年上半年亮相
AI大模型火了!科技巨头纷纷加入,多地政策加码加速落地
微软和谷歌面临的人工智能困境:需要投入大量资金才能获得盈利
RoboNeo操作教程
华为HarmonyOS 4:享流畅提升20%,AI大模型更智能一览无余
陈根教授:离人形机器人时代还有10年吗?
微软 Copilot 团队主管呼吁用户与 AI 交流时应使用恰当的礼貌用语
实现人工智能和物联网的协同运作
Meta 为打造元宇宙不惜下血本:VR 开发者年薪高达百万美元
实现MySQL数据锁定策略:解决并发冲突的J*a解决方案
工信部信通院发布《2025大模型和AIGC产业图谱》 360智脑覆盖全产业链
网易易盾 AI Lab 论文入选 ICASSP 2025!黑科技让语音识别越“听”越准
MiracleVision视觉大模型功能介绍
抖音在Android平台获得VR|直播|软件著作权
李开复官宣新公司「零一万物」,进军 AI 2.0
复旦发布「新闻推荐生态系统模拟器」SimuLine:单机支持万名读者、千名创作者、100+轮次推荐
13万个注释神经元,5300万个突触,普林斯顿大学等发布首个完整「成年果蝇」大脑连接组
软通动力天枢元宇宙研究院签约落户江宁高新区
AI时代,企业需要什么样的员工?
人工智能大胆预测:银河系至少有2万个地球,36种外星文明
《共同的演化》展览启幕,重新思考人类与人工智能关系
视觉中国宣布推出AI灵感绘图、画面扩展功能
Gartner预测:到2025年,全球对话式人工智能支出预计将达到1860亿美元
Transformer六周年:当年连NeurIPS Oral都没拿到,8位作者已创办数家AI独角兽
美图吴欣鸿:希望更多人用上AI时代的影像生产力工具
人工智能进入绿植界,智能庭院市场初具规模
从医疗康复外骨骼到通用人形机器人,傅利叶智能推动核心技术升级
微幼科技晨检机器人:幼儿园健康保障的新伙伴
海南科技职业大学第25届中国机器人及人工智能大赛海南赛区荣获一等奖等114项
你大脑中的画面,现在可以高清还原了
2023-06-14

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
