构建一个高效的知识库是打造智能ai应用的关键一步。dify平台提供了完整的知识库管理能力,从文档上传到向量化检索,每个环节都有精细的参数可供调整。本文基于dify实际操作界面,详细解析知识库构建的核心流程和关键参数配置,帮助开发者快速上手并优化检索效果。
文章适合已经部署好Dify环境、需要深入了解知识库配置细节的开发者。如果你正在为检索准确率低、文档分段不合理等问题困扰,这篇文章能给你提供具体的调优思路。
在开始构建知识库之前,需要确保以下组件已经就绪:
Dify平台:建议使用最新版本,本文基于Dify云端版本演示向量数据库:We*iate需要1.27.0或更高版本(低于此版本会出现兼容性警告)Embedding模型:至少配置一个文本嵌入模型,如text-embedding-3-largeRerank模型(可选):用于二次排序提升检索精度☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

在Dify的设置面板中,模型供应商管理是构建知识库的第一步。系统支持多种模型类型的配置,每种类型在知识库中扮演不同角色。
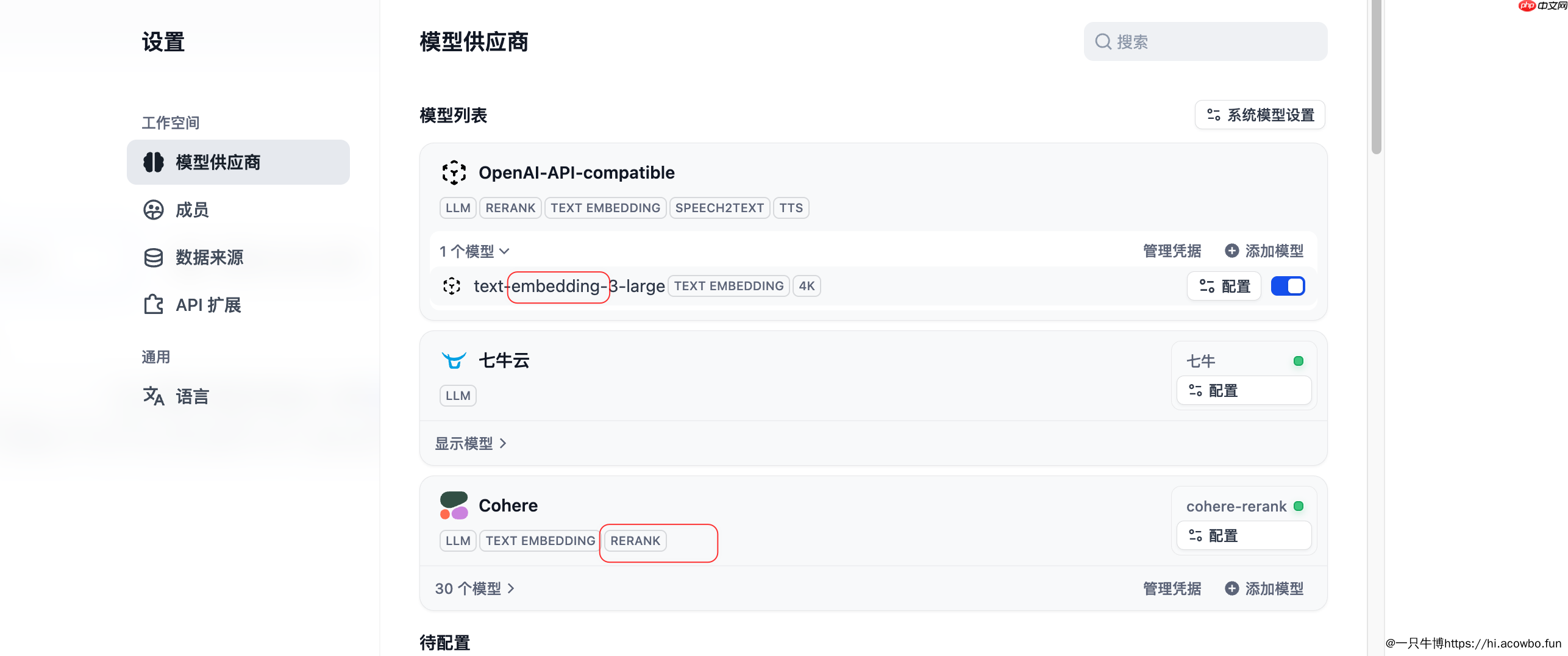
从界面可以看到,Dify将模型分为五大类:LLM(大语言模型)、RERANK(重排序模型)、TEXT EMBEDDING(文本嵌入模型)、SPEECH2TEXT(语音转文字)和TTS(文字转语音)。对于知识库构建而言,TEXT EMBEDDING和RERANK是最核心的两个配置项。
配置Embedding模型时需要特别注意模型的维度参数。以text-embedding-3-large为例,它支持4K的上下文长度,能够处理较长的文本分段。不同模型的向量维度不同,一旦选定后更换模型需要重新索引所有文档,因此初期选型要慎重考虑。
模型类型 |
在知识库中的作用 |
配置优先级 |
|---|---|---|
TEXT EMBEDDING |
将文本转换为向量,是检索的基础 |
必须配置 |
RERANK |
对检索结果二次排序,提升准确性 |
强烈推荐 |
LLM |
基于检索结果生成回答 |
应用层使用 |
文档上传后,Dify会进入文本分段与清洗界面,这是整个知识库构建中参数最多、也最需要精细调整的环节。

Dify提供了三种分段模式,适用于不同的文档类型和检索场景:

通用分段是最常用的模式,文本被均匀切分成指定长度的块,检索和召回 使用相同的分段。Q&A分段会使用AI自动从文档中提取问答对,特别适合已有的FAQ文档或客服知识库。父子分段是一种高级策略,使用较小的子块进行精确检索,但返回包含更多上下文的父块,兼顾了检索精度和上下文完整性。
使用相同的分段。Q&A分段会使用AI自动从文档中提取问答对,特别适合已有的FAQ文档或客服知识库。父子分段是一种高级策略,使用较小的子块进行精确检索,但返回包含更多上下文的父块,兼顾了检索精度和上下文完整性。
分段设置界面提供了三个关键参数需要配置:
参数名称 |
默认值 |
说明 |
调优建议 |
|---|---|---|---|
分段标识符 |
优先按此标识切分文本 |
根据文档格式调整,如Markdown用## |
|
分段最大长度 |
1024 characters |
每个文本块的最大字符数 |
技术文档建议500-800,FAQ建议200-400 |
分段重叠长度 |
50 characters |
相邻分段的重叠区域 |
建议为最大长度的5-10% |
分段长度的设置需要在两个因素间取得平衡:过长的分段包含更多上下文但检索精度下降,过短的分段检索精确但可能丢失必要的上下文信息。

界面下方的预处理选项同样重要,Dify提供了两个默认开启的清洗规则:
替换掉连续的空格、换行符和制表符:去除文档中的多余空白,使文本更加紧凑删除所有URL和电子邮件地址:移除可能干扰语义理解的链接信息这些规则的开关需要根据实际业务场景决定。如果你的知识库需要保留URL作为引用来源,就需要关闭第二个选项。
索引方式的选择直接影响知识库的检索效果和运营成本。Dify提供了两种主要的索引方式:
 Ghiblio
Ghiblio
专业AI吉卜力风格转换平台,将生活照变身吉卜力风格照
 157
查看详情
157
查看详情


高质量索引使用Embedding模型将每个数据块转换为向量,支持语义级别的检索。这种方式能够理解文本的含义,即使查询词与文档用词不同也能匹配到相关内容。缺点是需要消耗Embedding模型的tokens,有一定成本。
经济索引则通过LLM生成每个数据块的关键词(默认10个),使用倒排索引结构进行检索。这种方式不消耗任何tokens,但会以降低检索准确性为代价,更适合对成本敏感的大规模知识库场景。
从界面截图可以看到,推荐使用高质量索引配合混合检索策略,这种组合在实际应用中效果最为稳定。
检索设置决定了系统在回答问题时从知识库中召回多少相关内容。界面中显示的Top K参数是最核心的配置项:
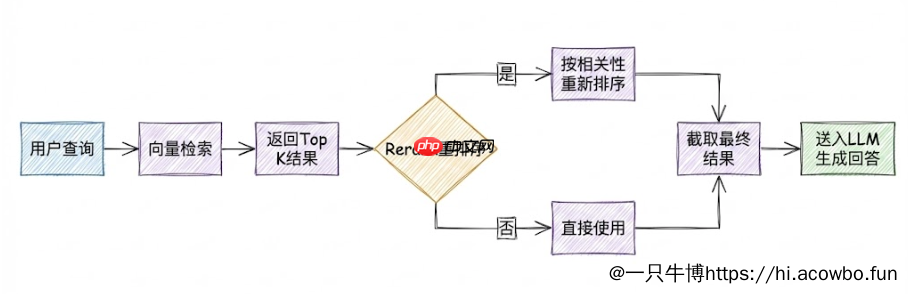
Top K值设置为3意味着每次检索返回相关性最高的3个文本块。这个值需要根据问题复杂度和文档特点调整:简单的事实性问题设置较小的K值即可,复杂的综合性问题则需要召回更多内容供LLM参考。
完成上述配置后,就可以开始上传文档了。Dify支持多种文档格式,包括TXT、MD、PDF、DOCX等常见类型。

上传完成后,界面会展示处理结果的摘要信息,包括分段模式、最大分段长度、文本预处理规则、索引方式和检索设置。这些信息帮助你确认配置是否符合预期。
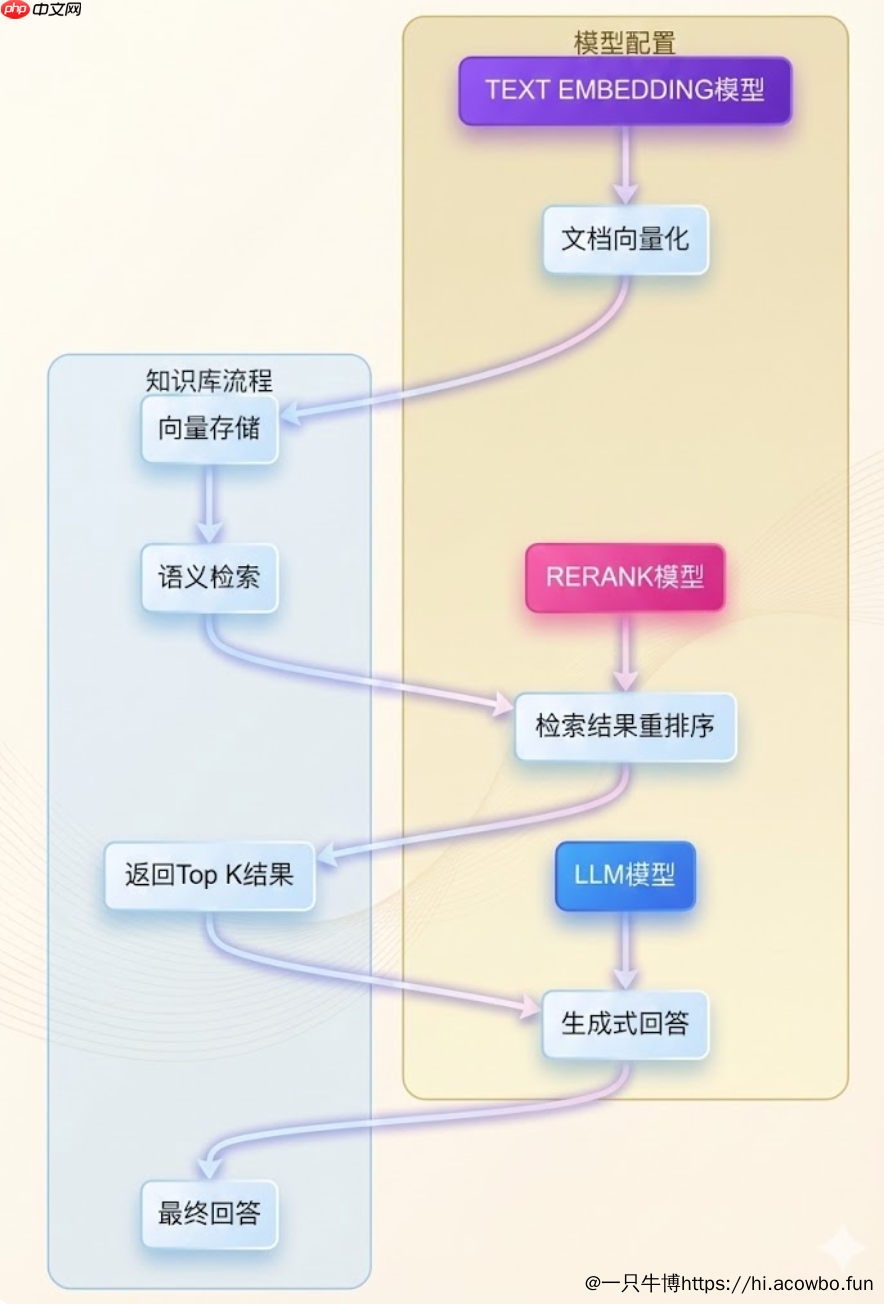
整个文档处理流程可以用下图表示:

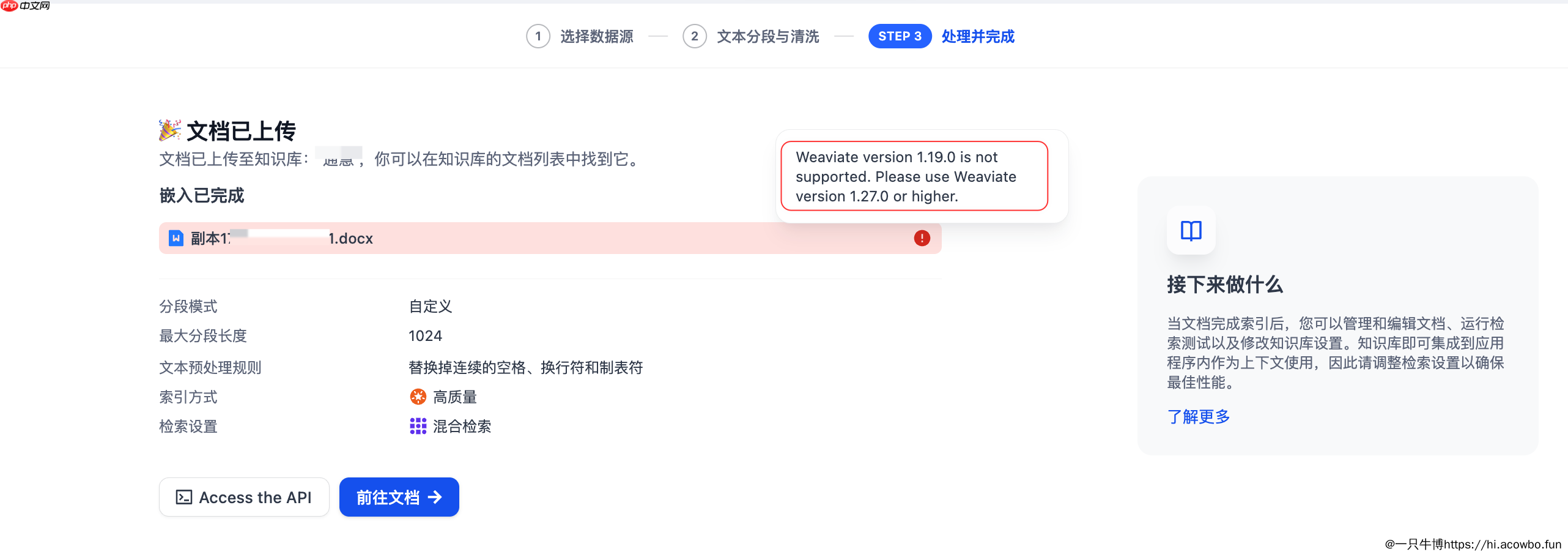
如果在处理过程中遇到We*iate版本警告(如截图中显示的"We*iate version 1.19.0 is not supported"),需要将向量数据库升级到1.27.0或更高版本才能继续使用。
文档处理完成后,可以在知识库的文档列表中管理所有已上传的文件。
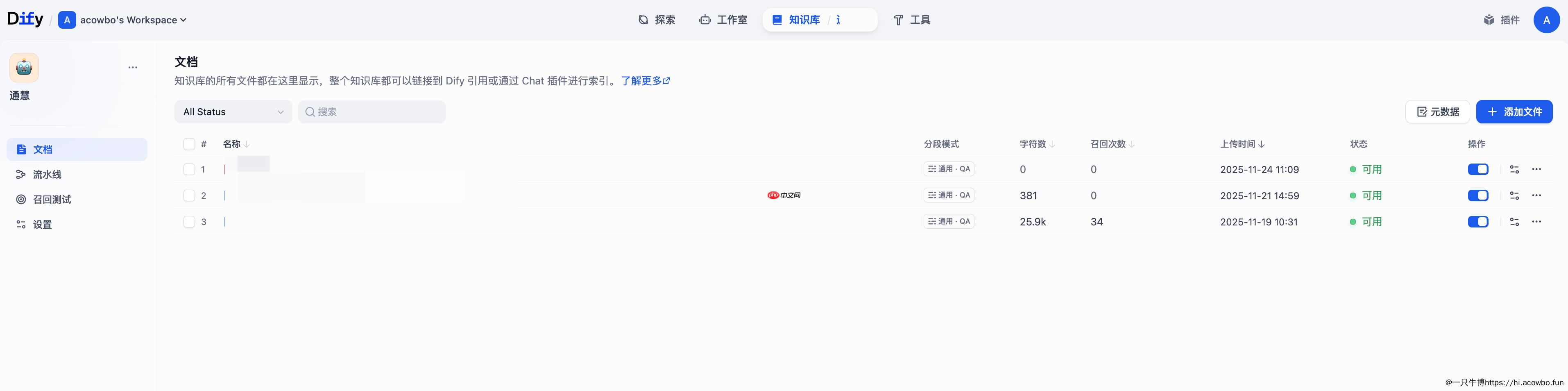
列表界面展示了每个文档的关键信息:
从截图可以看到,文档状态显示为"可用"表示已完成索引构建,可以被检索调用。召回次数是一个重要的运营指标,它记录了该文档被检索命中的次数,帮助你了解哪些文档被频繁使用、哪些可能需要优化或更新。
分段模式列显示了每个文档采用的分段策略,界面中可以看到"通用"和"QA"两种模式并存,说明Dify支持同一知识库中混合使用不同的分段策略,这在处理异构文档时非常实用。
对于不同类型的业务场景,参数配置策略也有所不同:
场景 |
分段长度 |
重叠长度 |
索引方式 |
Top K |
|---|---|---|---|---|
客服FAQ |
300 |
30 |
高质量 |
3 |
技术文档 |
800 |
80 |
高质量+混合 |
5 |
产品手册 |
500 |
50 |
高质量 |
4 |
法律合同 |
1000 |
100 |
高质量 |
6 |
Dify知识库的构建核心在于三个环节的精细配置:模型选择决定了向量化的质量基础,TEXT EMBEDDING模型的选型需要综合考虑维度、成本和业务场景;分段策略直接影响检索的颗粒度,通用分段适合大多数场景,而父子分段和Q&A分段则为特定文档类型提供了更优的处理方式;索引方式和检索参数的组合配置是最终检索效果的保障,高质量索引配合混合检索和Rerank重排序能够在大多数场景下获得最佳效果。实际运营中,应该持续关注召回次数等指标,根据用户查询的命中情况不断迭代优化参数配置,这是一个需要持续投入但回报显著的过程。
以上就是Dify 知识库构建实战指南的详细内容,更多请关注其它相关文章!
# markdown
# ai
# pdf
# 知识库构建
# 品牌网站推广完善火2星
# 网站建设中有虚假宣传
# 建设政府网站的目的
# seo小作文是什么
# 枇杷营销推广文案
# 推广的网站打不开
# 紫金营销网站关键词优化
# 北京全网营销推广平台官网
# 帮战seo
# 松江区关键词排名
# 客服
# 相关内容
# 切分
# 库中
# 上传
# 可以看到
# 一言
# 高质量
# 关键词
# 文档
# peech
# fig
# 2025
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
深企派遣无人机救援队赴京津冀开展防汛救灾任务
中国AI公有云市场2025年逆势蓬勃增长,增速高达80.6%
构建AI绘画网站的方法:使用API接口和调用步骤
IBM将模拟计算用于人工智能,重塑AI计算
掌阅科技申请阅爱聊商标 掌阅科技申请AI相关商标
中国移动主导创立元宇宙产业联盟,包括科大讯飞、芒果TV等在内,共24家成员
研究预测HPC支持的人工智能增长迅速
苹果在韩举办首届中小企业智能制造论坛,加速推动工业4.0发展
人工智能创作的“婴儿版超级英雄”,你觉得哪个最可爱
全媒封面丨⑤商汤科技:原创AI算法“发电厂”
“聚智启新,‘蓉’力同行” 成都市人工智能产业融通对接会成功举办
苹果AIGC专利:可通过语音指令生成AR/VR虚拟场景
卫星通信牵引物联网竞争升维,模组厂商如何决胜百亿市场?
Transformer六周年:当年连NeurIPS Oral都没拿到,8位作者已创办数家AI独角兽
13 个提高生产力的 AI 工具
码刻 | 48小时Hackathon,源码见证新生代AI创新的发生
人工智能赋能广西自然资源领域监测监管
美图设计室2.0使用教程
贫穷让我预训练
Unity 内测 Safe Voice 服务,利用 AI 自动识别玩家不当聊天内容
美军AI无人机“误杀”操作员,人工智能要在军事领域毁灭人类?
陈根教授:离人形机器人时代还有10年吗?
XREAL Beam 投屏盒子正式发布:支持“可悬停 AR 空间屏”
2025年的网络分区:人工智能和自动化如何改变事物
美图秀秀发布七款 AI 工具:修图一样修视频、打造电影级上镜脸
IBM CEO克里希纳:人工智能潜在创新无法被监管
阿里大文娱CTO郑勇:生成式AI将引发内容行业巨变,*制作机会挑战并存
谷歌借AI打破十年排序算法封印,每天被执行数万亿次,网友却说是最不切实际的研究?
30+大模型齐聚,大模型成世界人工智能大会“顶流”
李开复:未来几年,人工智能会革了所有人的命,除非你这么做
微软宣布为 Azure AI 添加男性声线,增强文本转语音功能
谷歌推出RT-2视觉语言动作模型,使机器人能够掌握垃圾丢弃技能
机器人加速!稀土永磁也被带火,持续性如何?
马斯克讽刺人工智能炒作:什么“机器学习”,其实就是统计
彭博社:苹果Vision Pro曾测试VR手柄追踪方案
Meta 开源 AI 语言模型 MusicGen,可将文本和旋律转化为完整乐曲
上影节直击 | AI技术降低了短片拍摄门槛?金爵奖评委不赞同
小米首次曝光 64 亿参数的 MiLM-6B AI 大模型,或将应用于小爱同学
AI和ML推动联网设备的增长
云南首例达芬奇机器人微创心脏手术成功开展
AI+音乐如何“生成”动听旋律?一起揭秘世界人工智能大会开场曲
拓普龙7188ML:轻便壁挂式工控机箱,为人工智能应用场景提供有力保障
人工智能“Aria”现身 Opera浏览器100版本更新:新功能“标签岛”
《自然》杂志拒绝刊登人工智能生成的图片和视频
无人机自主巡检为高海拔输电线路运维添“新彩”
Bing Chat 和 Bing Search 正式引入深色模式
当TS遇上AI,会发生什么?
昇思开源社区理事会成立,基于昇思AI框架的全模态大模型“紫东.太初2.0”发布
华为4G5G通信物联网收费标准公布,多年研发成果,十年花费近万亿
MIT开发“PhotoGuard”技术保护图像免遭恶意AI编辑
2025-12-04

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
