精选200条数据后,MiniGPT-4被匹配相同模型的效果超越
在生成细节丰富和精确的图像描述方面,GPT-4 已经展现出了强大超凡的能力,其标志着一个语言和视觉处理新时代的到来。因此,类似于 GPT-4 的多模态大型语言模型(MLLM)近来异军突起,成为了一个炙手可热的新兴研究领域,其研究核心是将强大的 LLM 用作执行多模态任务的认知框架。MLLM 出人意料的卓越表现不仅超越了传统方法,更使其成为了实现通用人工智能的潜在途径之一。为了创造出好用的 MLLM,需要使用大规模的配对的图像 - 文本数据以及视觉 - 语言微调数据来训练冻结的 LLM(如 LLaMA 和 Vicuna)与视觉表征(如 CLIP 和 BLIP-2)之间的连接器(如 MiniGPT-4、LLaVA 和 LLaMA-Adapter)。MLLM 的训练通常分为两个阶段:预训练阶段和微调阶段。预训练的目的是让 MLLM 获得大量知识,而微调则是为了教会模型更好地理解人类意图并生成准确的响应。为了增强 MLLM 理解视觉 - 语言和遵循指令的能力,近期出现了一种名为指令微调(instruction tuning)的强大微调技术。该技术有助于将模型与人类偏好对齐,从而让模型在各种不同的指令下都能生|成人|类期望的结果。在开发指令微调技术方面,一个颇具建设性的方向是在微调阶段引入图像标注、视觉问答(VQA)和视觉推理数据集。InstructBLIP 和 Otter 等之前的技术的做法是使用一系列视觉 - 语言数据集来进行视觉指令微调,也得到了颇具潜力的结果。但是,人们已经观察到:常用的多模态指令微调数据集包含大量低质量实例,即其中的响应是不正确或不相关的。这样的数据具有误导性,并会对模型的性能表现造成负面影响。这一问题促使研究人员开始探究这一可能性:能否使用少量高质量的遵循指令数据来获得稳健的性能表现?近期的一些研究得到了鼓舞人心的成果,表明这个方向是有潜力的。比如 Zhou et al. 提出了 LIMA ,这是一个使用人类专家精挑细选出的高质量数据微调得到的语言模型。该研究表明,即使使用数量有限的高质量遵循指令数据,大型语言模型也可以得到让人满意的结果。所以,研究人员得出结论:在对齐方面,少即是多(Less is More)。然而,对于如何为微调多模态语言模型选择合适的高质量数据集,之前还没有一个清晰的指导方针。上海交通大学清源研究院和里海大学的一个研究团队填补了这一空白,提出了一个稳健有效的数据选择器。这个数据选择器能够自动识别并过滤低质量视觉 - 语言数据,从而确保模型训练所使用的都是最相关和信息最丰富的样本。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
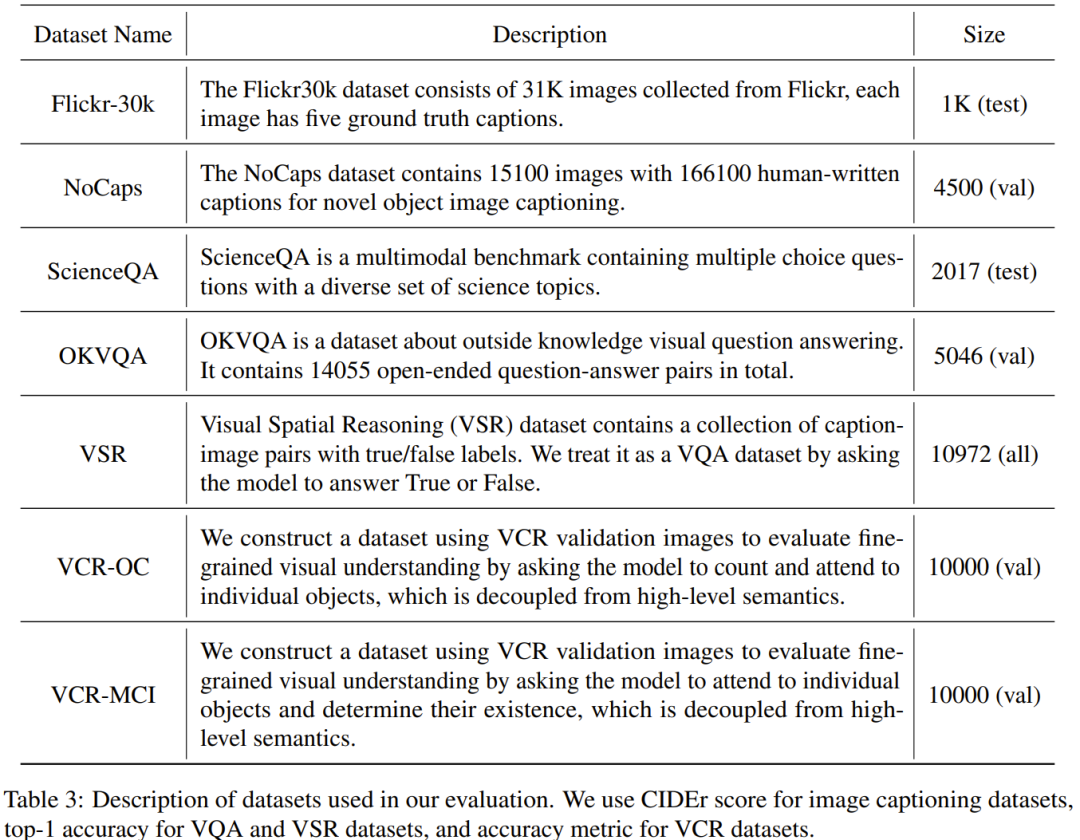
 论文地址:https://arxiv.org/abs/2308.12067研究者表示,这项研究关注的重点是探索少量但优质的指令微调数据对微调多模态大型语言模型的功效。除此之外,这篇论文还引入了几个专为评估多模态指令数据的质量而设计的新指标。在图像上执行谱聚类之后,数据选择器会计算一个加权分数,其组合了 CLIP 分数、GPT 分数、奖励分数和每个视觉 - 语言数据的答案长度。通过在用于微调 MiniGPT-4 所用的 3400 个原始数据上使用该选择器,研究者发现这些数据大部分都有低质量的问题。使用这个数据选择器,研究者得到了一个小得多的精选数据子集 —— 仅有 200 个数据,只有原始数据集的 6%。然后他们使用 MiniGPT-4 一样的训练配置,微调得到了一个新模型:InstructionGPT-4。研究者表示这是一个激动人心的发现,因为其表明:在视觉 - 语言指令微调中,数据的质量比数量更重要。此外,这种更加强调数据质量的变革提供了一个能提升 MLLM 微调的更有效的新范式。研究者进行了严格的实验,对已微调 MLLM 的实验评估集中于七个多样化且复杂的开放域多模态数据集,包括 Flick-30k、ScienceQA、 VSR 等。他们在不同的多模态任务上比较了使用不同数据集选取方法(使用数据选择器、对数据集随机采样、使用完整数据集)而微调得到的模型的推理性能,结果展现了 InstructionGPT-4 的优越性。此外还需说明:研究者用于评估的评价者是 GPT-4。具体而言,研究者使用了 prompt 将 GPT-4 变成了评价者,其可以使用 LLaVA-Bench 中的测试集来比较 InstructionGPT-4 和原始 MiniGPT-4 的响应结果。结果发现,尽管与 MiniGPT-4 所用的原始指令遵循数据相比,InstructionGPT-4 使用的微调数据仅有 6% 那么一点点,但后者在 73% 的情况下给出的响应都相同或更好。
论文地址:https://arxiv.org/abs/2308.12067研究者表示,这项研究关注的重点是探索少量但优质的指令微调数据对微调多模态大型语言模型的功效。除此之外,这篇论文还引入了几个专为评估多模态指令数据的质量而设计的新指标。在图像上执行谱聚类之后,数据选择器会计算一个加权分数,其组合了 CLIP 分数、GPT 分数、奖励分数和每个视觉 - 语言数据的答案长度。通过在用于微调 MiniGPT-4 所用的 3400 个原始数据上使用该选择器,研究者发现这些数据大部分都有低质量的问题。使用这个数据选择器,研究者得到了一个小得多的精选数据子集 —— 仅有 200 个数据,只有原始数据集的 6%。然后他们使用 MiniGPT-4 一样的训练配置,微调得到了一个新模型:InstructionGPT-4。研究者表示这是一个激动人心的发现,因为其表明:在视觉 - 语言指令微调中,数据的质量比数量更重要。此外,这种更加强调数据质量的变革提供了一个能提升 MLLM 微调的更有效的新范式。研究者进行了严格的实验,对已微调 MLLM 的实验评估集中于七个多样化且复杂的开放域多模态数据集,包括 Flick-30k、ScienceQA、 VSR 等。他们在不同的多模态任务上比较了使用不同数据集选取方法(使用数据选择器、对数据集随机采样、使用完整数据集)而微调得到的模型的推理性能,结果展现了 InstructionGPT-4 的优越性。此外还需说明:研究者用于评估的评价者是 GPT-4。具体而言,研究者使用了 prompt 将 GPT-4 变成了评价者,其可以使用 LLaVA-Bench 中的测试集来比较 InstructionGPT-4 和原始 MiniGPT-4 的响应结果。结果发现,尽管与 MiniGPT-4 所用的原始指令遵循数据相比,InstructionGPT-4 使用的微调数据仅有 6% 那么一点点,但后者在 73% 的情况下给出的响应都相同或更好。
- 通过选择 200 个(约 6%)高质量的指令遵循数据来训练 InstructionGPT-4,研究者表明可以为多模态大型语言模型使用更少的指令数据来实现更好的对齐。
- 文中提出了一种数据选择器,其使用了一种可解释的简单原则来选取用于微调的高质量多模态指令遵循数据。这种方法力求在数据子集的评估和调整中实现有效性和可移植性。
- 研究者通过实验表明这种简单技术能够很好地应对不同任务。相比于原始的 MiniGPT-4,仅使用 6% 已过滤数据微调得到的 InstructionGPT-4 在多种任务上都取得了更优表现。
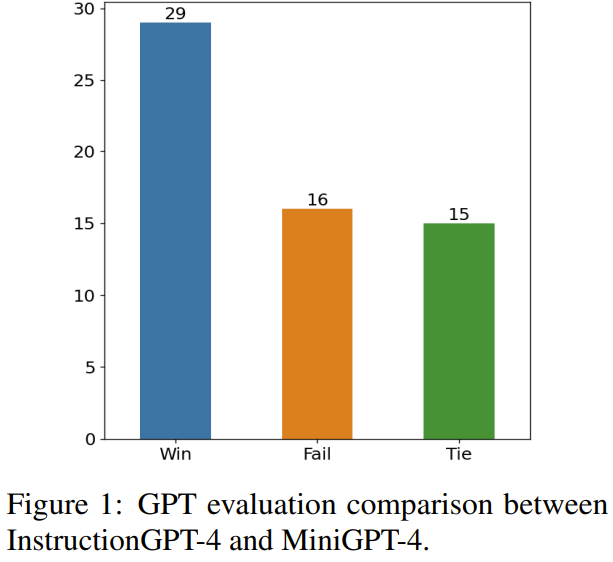
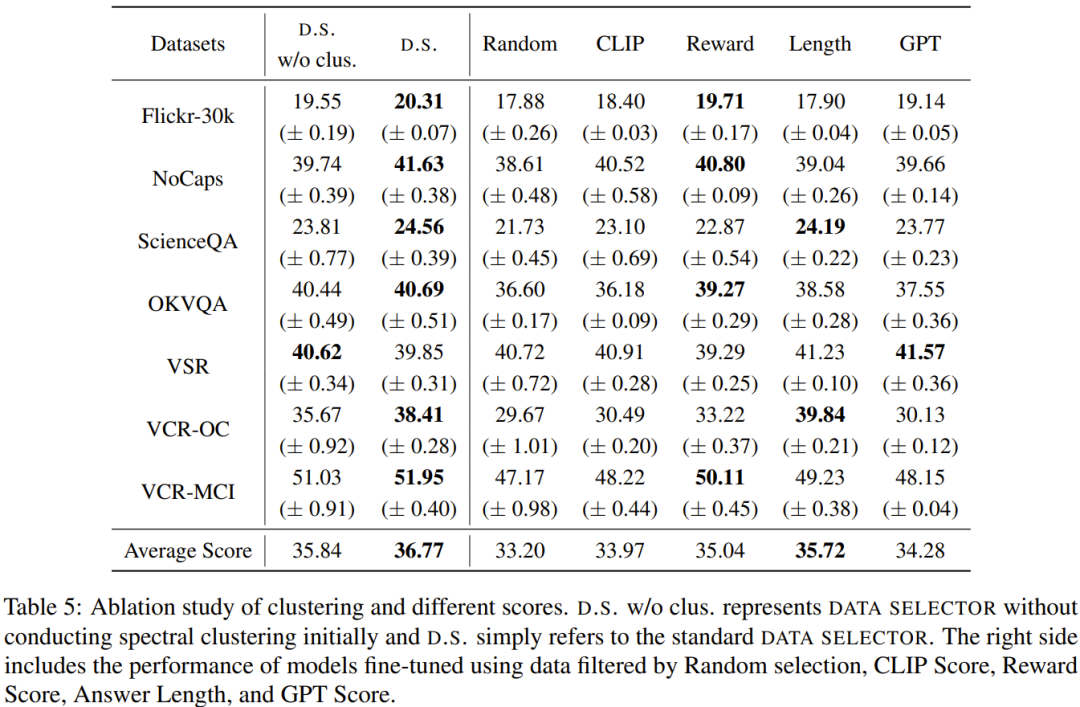
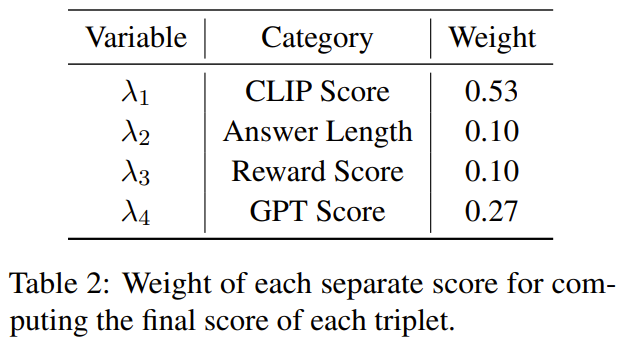
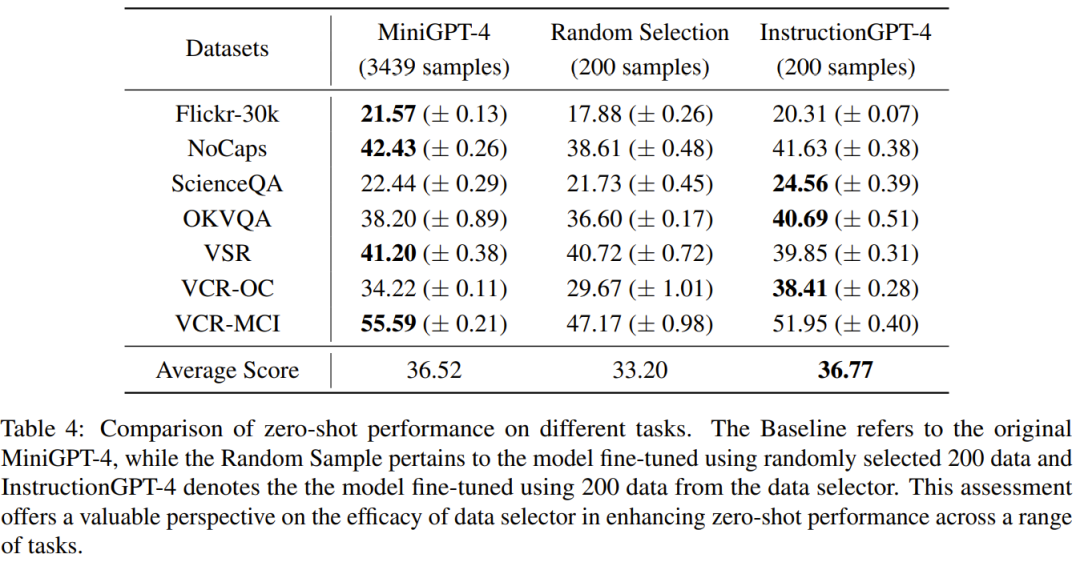
这项研究的目标是提出一种简单且可移植的数据选择器,使其能自动从原始微调数据集中精选出一个子集。为此,研究者定义了一个选取原则,该原则关注的重点是多模态数据集的多样化和质量。下面将简单介绍一下。为了有效地训练 MLLM,选取有用的多模态指令数据是至关重要的。而为了选出最优的指令数据,研究者提出了两大关键原则:多样性和质量。对于多样性,研究者采用的方法是对图像嵌入进行聚类,以将数据分成不同的组别。为了评估质量,研究者采用了一些用于高效评估多模态数据的关键指标。给定一个视觉 - 语言指令数据集和一个预训练 MLLM(如 MiniGPT-4 和 LLaVA),数据选择器的最终目标是识别出一个用于微调的子集并且使得该子集能为预训练 MLLM 带来提升。为了选出这个子集并确保其多样性,研究者首先是使用一个聚类算法将原始数据集分成多个类别。为了确保所选出的多模态指令数据的质量,研究者制定了一套用于评估的指标,如下表 1 所示。表 2 则给出了在计算最终分数时,每个不同分数的权重。表 4 比较了 MiniGPT-4 基准模型、使用随机采样的数据微调得到的 MiniGPT-4 以及使用数据选择器微调得到的 InstructionGPT-4 的表现。可以观察到,InstructionGPT-4 的平均表现是最好的。具体来说,InstructionGPT-4 在 ScienceQA 的表现超过基准模型 2.12%,在 OKVQA 和 VCR-OC 上则分别超过基准模型 2.49% 和 4.19%。此外,InstructionGPT-4 在除 VSR 之外的所有其它任务上都优于用随机样本训练的模型。通过在一系列任务上评估和对比这些模型,可以辨别出它们各自的能力,并确定新提出的数据选择器的效能 —— 数据选择器能有效识别高质量数据。这样的全面分析表明:明智的数据选择可以提升模型在各种不同任务上的零样本性能。LLM 本身存在固有的位置偏见,对此可参阅本站文章《语言模型悄悄偷懒?新研究:上下文太长,模型会略过中间不看》。因此研究者采取了措施来解决这一问题,具体来说就是同时使用两种排布响应的顺序来执行评估,即将 InstructionGPT-4 生成的响应放在 MiniGPT-4 生成的响应之前或之后。为了制定明确的评判标准,他们采用了「赢-平-输」(Win-Tie-Lose)框架:1) 赢:InstructionGPT-4 在两种情况下都赢或赢一次平一次;2) 平:InstructionGPT-4 与 MiniGPT-4 平局两次或赢一次输一次;3) 输:InstructionGPT-4 输两次或输一次平一次。在 60 个问题上,InstructionGPT-4 赢 29 局,输 16 局,其余 15 局平局。这足以证明在响应质量上,InstructionGPT-4 明显优于 MiniGPT-4。表 5 给出了消融实验的分析结果,从中可以看出聚类算法和各种评估分数的重要性。为了深入了解 InstructionGPT-4 在理解视觉输入和生成合理响应方面的能力,研究者还对 InstructionGPT-4 和 MiniGPT-4 的图像理解和对话能力进行了对比评估。该分析基于一个显眼的实例,涉及到对图像的描述以及进一步的理解,结果见表 6。InstructionGPT-4 更擅长提供全面的图像描述和识别图像中有趣的方面。与 MiniGPT-4 相比,InstructionGPT-4 更有能力识别图像中存在的文本。在这里,InstructionGPT-4 能够正确指出图像中有一个短语:Monday, just Monday.
生成的响应放在 MiniGPT-4 生成的响应之前或之后。为了制定明确的评判标准,他们采用了「赢-平-输」(Win-Tie-Lose)框架:1) 赢:InstructionGPT-4 在两种情况下都赢或赢一次平一次;2) 平:InstructionGPT-4 与 MiniGPT-4 平局两次或赢一次输一次;3) 输:InstructionGPT-4 输两次或输一次平一次。在 60 个问题上,InstructionGPT-4 赢 29 局,输 16 局,其余 15 局平局。这足以证明在响应质量上,InstructionGPT-4 明显优于 MiniGPT-4。表 5 给出了消融实验的分析结果,从中可以看出聚类算法和各种评估分数的重要性。为了深入了解 InstructionGPT-4 在理解视觉输入和生成合理响应方面的能力,研究者还对 InstructionGPT-4 和 MiniGPT-4 的图像理解和对话能力进行了对比评估。该分析基于一个显眼的实例,涉及到对图像的描述以及进一步的理解,结果见表 6。InstructionGPT-4 更擅长提供全面的图像描述和识别图像中有趣的方面。与 MiniGPT-4 相比,InstructionGPT-4 更有能力识别图像中存在的文本。在这里,InstructionGPT-4 能够正确指出图像中有一个短语:Monday, just Monday.以上就是精选200条数据后,MiniGPT-4被匹配相同模型的效果超越的详细内容,更多请关注其它相关文章!
# llama
# follow
# 入门
# 澄迈县网站建设批发
# 南平营销推广定制
# 忻州网站建设怎么收费
# 外贸整合营销推广
# 大庆网站建设的步骤
# 嘉兴网站建设工作招聘
# 重庆图文营销推广企业
# 关键词seo排名定制
# seo面试指南
# 中阳哪里有网站推广
# 腾讯
# 两种
# 出了
# 提出了
# 这一
# 超越了
# 高质量
# 多条
# 多模
# 选择器
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
鸿蒙智能座舱的AI大模型革新,引领智能座舱领域的变革吗?
微软 Azure AI 文本转语音服务升级:新增男性声音和扩展语言支持
小艺将具备大模型能力,鸿蒙4加速AI普及之路
生成式人工智能来了,如何保护未成年人? | 社会科学报
全国体育人工智能大会举办,专家聚焦体育人工智能领域人才培养
研究表明 GPT-4 模型具备自我纠错能力,有望推动 AI 代码进一步商业化
特斯拉 Optimus 人形机器人入驻北美门店,帮助提升汽车销量
从数据中心到发电站:人工智能对能源使用的影响
AI生成会议纪要 百度如流升级推出超级助手、智能编码等功能
彬州市第三届青少年机器人创新大赛成功举办
无需标注数据,「3D理解」进入多模态预训练时代!ULIP系列全面开源,刷新SOTA
AI技术加速迭代:周鸿祎视角下的大模型战略
陈根:AI冥想教练为用户提供个性化指导
中科院自研新一代 AI 大模型“紫东太初 2.0”问世
智能客服进入AI 2.0时代 容联云发布语言大模型“赤兔”
Meta发布音频AI模型,仅需2秒片段模拟真人语音
挤爆服务器,北大法律大模型ChatLaw火了:直接告诉你张三怎么判
AI大模型火了!科技巨头纷纷加入,多地政策加码加速落地
微软推出人工智能模型 CoDi,可互动和生成多模态内容
OpenAI 向所有付费 API 用户开放 GPT-4
开创全新虚拟现实体验的Pimax Crystal VR头显
陈根教授:离人形机器人时代还有10年吗?
机器人技能大比拼
贫穷让我预训练
华为盘古AI模型实现秒级全球气象预报时间缩短
构建数字文旅新高地!洛阳涧西区开启元宇宙时代
马斯克:将来机器人比人类多!特斯拉机器人亮相人工智能大会
AI技术改变*,新骗局来袭,*成功率接近100%
360发布认知型通用大模型“360智脑4.0” 全面接入360全家桶
软通动力多项AI创新产品及应用亮相2025世界人工智能大会
关于开展“与AI共创未来”——2025年全国青少年人工智能创新实践活动的通知
央视报道车载人机交互技术!MWC上海魅族表现亮眼,现场热火朝天
昇腾AI & 讯飞星火:深度联手,共话国产大模型“大未来”
B站内测 AI 搜索功能,输入“?”即可体验
如何用AI开创智慧能源新时代?固德威正让能源“通人性”!
五个出色的人工智能应用实例
马斯克嘲讽人工智能:机器学习本质就是统计学
“世界上最像人的机器人”接入 Stable Diffusion ,现场完成作画
实现人工智能和物联网的协同运作
选对AI智能写作软件,让创作游刃有余!
小米又拿下国际比赛第一:AI翻译立功
AI+游戏首度大范围公布实际应用成果,AI全面来临还有多远?
调查显示:实际上没有那么多人在用 ChatGPT
AI人工智能软件,婚纱设计师的必备利器
微软bing聊天推出AI购物工具 可进行比价并查看历史最低价
云深处与昇腾CANN携手合作:开设ROS四足机器狗开发训练营
史玉柱谈AI:国内最缺是计算数学人才,曾给浙大数学系捐五千万
实测 AI 建筑设计软件的自动生成效果图能力
国产医疗企业的人工智能
乐天派AI桌面机器人提供的正能量情绪价值直接拉满,妥妥的治愈系
2024-01-16


 生成的响应放在 MiniGPT-4 生成的响应之前或之后。为了制定明确的评判标准,他们采用了「赢-平-输」(Win-Tie-Lose)框架:
生成的响应放在 MiniGPT-4 生成的响应之前或之后。为了制定明确的评判标准,他们采用了「赢-平-输」(Win-Tie-Lose)框架: